 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloat8@2bits: Entropy Coding Enables Data-Free Model Compression
Jan 30, 2026Post-training compression is currently divided into two contrasting regimes. On the one hand, fast, data-free, and model-agnostic methods (e.g., NF4 or HQQ) offer maximum accessibility but suffer from functional collapse at extreme bit-rates below 4 bits. On the other hand, techniques leveraging calibration data or extensive recovery training achieve superior fidelity but impose high computational constraints and face uncertain robustness under data distribution shifts. We introduce EntQuant, the first framework to unite the advantages of these distinct paradigms. By matching the performance of data-dependent methods with the speed and universality of data-free techniques, EntQuant enables practical utility in the extreme compression regime. Our method decouples numerical precision from storage cost via entropy coding, compressing a 70B parameter model in less than 30 minutes. We demonstrate that EntQuant does not only achieve state-of-the-art results on standard evaluation sets and models, but also retains functional performance on more complex benchmarks with instruction-tuned models, all at modest inference overhead.
Choose Your Model Size: Any Compression by a Single Gradient Descent
Feb 03, 2025



The adoption of Foundation Models in resource-constrained environments remains challenging due to their large size and inference costs. A promising way to overcome these limitations is post-training compression, which aims to balance reduced model size against performance degradation. This work presents Any Compression via Iterative Pruning (ACIP), a novel algorithmic approach to determine a compression-performance trade-off from a single stochastic gradient descent run. To ensure parameter efficiency, we use an SVD-reparametrization of linear layers and iteratively prune their singular values with a sparsity-inducing penalty. The resulting pruning order gives rise to a global parameter ranking that allows us to materialize models of any target size. Importantly, the compressed models exhibit strong predictive downstream performance without the need for costly fine-tuning. We evaluate ACIP on a large selection of open-weight LLMs and tasks, and demonstrate state-of-the-art results compared to existing factorisation-based compression methods. We also show that ACIP seamlessly complements common quantization-based compression techniques.
Interpretable Reinforcement Learning via Neural Additive Models for Inventory Management
Mar 22, 2023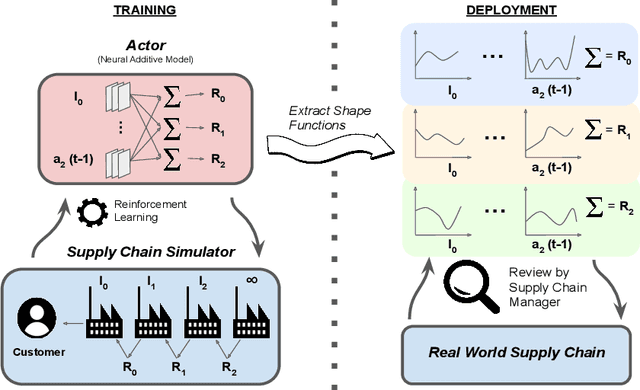
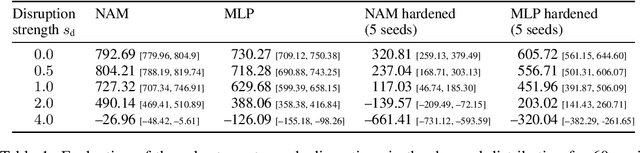
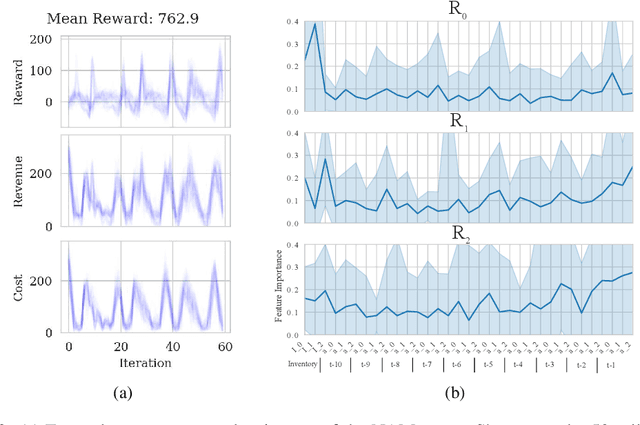
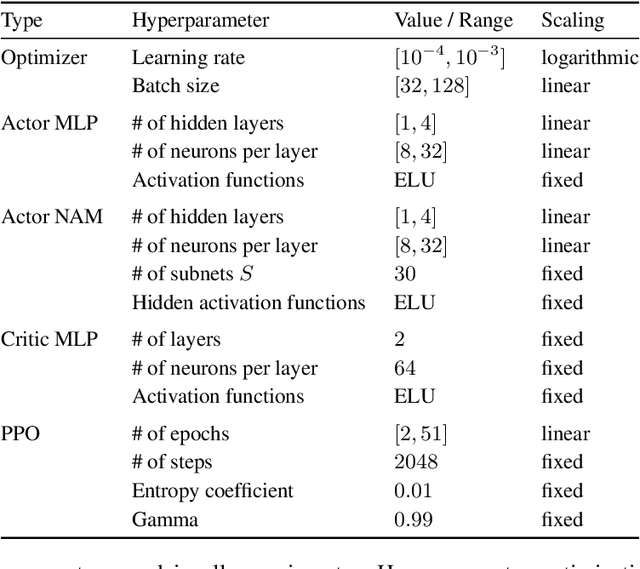
The COVID-19 pandemic has highlighted the importance of supply chains and the role of digital management to react to dynamic changes in the environment. In this work, we focus on developing dynamic inventory ordering policies for a multi-echelon, i.e. multi-stage, supply chain. Traditional inventory optimization methods aim to determine a static reordering policy. Thus, these policies are not able to adjust to dynamic changes such as those observed during the COVID-19 crisis. On the other hand, conventional strategies offer the advantage of being interpretable, which is a crucial feature for supply chain managers in order to communicate decisions to their stakeholders. To address this limitation, we propose an interpretable reinforcement learning approach that aims to be as interpretable as the traditional static policies while being as flexible and environment-agnostic as other deep learning-based reinforcement learning solutions. We propose to use Neural Additive Models as an interpretable dynamic policy of a reinforcement learning agent, showing that this approach is competitive with a standard full connected policy. Finally, we use the interpretability property to gain insights into a complex ordering strategy for a simple, linear three-echelon inventory supply chain.
Marginalising over Stationary Kernels with Bayesian Quadrature
Jun 14, 2021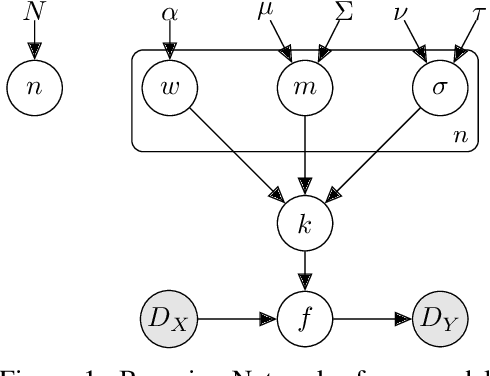

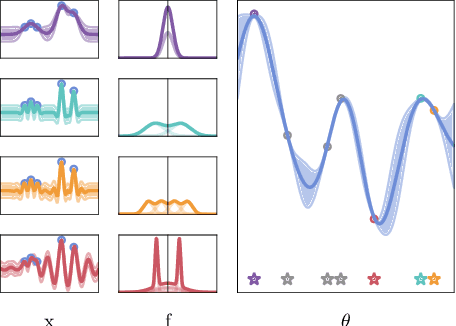

Marginalising over families of Gaussian Process kernels produces flexible model classes with well-calibrated uncertainty estimates. Existing approaches require likelihood evaluations of many kernels, rendering them prohibitively expensive for larger datasets. We propose a Bayesian Quadrature scheme to make this marginalisation more efficient and thereby more practical. Through use of the maximum mean discrepancies between distributions, we define a kernel over kernels that captures invariances between Spectral Mixture (SM) Kernels. Kernel samples are selected by generalising an information-theoretic acquisition function for warped Bayesian Quadrature. We show that our framework achieves more accurate predictions with better calibrated uncertainty than state-of-the-art baselines, especially when given limited (wall-clock) time budgets.
VariBAD: A Very Good Method for Bayes-Adaptive Deep RL via Meta-Learning
Oct 18, 2019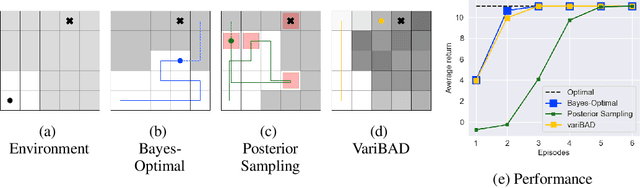
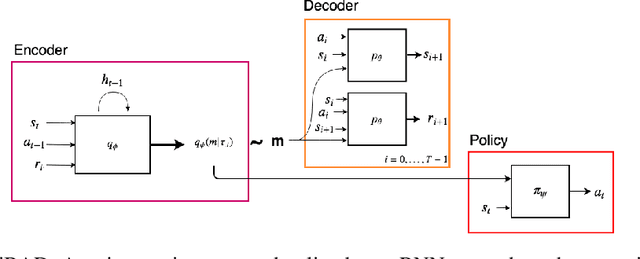
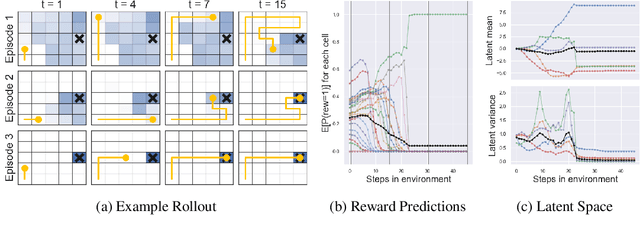
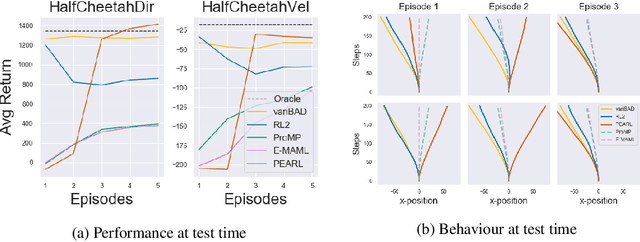
Trading off exploration and exploitation in an unknown environment is key to maximising expected return during learning. A Bayes-optimal policy, which does so optimally, conditions its actions not only on the environment state but on the agent's uncertainty about the environment. Computing a Bayes-optimal policy is however intractable for all but the smallest tasks. In this paper, we introduce variational Bayes-Adaptive Deep RL (variBAD), a way to meta-learn to perform approximate inference in an unknown environment, and incorporate task uncertainty directly during action selection. In a grid-world domain, we illustrate how variBAD performs structured online exploration as a function of task uncertainty. We also evaluate variBAD on MuJoCo domains widely used in meta-RL and show that it achieves higher return during training than existing methods.
Bayesian Optimization for Iterative Learning
Oct 07, 2019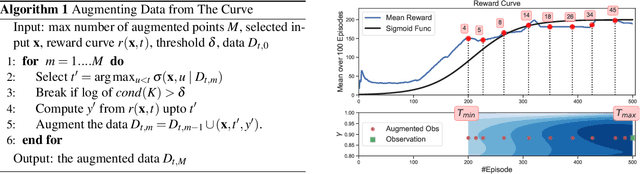
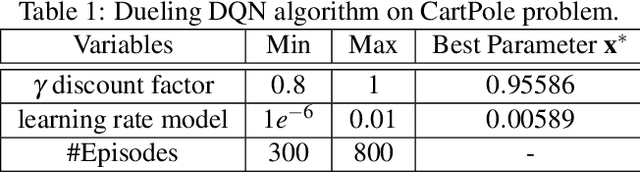


The success of deep (reinforcement) learning systems crucially depends on the correct choice of hyperparameters which are notoriously sensitive and expensive to evaluate. Training these systems typically requires running iterative processes over multiple epochs or episodes. Traditional approaches only consider final performances of a hyperparameter although intermediate information from the learning curve is readily available. In this paper, we present a Bayesian optimization approach which exploits the iterative structure of learning algorithms for efficient hyperparameter tuning. First, we transform each training curve into a numeric score. Second, we selectively augment the data using the auxiliary information from the curve. This augmentation step enables modeling efficiency while preventing the ill-conditioned issue of Gaussian process covariance matrix happened when adding the whole curve. We demonstrate the efficiency of our algorithm by tuning hyperparameters for the training of deep reinforcement learning agents and convolutional neural networks. Our algorithm outperforms all existing baselines in identifying optimal hyperparameters in minimal time.
Active Reinforcement Learning with Monte-Carlo Tree Search
Mar 26, 2018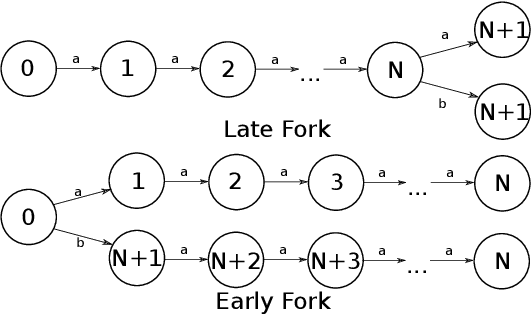
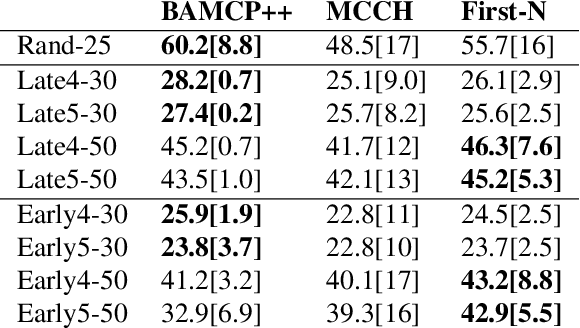
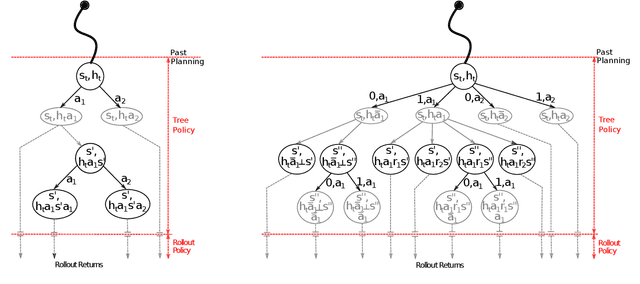
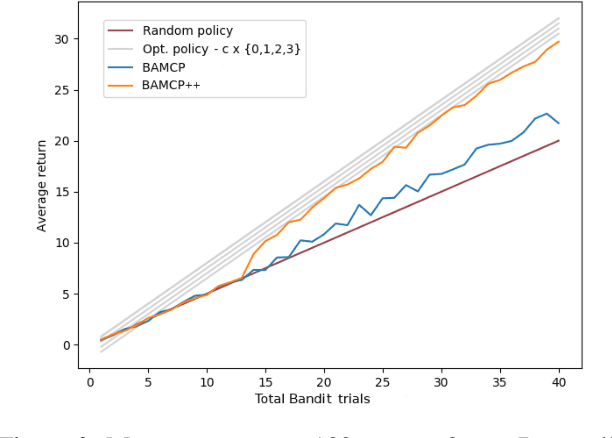
Active Reinforcement Learning (ARL) is a twist on RL where the agent observes reward information only if it pays a cost. This subtle change makes exploration substantially more challenging. Powerful principles in RL like optimism, Thompson sampling, and random exploration do not help with ARL. We relate ARL in tabular environments to Bayes-Adaptive MDPs. We provide an ARL algorithm using Monte-Carlo Tree Search that is asymptotically Bayes optimal. Experimentally, this algorithm is near-optimal on small Bandit problems and MDPs. On larger MDPs it outperforms a Q-learner augmented with specialised heuristics for ARL. By analysing exploration behaviour in detail, we uncover obstacles to scaling up simulation-based algorithms for ARL.