 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Meta-Reinforcement Learning
Jan 19, 2023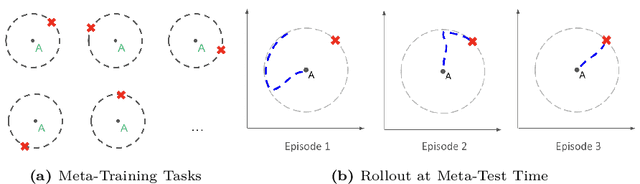
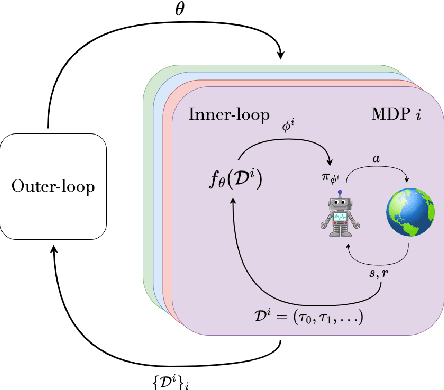

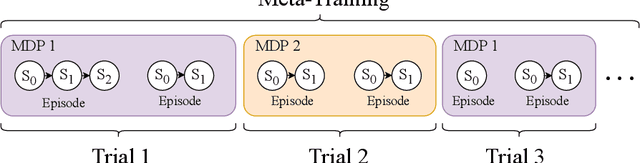
While deep reinforcement learning (RL) has fueled multiple high-profile successes in machine learning, it is held back from more widespread adoption by its often poor data efficiency and the limited generality of the policies it produces. A promising approach for alleviating these limitations is to cast the development of better RL algorithms as a machine learning problem itself in a process called meta-RL. Meta-RL is most commonly studied in a problem setting where, given a distribution of tasks, the goal is to learn a policy that is capable of adapting to any new task from the task distribution with as little data as possible. In this survey, we describe the meta-RL problem setting in detail as well as its major variations. We discuss how, at a high level, meta-RL research can be clustered based on the presence of a task distribution and the learning budget available for each individual task. Using these clusters, we then survey meta-RL algorithms and applications. We conclude by presenting the open problems on the path to making meta-RL part of the standard toolbox for a deep RL practitioner.
Generalized Beliefs for Cooperative AI
Jun 26, 2022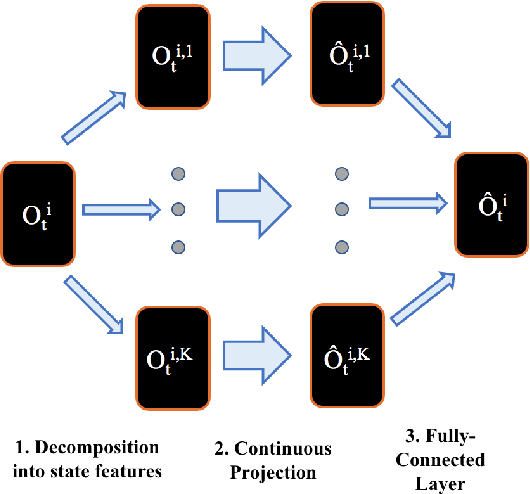
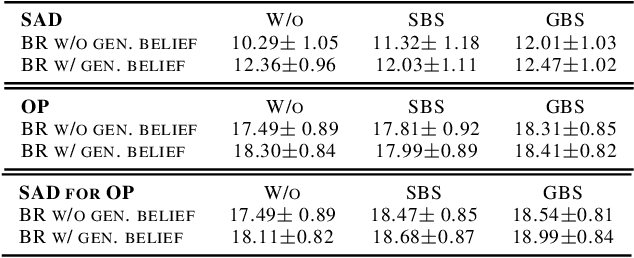
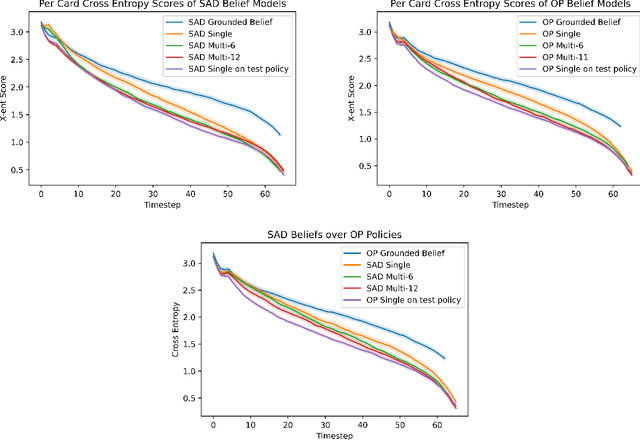

Self-play is a common paradigm for constructing solutions in Markov games that can yield optimal policies in collaborative settings. However, these policies often adopt highly-specialized conventions that make playing with a novel partner difficult. To address this, recent approaches rely on encoding symmetry and convention-awareness into policy training, but these require strong environmental assumptions and can complicate policy training. We therefore propose moving the learning of conventions to the belief space. Specifically, we propose a belief learning model that can maintain beliefs over rollouts of policies not seen at training time, and can thus decode and adapt to novel conventions at test time. We show how to leverage this model for both search and training of a best response over various pools of policies to greatly improve ad-hoc teamplay. We also show how our setup promotes explainability and interpretability of nuanced agent conventions.
On the Practical Consistency of Meta-Reinforcement Learning Algorithms
Dec 01, 2021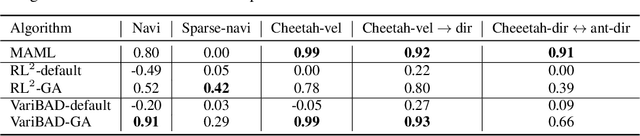
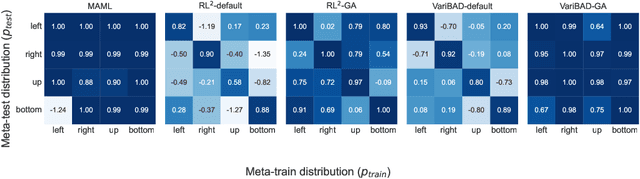
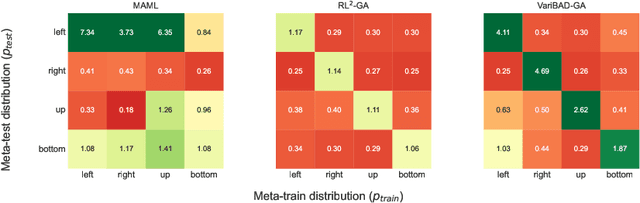

Consistency is the theoretical property of a meta learning algorithm that ensures that, under certain assumptions, it can adapt to any task at test time. An open question is whether and how theoretical consistency translates into practice, in comparison to inconsistent algorithms. In this paper, we empirically investigate this question on a set of representative meta-RL algorithms. We find that theoretically consistent algorithms can indeed usually adapt to out-of-distribution (OOD) tasks, while inconsistent ones cannot, although they can still fail in practice for reasons like poor exploration. We further find that theoretically inconsistent algorithms can be made consistent by continuing to update all agent components on the OOD tasks, and adapt as well or better than originally consistent ones. We conclude that theoretical consistency is indeed a desirable property, and inconsistent meta-RL algorithms can easily be made consistent to enjoy the same benefits.
Implicit Communication as Minimum Entropy Coupling
Jul 17, 2021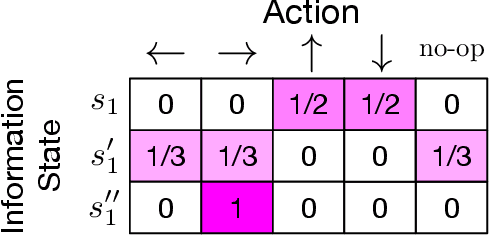
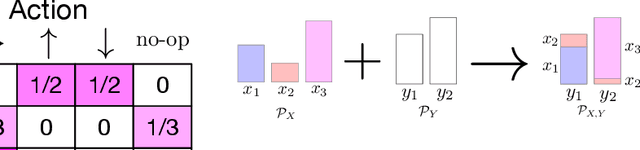

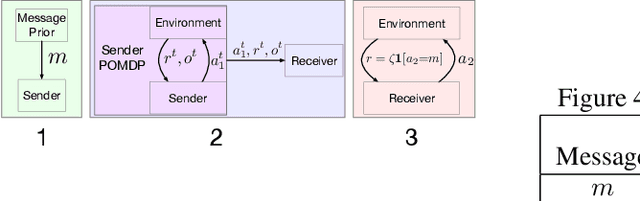
In many common-payoff games, achieving good performance requires players to develop protocols for communicating their private information implicitly -- i.e., using actions that have non-communicative effects on the environment. Multi-agent reinforcement learning practitioners typically approach this problem using independent learning methods in the hope that agents will learn implicit communication as a byproduct of expected return maximization. Unfortunately, independent learning methods are incapable of doing this in many settings. In this work, we isolate the implicit communication problem by identifying a class of partially observable common-payoff games, which we call implicit referential games, whose difficulty can be attributed to implicit communication. Next, we introduce a principled method based on minimum entropy coupling that leverages the structure of implicit referential games, yielding a new perspective on implicit communication. Lastly, we show that this method can discover performant implicit communication protocols in settings with very large spaces of messages.
Optimizing piano practice with a utility-based scaffold
Jun 21, 2021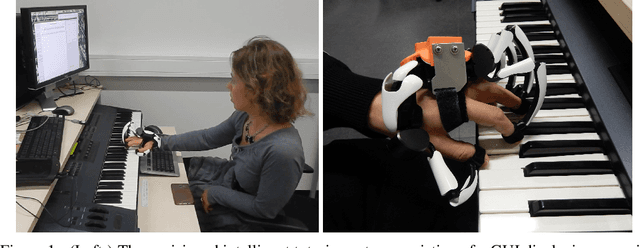
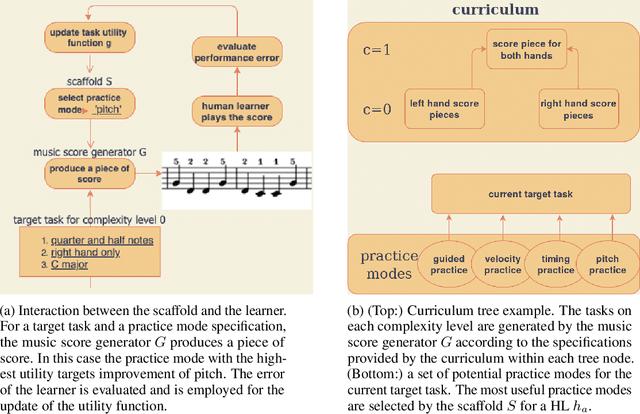
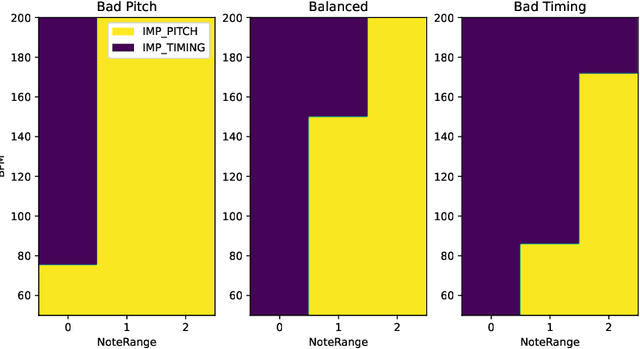
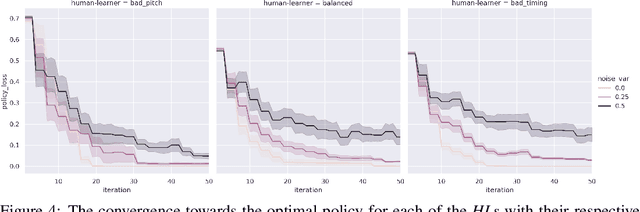
A typical part of learning to play the piano is the progression through a series of practice units that focus on individual dimensions of the skill, such as hand coordination, correct posture, or correct timing. Ideally, a focus on a particular practice method should be made in a way to maximize the learner's progress in learning to play the piano. Because we each learn differently, and because there are many choices for possible piano practice tasks and methods, the set of practice tasks should be dynamically adapted to the human learner. However, having a human teacher guide individual practice is not always feasible since it is time consuming, expensive, and not always available. Instead, we suggest to optimize in the space of practice methods, the so-called practice modes. The proposed optimization process takes into account the skills of the individual learner and their history of learning. In this work we present a modeling framework to guide the human learner through the learning process by choosing practice modes that have the highest expected utility (i.e., improvement in piano playing skill). To this end, we propose a human learner utility model based on a Gaussian process, and exemplify the model training and its application for practice scaffolding on an example of simulated human learners.
A Self-Supervised Auxiliary Loss for Deep RL in Partially Observable Settings
Apr 17, 2021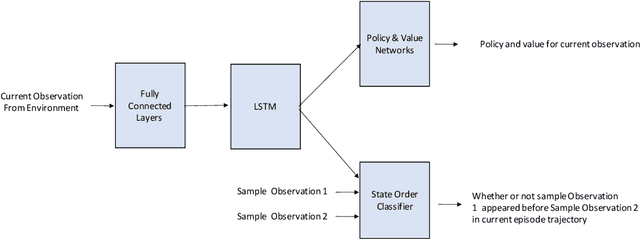


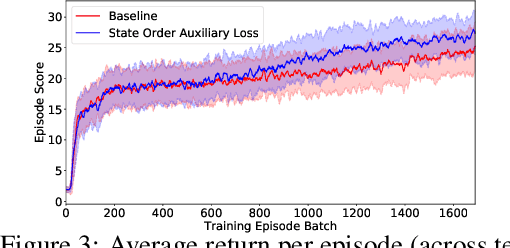
In this work we explore an auxiliary loss useful for reinforcement learning in environments where strong performing agents are required to be able to navigate a spatial environment. The auxiliary loss proposed is to minimize the classification error of a neural network classifier that predicts whether or not a pair of states sampled from the agents current episode trajectory are in order. The classifier takes as input a pair of states as well as the agent's memory. The motivation for this auxiliary loss is that there is a strong correlation with which of a pair of states is more recent in the agents episode trajectory and which of the two states is spatially closer to the agent. Our hypothesis is that learning features to answer this question encourages the agent to learn and internalize in memory representations of states that facilitate spatial reasoning. We tested this auxiliary loss on a navigation task in a gridworld and achieved 9.6% increase in accumulative episode reward compared to a strong baseline approach.
ORBIT: A Real-World Few-Shot Dataset for Teachable Object Recognition
Apr 09, 2021
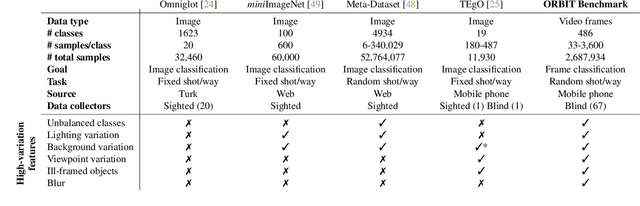
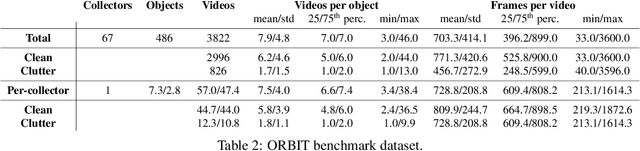
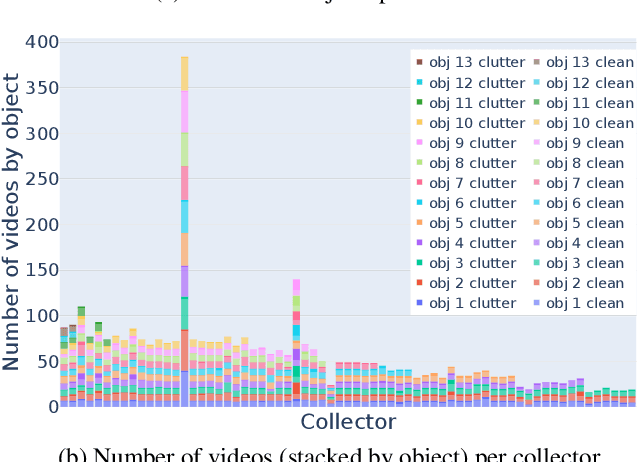
Object recognition has made great advances in the last decade, but predominately still relies on many high-quality training examples per object category. In contrast, learning new objects from only a few examples could enable many impactful applications from robotics to user personalization. Most few-shot learning research, however, has been driven by benchmark datasets that lack the high variation that these applications will face when deployed in the real-world. To close this gap, we present the ORBIT dataset and benchmark, grounded in a real-world application of teachable object recognizers for people who are blind/low vision. The dataset contains 3,822 videos of 486 objects recorded by people who are blind/low-vision on their mobile phones, and the benchmark reflects a realistic, highly challenging recognition problem, providing a rich playground to drive research in robustness to few-shot, high-variation conditions. We set the first state-of-the-art on the benchmark and show that there is massive scope for further innovation, holding the potential to impact a broad range of real-world vision applications including tools for the blind/low-vision community. The dataset is available at https://bit.ly/2OyElCj and the code to run the benchmark at https://bit.ly/39YgiUW.
Deep Interactive Bayesian Reinforcement Learning via Meta-Learning
Jan 11, 2021


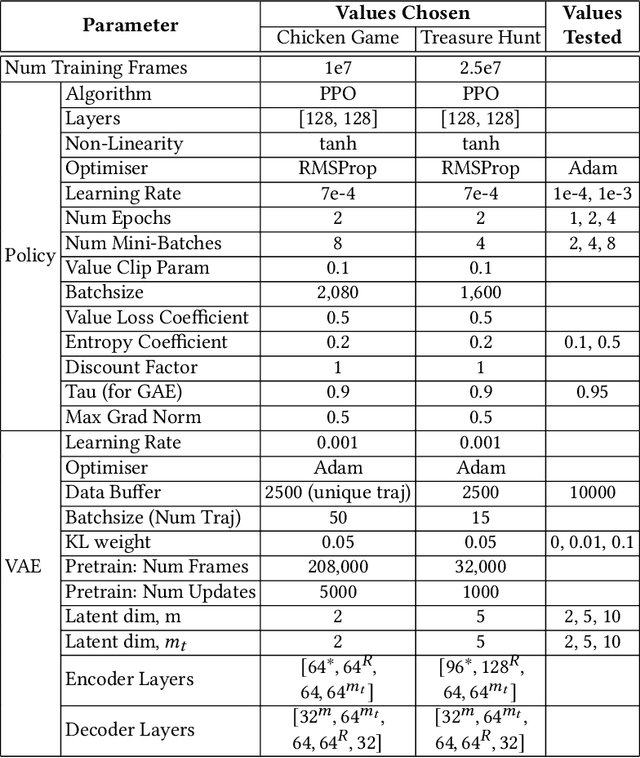
Agents that interact with other agents often do not know a priori what the other agents' strategies are, but have to maximise their own online return while interacting with and learning about others. The optimal adaptive behaviour under uncertainty over the other agents' strategies w.r.t. some prior can in principle be computed using the Interactive Bayesian Reinforcement Learning framework. Unfortunately, doing so is intractable in most settings, and existing approximation methods are restricted to small tasks. To overcome this, we propose to meta-learn approximate belief inference and Bayes-optimal behaviour for a given prior. To model beliefs over other agents, we combine sequential and hierarchical Variational Auto-Encoders, and meta-train this inference model alongside the policy. We show empirically that our approach outperforms existing methods that use a model-free approach, sample from the approximate posterior, maintain memory-free models of others, or do not fully utilise the known structure of the environment.
Exploration in Approximate Hyper-State Space for Meta Reinforcement Learning
Oct 02, 2020
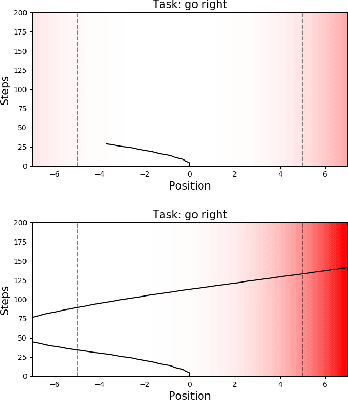

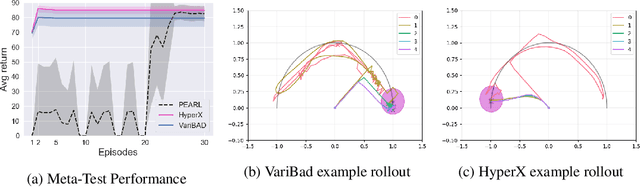
Meta-learning is a powerful tool for learning policies that can adapt efficiently when deployed in new tasks. If however the meta-training tasks have sparse rewards, the need for exploration during meta-training is exacerbated given that the agent has to explore and learn across many tasks. We show that current meta-learning methods can fail catastrophically in such environments. To address this problem, we propose HyperX, a novel method for meta-learning in sparse reward tasks. Using novel reward bonuses for meta-training, we incentivise the agent to explore in approximate hyper-state space, i.e., the joint state and approximate belief space, where the beliefs are over tasks. We show empirically that these bonuses allow an agent to successfully learn to solve sparse reward tasks where existing meta-learning methods fail.
VIABLE: Fast Adaptation via Backpropagating Learned Loss
Nov 29, 2019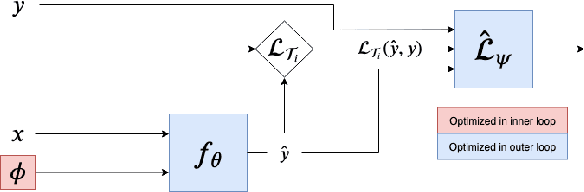
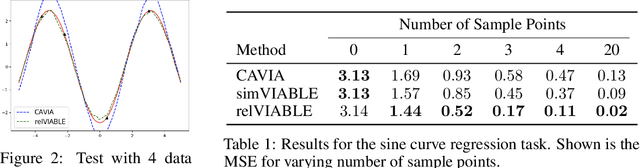
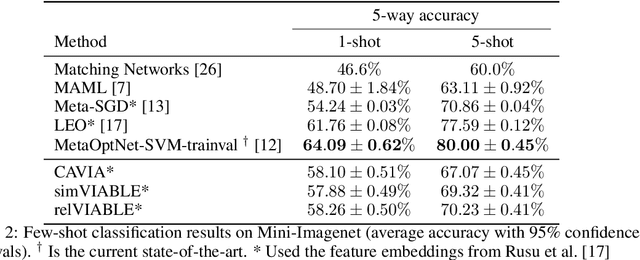
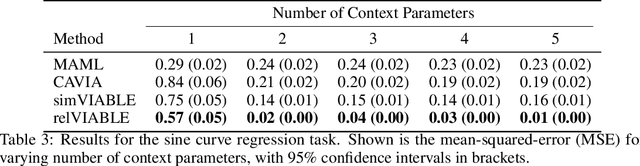
In few-shot learning, typically, the loss function which is applied at test time is the one we are ultimately interested in minimising, such as the mean-squared-error loss for a regression problem. However, given that we have few samples at test time, we argue that the loss function that we are interested in minimising is not necessarily the loss function most suitable for computing gradients in a few-shot setting. We propose VIABLE, a generic meta-learning extension that builds on existing meta-gradient-based methods by learning a differentiable loss function, replacing the pre-defined inner-loop loss function in performing task-specific updates. We show that learning a loss function capable of leveraging relational information between samples reduces underfitting, and significantly improves performance and sample efficiency on a simple regression task. Furthermore, we show VIABLE is scalable by evaluating on the Mini-Imagenet dataset.