 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Confidants: How do People Experience Trust in Emotional Support from Generative AI?
Jan 23, 2026People are increasingly turning to generative AI (e.g., ChatGPT, Gemini, Copilot) for emotional support and companionship. While trust is likely to play a central role in enabling these informal and unsupervised interactions, we still lack an understanding of how people develop and experience it in this context. Seeking to fill this gap, we recruited 24 frequent users of generative AI for emotional support and conducted a qualitative study consisting of diary entries about interactions, transcripts of chats with AI, and in-depth interviews. Our results suggest important novel drivers of trust in this context: familiarity emerging from personalisation, nuanced mental models of generative AI, and awareness of people's control over conversations. Notably, generative AI's homogeneous use of personalised, positive, and persuasive language appears to promote some of these trust-building factors. However, this also seems to discourage other trust-related behaviours, such as remembering that generative AI is a machine trained to converse in human language. We present implications for future research that are likely to become critical as the use of generative AI for emotional support increasingly overlaps with therapeutic work.
Explanatory Debiasing: Involving Domain Experts in the Data Generation Process to Mitigate Representation Bias in AI Systems
Dec 26, 2024Representation bias is one of the most common types of biases in artificial intelligence (AI) systems, causing AI models to perform poorly on underrepresented data segments. Although AI practitioners use various methods to reduce representation bias, their effectiveness is often constrained by insufficient domain knowledge in the debiasing process. To address this gap, this paper introduces a set of generic design guidelines for effectively involving domain experts in representation debiasing. We instantiated our proposed guidelines in a healthcare-focused application and evaluated them through a comprehensive mixed-methods user study with 35 healthcare experts. Our findings show that involving domain experts can reduce representation bias without compromising model accuracy. Based on our findings, we also offer recommendations for developers to build robust debiasing systems guided by our generic design guidelines, ensuring more effective inclusion of domain experts in the debiasing process.
EARN Fairness: Explaining, Asking, Reviewing and Negotiating Artificial Intelligence Fairness Metrics Among Stakeholders
Jul 16, 2024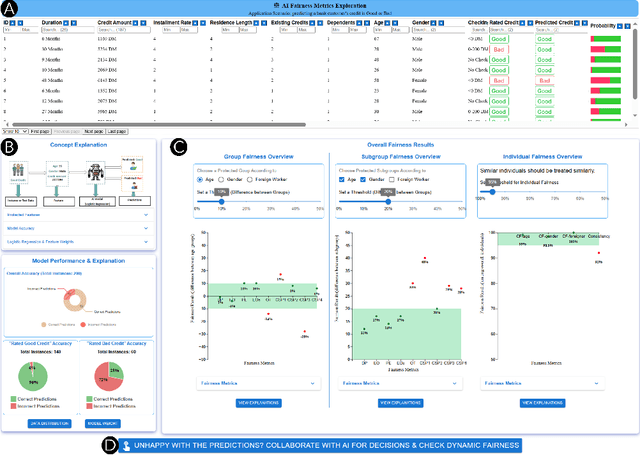

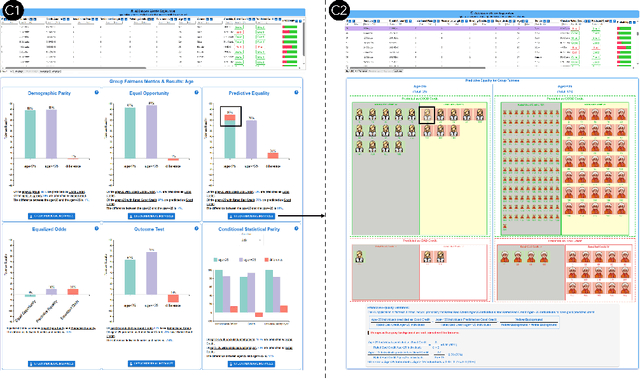
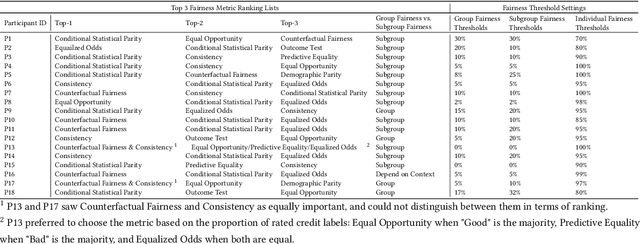
Numerous fairness metrics have been proposed and employed by artificial intelligence (AI) experts to quantitatively measure bias and define fairness in AI models. Recognizing the need to accommodate stakeholders' diverse fairness understandings, efforts are underway to solicit their input. However, conveying AI fairness metrics to stakeholders without AI expertise, capturing their personal preferences, and seeking a collective consensus remain challenging and underexplored. To bridge this gap, we propose a new framework, EARN Fairness, which facilitates collective metric decisions among stakeholders without requiring AI expertise. The framework features an adaptable interactive system and a stakeholder-centered EARN Fairness process to Explain fairness metrics, Ask stakeholders' personal metric preferences, Review metrics collectively, and Negotiate a consensus on metric selection. To gather empirical results, we applied the framework to a credit rating scenario and conducted a user study involving 18 decision subjects without AI knowledge. We identify their personal metric preferences and their acceptable level of unfairness in individual sessions. Subsequently, we uncovered how they reached metric consensus in team sessions. Our work shows that the EARN Fairness framework enables stakeholders to express personal preferences and reach consensus, providing practical guidance for implementing human-centered AI fairness in high-risk contexts. Through this approach, we aim to harmonize fairness expectations of diverse stakeholders, fostering more equitable and inclusive AI fairness.
An Explanatory Model Steering System for Collaboration between Domain Experts and AI
May 17, 2024With the increasing adoption of Artificial Intelligence (AI) systems in high-stake domains, such as healthcare, effective collaboration between domain experts and AI is imperative. To facilitate effective collaboration between domain experts and AI systems, we introduce an Explanatory Model Steering system that allows domain experts to steer prediction models using their domain knowledge. The system includes an explanation dashboard that combines different types of data-centric and model-centric explanations and allows prediction models to be steered through manual and automated data configuration approaches. It allows domain experts to apply their prior knowledge for configuring the underlying training data and refining prediction models. Additionally, our model steering system has been evaluated for a healthcare-focused scenario with 174 healthcare experts through three extensive user studies. Our findings highlight the importance of involving domain experts during model steering, ultimately leading to improved human-AI collaboration.
* Demo paper accepted for ACM UMAP 2024
EXMOS: Explanatory Model Steering Through Multifaceted Explanations and Data Configurations
Feb 01, 2024



Explanations in interactive machine-learning systems facilitate debugging and improving prediction models. However, the effectiveness of various global model-centric and data-centric explanations in aiding domain experts to detect and resolve potential data issues for model improvement remains unexplored. This research investigates the influence of data-centric and model-centric global explanations in systems that support healthcare experts in optimising models through automated and manual data configurations. We conducted quantitative (n=70) and qualitative (n=30) studies with healthcare experts to explore the impact of different explanations on trust, understandability and model improvement. Our results reveal the insufficiency of global model-centric explanations for guiding users during data configuration. Although data-centric explanations enhanced understanding of post-configuration system changes, a hybrid fusion of both explanation types demonstrated the highest effectiveness. Based on our study results, we also present design implications for effective explanation-driven interactive machine-learning systems.
* This is a pre-print version only for early release. Please view the conference published version from ACM CHI 2024 to get the latest version of the paper
Exploring the Impact of Lay User Feedback for Improving AI Fairness
Dec 18, 2023

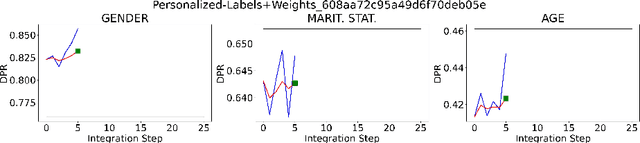

Fairness in AI is a growing concern for high-stakes decision making. Engaging stakeholders, especially lay users, in fair AI development is promising yet overlooked. Recent efforts explore enabling lay users to provide AI fairness-related feedback, but there is still a lack of understanding of how to integrate users' feedback into an AI model and the impacts of doing so. To bridge this gap, we collected feedback from 58 lay users on the fairness of a XGBoost model trained on the Home Credit dataset, and conducted offline experiments to investigate the effects of retraining models on accuracy, and individual and group fairness. Our work contributes baseline results of integrating user fairness feedback in XGBoost, and a dataset and code framework to bootstrap research in engaging stakeholders in AI fairness. Our discussion highlights the challenges of employing user feedback in AI fairness and points the way to a future application area of interactive machine learning.
Explainable Artificial Intelligence (XAI) 2.0: A Manifesto of Open Challenges and Interdisciplinary Research Directions
Oct 30, 2023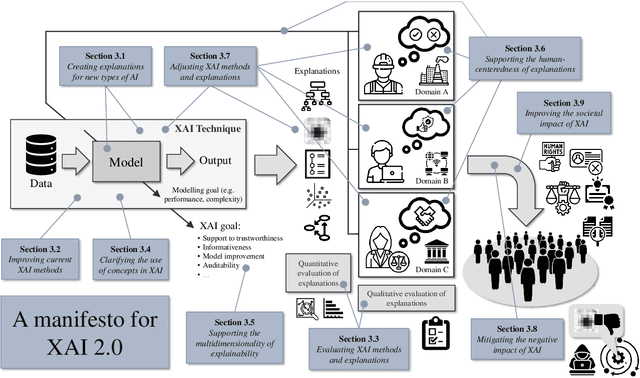
As systems based on opaque Artificial Intelligence (AI) continue to flourish in diverse real-world applications, understanding these black box models has become paramount. In response, Explainable AI (XAI) has emerged as a field of research with practical and ethical benefits across various domains. This paper not only highlights the advancements in XAI and its application in real-world scenarios but also addresses the ongoing challenges within XAI, emphasizing the need for broader perspectives and collaborative efforts. We bring together experts from diverse fields to identify open problems, striving to synchronize research agendas and accelerate XAI in practical applications. By fostering collaborative discussion and interdisciplinary cooperation, we aim to propel XAI forward, contributing to its continued success. Our goal is to put forward a comprehensive proposal for advancing XAI. To achieve this goal, we present a manifesto of 27 open problems categorized into nine categories. These challenges encapsulate the complexities and nuances of XAI and offer a road map for future research. For each problem, we provide promising research directions in the hope of harnessing the collective intelligence of interested stakeholders.
Lessons Learned from EXMOS User Studies: A Technical Report Summarizing Key Takeaways from User Studies Conducted to Evaluate The EXMOS Platform
Oct 03, 2023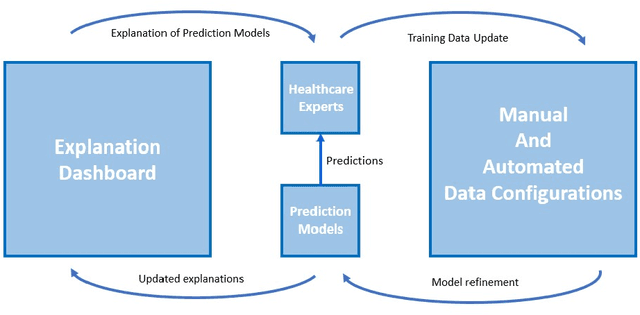
In the realm of interactive machine-learning systems, the provision of explanations serves as a vital aid in the processes of debugging and enhancing prediction models. However, the extent to which various global model-centric and data-centric explanations can effectively assist domain experts in detecting and resolving potential data-related issues for the purpose of model improvement has remained largely unexplored. In this technical report, we summarise the key findings of our two user studies. Our research involved a comprehensive examination of the impact of global explanations rooted in both data-centric and model-centric perspectives within systems designed to support healthcare experts in optimising machine learning models through both automated and manual data configurations. To empirically investigate these dynamics, we conducted two user studies, comprising quantitative analysis involving a sample size of 70 healthcare experts and qualitative assessments involving 30 healthcare experts. These studies were aimed at illuminating the influence of different explanation types on three key dimensions: trust, understandability, and model improvement. Results show that global model-centric explanations alone are insufficient for effectively guiding users during the intricate process of data configuration. In contrast, data-centric explanations exhibited their potential by enhancing the understanding of system changes that occur post-configuration. However, a combination of both showed the highest level of efficacy for fostering trust, improving understandability, and facilitating model enhancement among healthcare experts. We also present essential implications for developing interactive machine-learning systems driven by explanations. These insights can guide the creation of more effective systems that empower domain experts to harness the full potential of machine learning
Human-Centered Responsible Artificial Intelligence: Current & Future Trends
Feb 16, 2023
In recent years, the CHI community has seen significant growth in research on Human-Centered Responsible Artificial Intelligence. While different research communities may use different terminology to discuss similar topics, all of this work is ultimately aimed at developing AI that benefits humanity while being grounded in human rights and ethics, and reducing the potential harms of AI. In this special interest group, we aim to bring together researchers from academia and industry interested in these topics to map current and future research trends to advance this important area of research by fostering collaboration and sharing ideas.
Towards Responsible AI: A Design Space Exploration of Human-Centered Artificial Intelligence User Interfaces to Investigate Fairness
Jun 01, 2022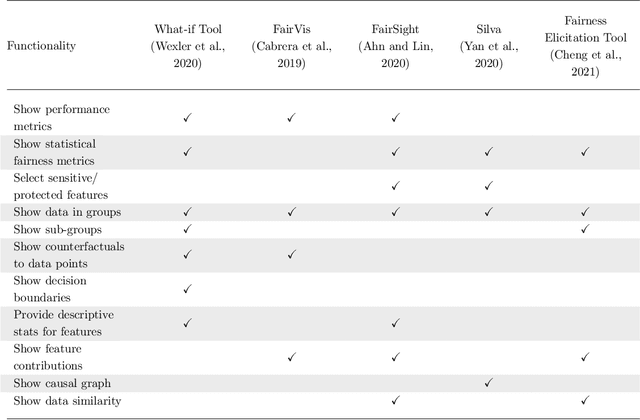
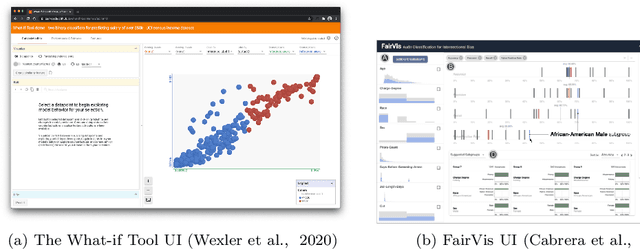
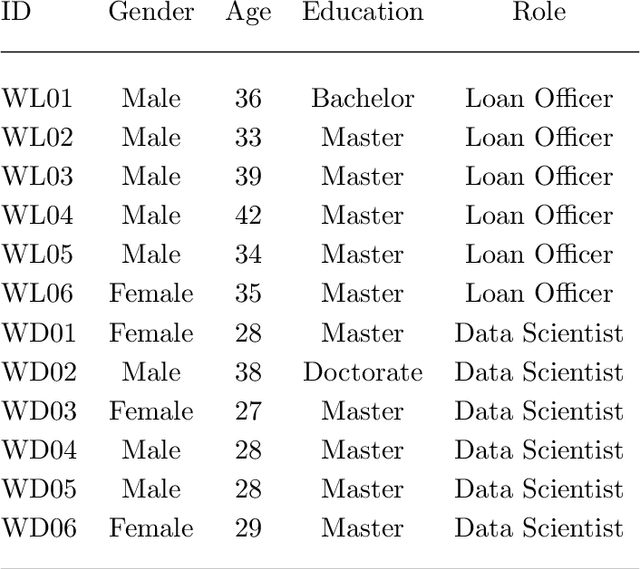
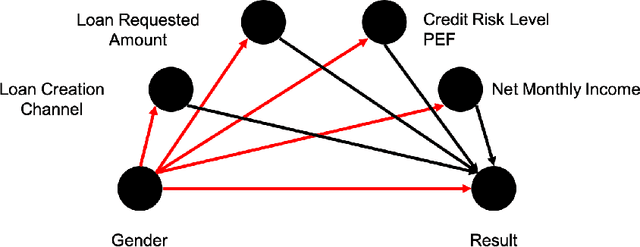
With Artificial intelligence (AI) to aid or automate decision-making advancing rapidly, a particular concern is its fairness. In order to create reliable, safe and trustworthy systems through human-centred artificial intelligence (HCAI) design, recent efforts have produced user interfaces (UIs) for AI experts to investigate the fairness of AI models. In this work, we provide a design space exploration that supports not only data scientists but also domain experts to investigate AI fairness. Using loan applications as an example, we held a series of workshops with loan officers and data scientists to elicit their requirements. We instantiated these requirements into FairHIL, a UI to support human-in-the-loop fairness investigations, and describe how this UI could be generalized to other use cases. We evaluated FairHIL through a think-aloud user study. Our work contributes better designs to investigate an AI model's fairness-and move closer towards responsible AI.
* 44 pages, 17 figures, the draft of a paper on International Journal of Human-Computer Interaction