 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccountability of Generative AI: Exploring a Precautionary Approach for "Artificially Created Nature"
May 12, 2025The rapid development of generative artificial intelligence (AI) technologies raises concerns about the accountability of sociotechnical systems. Current generative AI systems rely on complex mechanisms that make it difficult for even experts to fully trace the reasons behind the outputs. This paper first examines existing research on AI transparency and accountability and argues that transparency is not a sufficient condition for accountability but can contribute to its improvement. We then discuss that if it is not possible to make generative AI transparent, generative AI technology becomes ``artificially created nature'' in a metaphorical sense, and suggest using the precautionary principle approach to consider AI risks. Finally, we propose that a platform for citizen participation is needed to address the risks of generative AI.
EARN Fairness: Explaining, Asking, Reviewing and Negotiating Artificial Intelligence Fairness Metrics Among Stakeholders
Jul 16, 2024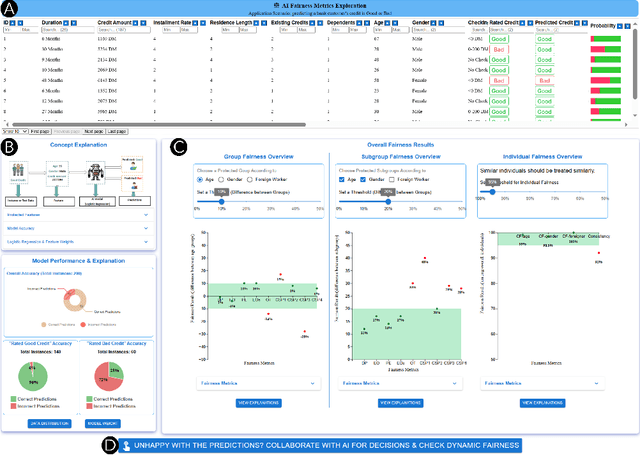

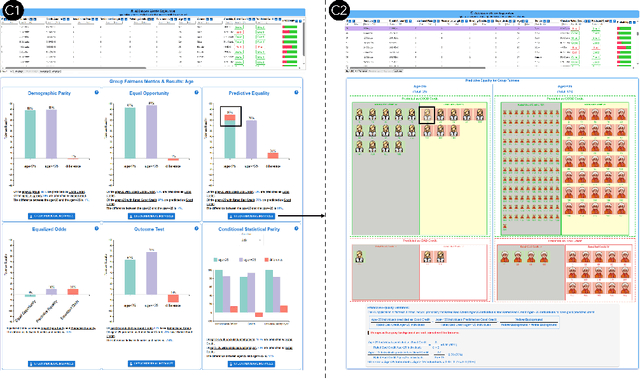
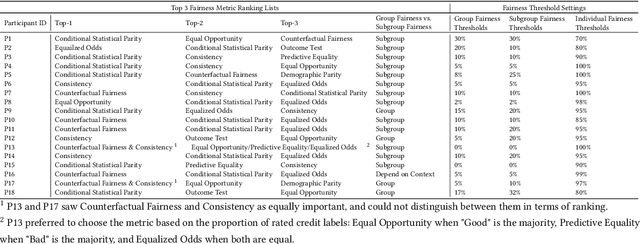
Numerous fairness metrics have been proposed and employed by artificial intelligence (AI) experts to quantitatively measure bias and define fairness in AI models. Recognizing the need to accommodate stakeholders' diverse fairness understandings, efforts are underway to solicit their input. However, conveying AI fairness metrics to stakeholders without AI expertise, capturing their personal preferences, and seeking a collective consensus remain challenging and underexplored. To bridge this gap, we propose a new framework, EARN Fairness, which facilitates collective metric decisions among stakeholders without requiring AI expertise. The framework features an adaptable interactive system and a stakeholder-centered EARN Fairness process to Explain fairness metrics, Ask stakeholders' personal metric preferences, Review metrics collectively, and Negotiate a consensus on metric selection. To gather empirical results, we applied the framework to a credit rating scenario and conducted a user study involving 18 decision subjects without AI knowledge. We identify their personal metric preferences and their acceptable level of unfairness in individual sessions. Subsequently, we uncovered how they reached metric consensus in team sessions. Our work shows that the EARN Fairness framework enables stakeholders to express personal preferences and reach consensus, providing practical guidance for implementing human-centered AI fairness in high-risk contexts. Through this approach, we aim to harmonize fairness expectations of diverse stakeholders, fostering more equitable and inclusive AI fairness.
Exploring the Impact of Lay User Feedback for Improving AI Fairness
Dec 18, 2023

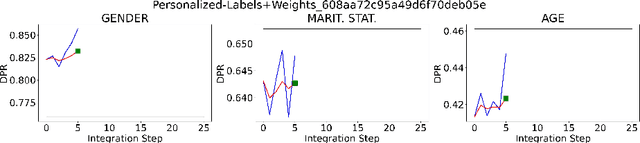

Fairness in AI is a growing concern for high-stakes decision making. Engaging stakeholders, especially lay users, in fair AI development is promising yet overlooked. Recent efforts explore enabling lay users to provide AI fairness-related feedback, but there is still a lack of understanding of how to integrate users' feedback into an AI model and the impacts of doing so. To bridge this gap, we collected feedback from 58 lay users on the fairness of a XGBoost model trained on the Home Credit dataset, and conducted offline experiments to investigate the effects of retraining models on accuracy, and individual and group fairness. Our work contributes baseline results of integrating user fairness feedback in XGBoost, and a dataset and code framework to bootstrap research in engaging stakeholders in AI fairness. Our discussion highlights the challenges of employing user feedback in AI fairness and points the way to a future application area of interactive machine learning.
Towards Responsible AI: A Design Space Exploration of Human-Centered Artificial Intelligence User Interfaces to Investigate Fairness
Jun 01, 2022
With Artificial intelligence (AI) to aid or automate decision-making advancing rapidly, a particular concern is its fairness. In order to create reliable, safe and trustworthy systems through human-centred artificial intelligence (HCAI) design, recent efforts have produced user interfaces (UIs) for AI experts to investigate the fairness of AI models. In this work, we provide a design space exploration that supports not only data scientists but also domain experts to investigate AI fairness. Using loan applications as an example, we held a series of workshops with loan officers and data scientists to elicit their requirements. We instantiated these requirements into FairHIL, a UI to support human-in-the-loop fairness investigations, and describe how this UI could be generalized to other use cases. We evaluated FairHIL through a think-aloud user study. Our work contributes better designs to investigate an AI model's fairness-and move closer towards responsible AI.
* 44 pages, 17 figures, the draft of a paper on International Journal of Human-Computer Interaction
Towards Involving End-users in Interactive Human-in-the-loop AI Fairness
Apr 22, 2022



Ensuring fairness in artificial intelligence (AI) is important to counteract bias and discrimination in far-reaching applications. Recent work has started to investigate how humans judge fairness and how to support machine learning (ML) experts in making their AI models fairer. Drawing inspiration from an Explainable AI (XAI) approach called \emph{explanatory debugging} used in interactive machine learning, our work explores designing interpretable and interactive human-in-the-loop interfaces that allow ordinary end-users without any technical or domain background to identify potential fairness issues and possibly fix them in the context of loan decisions. Through workshops with end-users, we co-designed and implemented a prototype system that allowed end-users to see why predictions were made, and then to change weights on features to "debug" fairness issues. We evaluated the use of this prototype system through an online study. To investigate the implications of diverse human values about fairness around the globe, we also explored how cultural dimensions might play a role in using this prototype. Our results contribute to the design of interfaces to allow end-users to be involved in judging and addressing AI fairness through a human-in-the-loop approach.
One-vs.-One Mitigation of Intersectional Bias: A General Method to Extend Fairness-Aware Binary Classification
Oct 26, 2020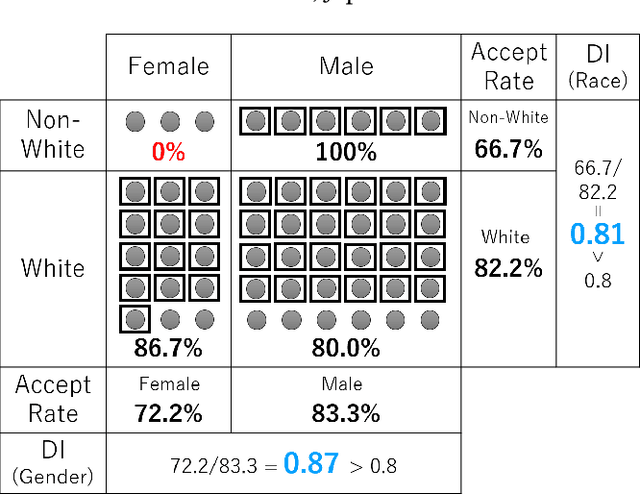
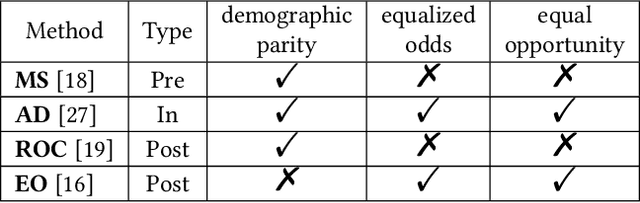
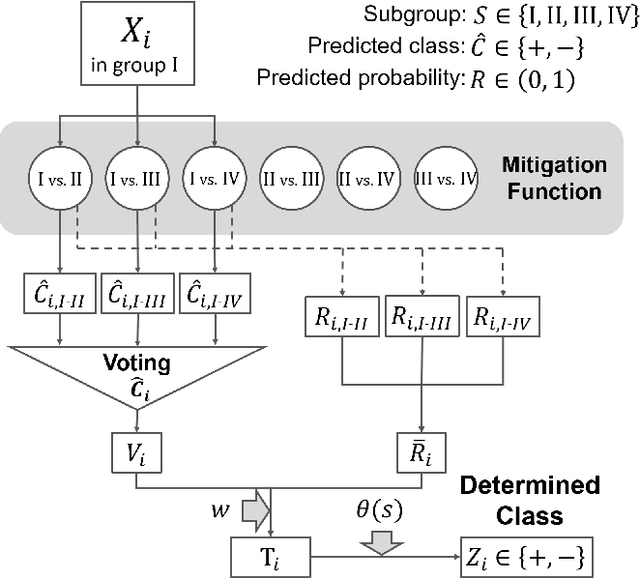

With the widespread adoption of machine learning in the real world, the impact of the discriminatory bias has attracted attention. In recent years, various methods to mitigate the bias have been proposed. However, most of them have not considered intersectional bias, which brings unfair situations where people belonging to specific subgroups of a protected group are treated worse when multiple sensitive attributes are taken into consideration. To mitigate this bias, in this paper, we propose a method called One-vs.-One Mitigation by applying a process of comparison between each pair of subgroups related to sensitive attributes to the fairness-aware machine learning for binary classification. We compare our method and the conventional fairness-aware binary classification methods in comprehensive settings using three approaches (pre-processing, in-processing, and post-processing), six metrics (the ratio and difference of demographic parity, equalized odds, and equal opportunity), and two real-world datasets (Adult and COMPAS). As a result, our method mitigates the intersectional bias much better than conventional methods in all the settings. With the result, we open up the potential of fairness-aware binary classification for solving more realistic problems occurring when there are multiple sensitive attributes.