 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Zero-Shot AI-Generated Image Detection
Mar 23, 2026The rapid progress of text-to-image models has made AI-generated images increasingly realistic, posing significant challenges for accurate detection of generated content. While training-based detectors often suffer from limited generalization to unseen images, training-free approaches offer better robustness, yet struggle to capture subtle discrepancies between real and synthetic images. In this work, we propose a training-free AI-generated image detection method that measures representation sensitivity to structured frequency perturbations, enabling detection of minute manipulations. The proposed method is computationally lightweight, as perturbation generation requires only a single Fourier transform for an input image. As a result, it achieves one to two orders of magnitude faster inference than most training-free detectors.Extensive experiments on challenging benchmarks demonstrate the efficacy of our method over state-of-the-art (SoTA). In particular, on OpenFake benchmark, our method improves AUC by nearly $10\%$ compared to SoTA, while maintaining substantially lower computational cost.
A Statistical Analysis of LLMs' Self-Evaluation Using Proverbs
Oct 22, 2024Large language models (LLMs) such as ChatGPT, GPT-4, Claude-3, and Llama are being integrated across a variety of industries. Despite this rapid proliferation, experts are calling for caution in the interpretation and adoption of LLMs, owing to numerous associated ethical concerns. Research has also uncovered shortcomings in LLMs' reasoning and logical abilities, raising questions on the potential of LLMs as evaluation tools. In this paper, we investigate LLMs' self-evaluation capabilities on a novel proverb reasoning task. We introduce a novel proverb database consisting of 300 proverb pairs that are similar in intent but different in wordings, across topics spanning gender, wisdom, and society. We propose tests to evaluate textual consistencies as well as numerical consistencies across similar proverbs, and demonstrate the effectiveness of our method and dataset in identifying failures in LLMs' self-evaluation which in turn can highlight issues related to gender stereotypes and lack of cultural understanding in LLMs.
Exploring the Impact of Lay User Feedback for Improving AI Fairness
Dec 18, 2023

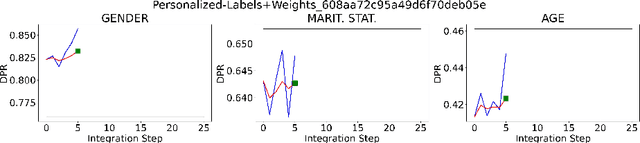

Fairness in AI is a growing concern for high-stakes decision making. Engaging stakeholders, especially lay users, in fair AI development is promising yet overlooked. Recent efforts explore enabling lay users to provide AI fairness-related feedback, but there is still a lack of understanding of how to integrate users' feedback into an AI model and the impacts of doing so. To bridge this gap, we collected feedback from 58 lay users on the fairness of a XGBoost model trained on the Home Credit dataset, and conducted offline experiments to investigate the effects of retraining models on accuracy, and individual and group fairness. Our work contributes baseline results of integrating user fairness feedback in XGBoost, and a dataset and code framework to bootstrap research in engaging stakeholders in AI fairness. Our discussion highlights the challenges of employing user feedback in AI fairness and points the way to a future application area of interactive machine learning.
Fair Oversampling Technique using Heterogeneous Clusters
May 23, 2023Class imbalance and group (e.g., race, gender, and age) imbalance are acknowledged as two reasons in data that hinder the trade-off between fairness and utility of machine learning classifiers. Existing techniques have jointly addressed issues regarding class imbalance and group imbalance by proposing fair over-sampling techniques. Unlike the common oversampling techniques, which only address class imbalance, fair oversampling techniques significantly improve the abovementioned trade-off, as they can also address group imbalance. However, if the size of the original clusters is too small, these techniques may cause classifier overfitting. To address this problem, we herein develop a fair oversampling technique using data from heterogeneous clusters. The proposed technique generates synthetic data that have class-mix features or group-mix features to make classifiers robust to overfitting. Moreover, we develop an interpolation method that can enhance the validity of generated synthetic data by considering the original cluster distribution and data noise. Finally, we conduct experiments on five realistic datasets and three classifiers, and the experimental results demonstrate the effectiveness of the proposed technique in terms of fairness and utility.
A Pre-processing Method for Fairness in Ranking
Oct 29, 2021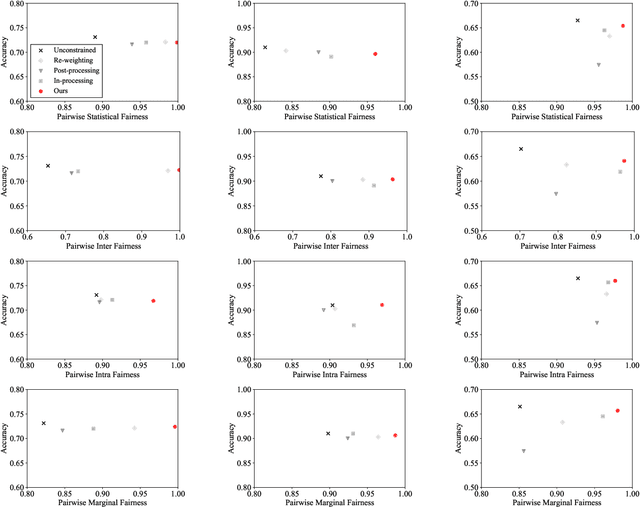
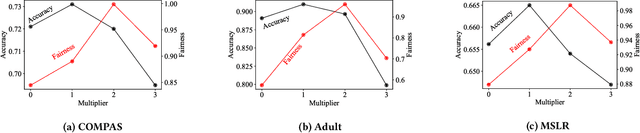
Fair ranking problems arise in many decision-making processes that often necessitate a trade-off between accuracy and fairness. Many existing studies have proposed correction methods such as adding fairness constraints to a ranking model's loss. However, the challenge of correcting the data bias for fair ranking remains, and the trade-off of the ranking models leaves room for improvement. In this paper, we propose a fair ranking framework that evaluates the order of training data in a pairwise manner as well as various fairness measurements in ranking. This study is the first proposal of a pre-processing method that solves fair ranking problems using the pairwise ordering method with our best knowledge. The fair pairwise ordering method is prominent in training the fair ranking models because it ensures that the resulting ranking likely becomes parity across groups. As far as the fairness measurements in ranking are represented as a linear constraint of the ranking models, we proved that the minimization of loss function subject to the constraints is reduced to the closed solution of the minimization problem augmented by weights to training data. This closed solution inspires us to present a practical and stable algorithm that iterates the optimization of weights and model parameters. The empirical results over real-world datasets demonstrated that our method outperforms the existing methods in the trade-off between accuracy and fairness over real-world datasets and various fairness measurements.