 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
Oct 24, 2025



This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.
Diffusion-based Virtual Staining from Polarimetric Mueller Matrix Imaging
Mar 03, 2025


Polarization, as a new optical imaging tool, has been explored to assist in the diagnosis of pathology. Moreover, converting the polarimetric Mueller Matrix (MM) to standardized stained images becomes a promising approach to help pathologists interpret the results. However, existing methods for polarization-based virtual staining are still in the early stage, and the diffusion-based model, which has shown great potential in enhancing the fidelity of the generated images, has not been studied yet. In this paper, a Regulated Bridge Diffusion Model (RBDM) for polarization-based virtual staining is proposed. RBDM utilizes the bidirectional bridge diffusion process to learn the mapping from polarization images to other modalities such as H\&E and fluorescence. And to demonstrate the effectiveness of our model, we conduct the experiment on our manually collected dataset, which consists of 18,000 paired polarization, fluorescence and H\&E images, due to the unavailability of the public dataset. The experiment results show that our model greatly outperforms other benchmark methods. Our dataset and code will be released upon acceptance.
UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping
Dec 03, 2024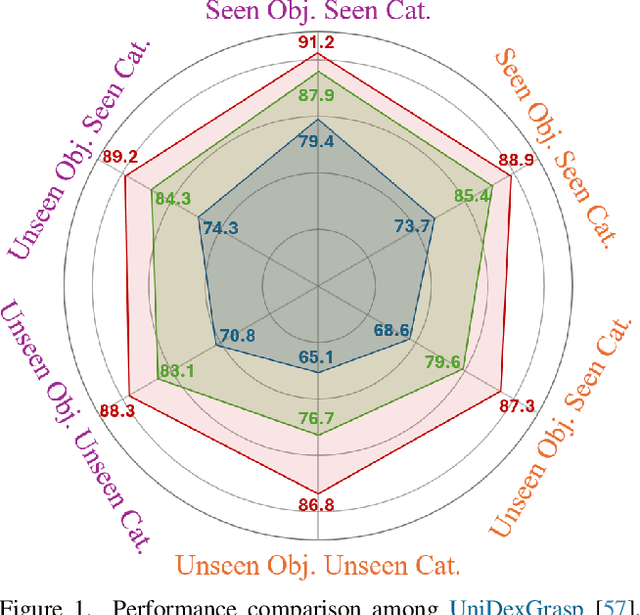

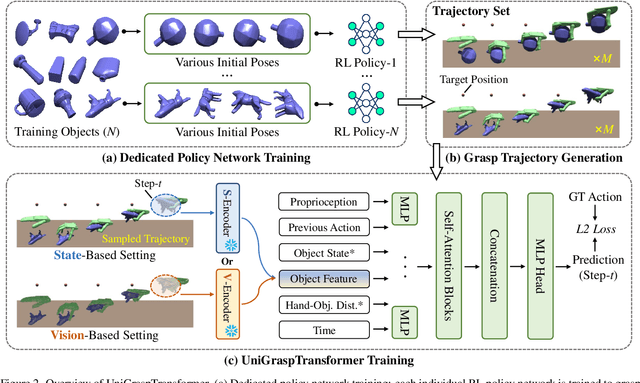

We introduce UniGraspTransformer, a universal Transformer-based network for dexterous robotic grasping that simplifies training while enhancing scalability and performance. Unlike prior methods such as UniDexGrasp++, which require complex, multi-step training pipelines, UniGraspTransformer follows a streamlined process: first, dedicated policy networks are trained for individual objects using reinforcement learning to generate successful grasp trajectories; then, these trajectories are distilled into a single, universal network. Our approach enables UniGraspTransformer to scale effectively, incorporating up to 12 self-attention blocks for handling thousands of objects with diverse poses. Additionally, it generalizes well to both idealized and real-world inputs, evaluated in state-based and vision-based settings. Notably, UniGraspTransformer generates a broader range of grasping poses for objects in various shapes and orientations, resulting in more diverse grasp strategies. Experimental results demonstrate significant improvements over state-of-the-art, UniDexGrasp++, across various object categories, achieving success rate gains of 3.5%, 7.7%, and 10.1% on seen objects, unseen objects within seen categories, and completely unseen objects, respectively, in the vision-based setting. Project page: https://dexhand.github.io/UniGraspTransformer.
CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation
Nov 29, 2024



The advancement of large Vision-Language-Action (VLA) models has significantly improved robotic manipulation in terms of language-guided task execution and generalization to unseen scenarios. While existing VLAs adapted from pretrained large Vision-Language-Models (VLM) have demonstrated promising generalizability, their task performance is still unsatisfactory as indicated by the low tasks success rates in different environments. In this paper, we present a new advanced VLA architecture derived from VLM. Unlike previous works that directly repurpose VLM for action prediction by simple action quantization, we propose a omponentized VLA architecture that has a specialized action module conditioned on VLM output. We systematically study the design of the action module and demonstrates the strong performance enhancement with diffusion action transformers for action sequence modeling, as well as their favorable scaling behaviors. We also conduct comprehensive experiments and ablation studies to evaluate the efficacy of our models with varied designs. The evaluation on 5 robot embodiments in simulation and real work shows that our model not only significantly surpasses existing VLAs in task performance and but also exhibits remarkable adaptation to new robots and generalization to unseen objects and backgrounds. It exceeds the average success rates of OpenVLA which has similar model size (7B) with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the large RT-2-X model (55B) by 18% absolute success rates in simulation. Code and models can be found on our project page (https://cogact.github.io/).
Adversarial Prompt Distillation for Vision-Language Models
Nov 22, 2024Large pre-trained Vision-Language Models (VLMs) such as Contrastive Language-Image Pre-Training (CLIP) have been shown to be susceptible to adversarial attacks, raising concerns about their deployment in safety-critical scenarios like autonomous driving and medical diagnosis. One promising approach for improving the robustness of pre-trained VLMs is Adversarial Prompt Tuning (APT), which combines adversarial training with prompt tuning. However, existing APT methods are mostly single-modal methods that design prompt(s) for only the visual or textual modality, limiting their effectiveness in either robustness or clean accuracy. In this work, we propose a novel method called Adversarial Prompt Distillation (APD) that combines APT with knowledge distillation to boost the adversarial robustness of CLIP. Specifically, APD is a bimodal method that adds prompts for both the visual and textual modalities while leveraging a cleanly pre-trained teacher CLIP model to distill and boost the performance of the student CLIP model on downstream tasks. Extensive experiments on multiple benchmark datasets demonstrate the superiority of our APD over the current state-of-the-art APT methods in terms of both natural and adversarial performances. The effectiveness of our APD method validates the possibility of using a non-robust teacher to improve the generalization and robustness of VLMs.
BlueSuffix: Reinforced Blue Teaming for Vision-Language Models Against Jailbreak Attacks
Oct 28, 2024



Despite their superb multimodal capabilities, Vision-Language Models (VLMs) have been shown to be vulnerable to jailbreak attacks, which are inference-time attacks that induce the model to output harmful responses with tricky prompts. It is thus essential to defend VLMs against potential jailbreaks for their trustworthy deployment in real-world applications. In this work, we focus on black-box defense for VLMs against jailbreak attacks. Existing black-box defense methods are either unimodal or bimodal. Unimodal methods enhance either the vision or language module of the VLM, while bimodal methods robustify the model through text-image representation realignment. However, these methods suffer from two limitations: 1) they fail to fully exploit the cross-modal information, or 2) they degrade the model performance on benign inputs. To address these limitations, we propose a novel blue-team method BlueSuffix that defends the black-box target VLM against jailbreak attacks without compromising its performance. BlueSuffix includes three key components: 1) a visual purifier against jailbreak images, 2) a textual purifier against jailbreak texts, and 3) a blue-team suffix generator fine-tuned via reinforcement learning for enhancing cross-modal robustness. We empirically show on three VLMs (LLaVA, MiniGPT-4, and Gemini) and two safety benchmarks (MM-SafetyBench and RedTeam-2K) that BlueSuffix outperforms the baseline defenses by a significant margin. Our BlueSuffix opens up a promising direction for defending VLMs against jailbreak attacks.
PathInsight: Instruction Tuning of Multimodal Datasets and Models for Intelligence Assisted Diagnosis in Histopathology
Aug 13, 2024



Pathological diagnosis remains the definitive standard for identifying tumors. The rise of multimodal large models has simplified the process of integrating image analysis with textual descriptions. Despite this advancement, the substantial costs associated with training and deploying these complex multimodal models, together with a scarcity of high-quality training datasets, create a significant divide between cutting-edge technology and its application in the clinical setting. We had meticulously compiled a dataset of approximately 45,000 cases, covering over 6 different tasks, including the classification of organ tissues, generating pathology report descriptions, and addressing pathology-related questions and answers. We have fine-tuned multimodal large models, specifically LLaVA, Qwen-VL, InternLM, with this dataset to enhance instruction-based performance. We conducted a qualitative assessment of the capabilities of the base model and the fine-tuned model in performing image captioning and classification tasks on the specific dataset. The evaluation results demonstrate that the fine-tuned model exhibits proficiency in addressing typical pathological questions. We hope that by making both our models and datasets publicly available, they can be valuable to the medical and research communities.
EARN Fairness: Explaining, Asking, Reviewing and Negotiating Artificial Intelligence Fairness Metrics Among Stakeholders
Jul 16, 2024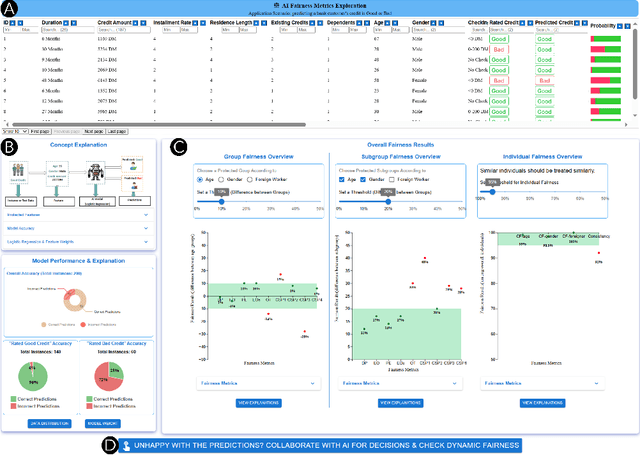

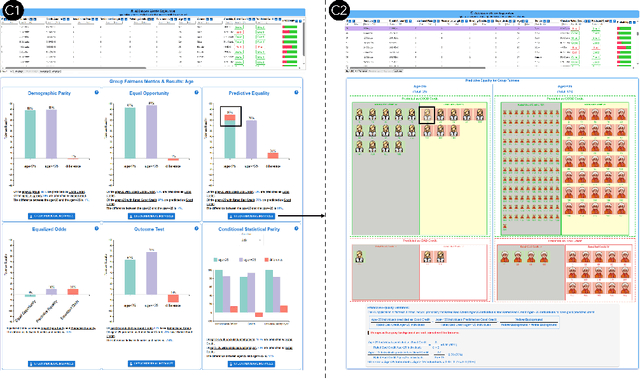
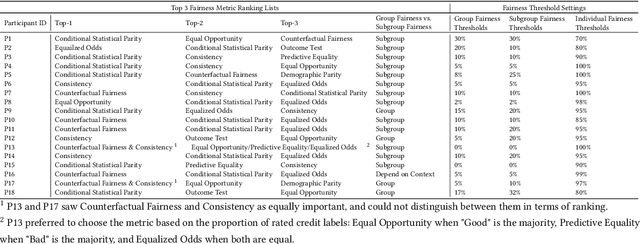
Numerous fairness metrics have been proposed and employed by artificial intelligence (AI) experts to quantitatively measure bias and define fairness in AI models. Recognizing the need to accommodate stakeholders' diverse fairness understandings, efforts are underway to solicit their input. However, conveying AI fairness metrics to stakeholders without AI expertise, capturing their personal preferences, and seeking a collective consensus remain challenging and underexplored. To bridge this gap, we propose a new framework, EARN Fairness, which facilitates collective metric decisions among stakeholders without requiring AI expertise. The framework features an adaptable interactive system and a stakeholder-centered EARN Fairness process to Explain fairness metrics, Ask stakeholders' personal metric preferences, Review metrics collectively, and Negotiate a consensus on metric selection. To gather empirical results, we applied the framework to a credit rating scenario and conducted a user study involving 18 decision subjects without AI knowledge. We identify their personal metric preferences and their acceptable level of unfairness in individual sessions. Subsequently, we uncovered how they reached metric consensus in team sessions. Our work shows that the EARN Fairness framework enables stakeholders to express personal preferences and reach consensus, providing practical guidance for implementing human-centered AI fairness in high-risk contexts. Through this approach, we aim to harmonize fairness expectations of diverse stakeholders, fostering more equitable and inclusive AI fairness.
MiM: Mask in Mask Self-Supervised Pre-Training for 3D Medical Image Analysis
Apr 24, 2024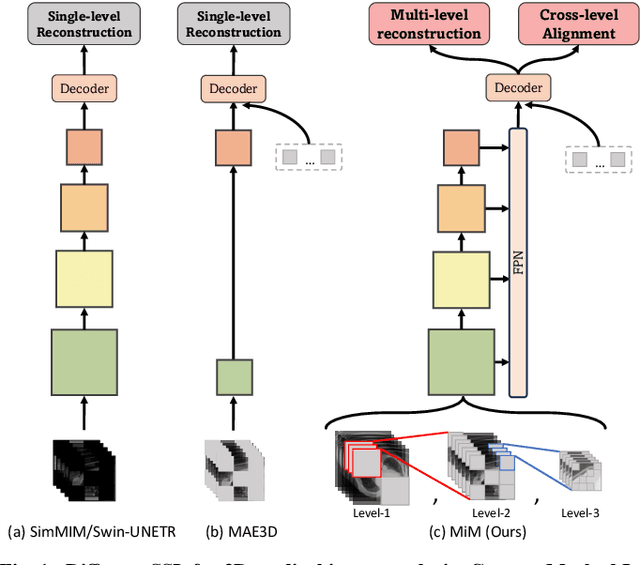
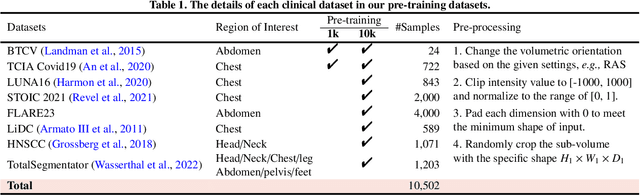
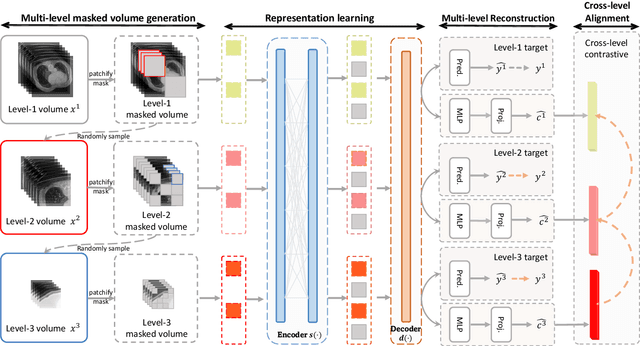
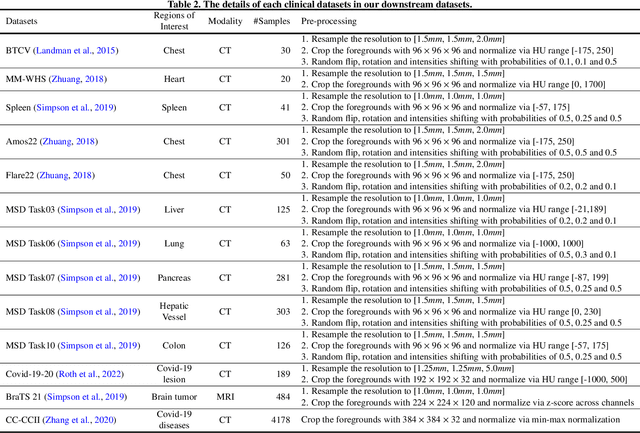
The Vision Transformer (ViT) has demonstrated remarkable performance in Self-Supervised Learning (SSL) for 3D medical image analysis. Mask AutoEncoder (MAE) for feature pre-training can further unleash the potential of ViT on various medical vision tasks. However, due to large spatial sizes with much higher dimensions of 3D medical images, the lack of hierarchical design for MAE may hinder the performance of downstream tasks. In this paper, we propose a novel \textit{Mask in Mask (MiM)} pre-training framework for 3D medical images, which aims to advance MAE by learning discriminative representation from hierarchical visual tokens across varying scales. We introduce multiple levels of granularity for masked inputs from the volume, which are then reconstructed simultaneously ranging at both fine and coarse levels. Additionally, a cross-level alignment mechanism is applied to adjacent level volumes to enforce anatomical similarity hierarchically. Furthermore, we adopt a hybrid backbone to enhance the hierarchical representation learning efficiently during the pre-training. MiM was pre-trained on a large scale of available 3D volumetric images, \textit{i.e.,} Computed Tomography (CT) images containing various body parts. Extensive experiments on thirteen public datasets demonstrate the superiority of MiM over other SSL methods in organ/lesion/tumor segmentation and disease classification. We further scale up the MiM to large pre-training datasets with more than 10k volumes, showing that large-scale pre-training can further enhance the performance of downstream tasks. The improvement also concluded that the research community should pay more attention to the scale of the pre-training dataset towards the healthcare foundation model for 3D medical images.
Rethinking Generative Large Language Model Evaluation for Semantic Comprehension
Mar 12, 2024Despite their sophisticated capabilities, large language models (LLMs) encounter a major hurdle in effective assessment. This paper first revisits the prevalent evaluation method-multiple choice question answering (MCQA), which allows for straightforward accuracy measurement. Through a comprehensive evaluation of 24 models across 11 benchmarks, we highlight several potential drawbacks of MCQA, for instance, the inconsistency between the MCQA evaluation and the generation of open-ended responses in practical scenarios. In response, we introduce an RWQ-Elo rating system, engaging 24 LLMs such as GPT-4, GPT-3.5, Google-Gemini-Pro and LLaMA-1/-2, in a two-player competitive format, with GPT-4 serving as the judge. Each LLM receives an Elo rating thereafter. This system is designed to mirror real-world usage, and for this purpose, we have compiled a new benchmark called ``Real-world questions'' (RWQ), comprising 20,772 authentic user inquiries. Additionally, we thoroughly analyze the characteristics of our system and compare it with prior leaderboards like AlpacaEval and MT-Bench. Our analysis reveals the stability of our RWQ-Elo system, the feasibility of registering new models, and its potential to reshape LLM leaderboards.