 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMED-COPILOT: A Medical Assistant Powered by GraphRAG and Similar Patient Case Retrieval
Feb 28, 2026Clinical decision-making requires synthesizing heterogeneous evidence, including patient histories, clinical guidelines, and trajectories of comparable cases. While large language models (LLMs) offer strong reasoning capabilities, they remain prone to hallucinations and struggle to integrate long, structured medical documents. We present MED-COPILOT, an interactive clinical decision-support system designed for clinicians and medical trainees, which combines guideline-grounded GraphRAG retrieval with hybrid semantic-keyword similar-patient retrieval to support transparent and evidence-aware clinical reasoning. The system builds a structured knowledge graph from WHO and NICE guidelines, applies community-level summarization for efficient retrieval, and maintains a 36,000-case similar-patient database derived from SOAP-normalized MIMIC-IV notes and Synthea-generated records. We evaluate our framework on clinical note completion and medical question answering, and demonstrate that it consistently outperforms parametric LLM baselines and standard RAG, improving both generation fidelity and clinical reasoning accuracy. The full system is available at https://huggingface.co/spaces/Cryo3978/Med_GraphRAG , enabling users to inspect retrieved evidence, visualize token-level similarity contributions, and conduct guided follow-up analysis. Our results demonstrate a practical and interpretable approach to integrating structured guideline knowledge with patient-level analogical evidence for clinical LLMs.
Versatile Reservoir Computing for Heterogeneous Complex Networks
May 21, 2025A new machine learning scheme, termed versatile reservoir computing, is proposed for sustaining the dynamics of heterogeneous complex networks. We show that a single, small-scale reservoir computer trained on time series from a subset of elements is able to replicate the dynamics of any element in a large-scale complex network, though the elements are of different intrinsic parameters and connectivities. Furthermore, by substituting failed elements with the trained machine, we demonstrate that the collective dynamics of the network can be preserved accurately over a finite time horizon. The capability and effectiveness of the proposed scheme are validated on three representative network models: a homogeneous complex network of non-identical phase oscillators, a heterogeneous complex network of non-identical phase oscillators, and a heterogeneous complex network of non-identical chaotic oscillators.
Edge-Cloud Collaborative Computing on Distributed Intelligence and Model Optimization: A Survey
May 03, 2025



Edge-cloud collaborative computing (ECCC) has emerged as a pivotal paradigm for addressing the computational demands of modern intelligent applications, integrating cloud resources with edge devices to enable efficient, low-latency processing. Recent advancements in AI, particularly deep learning and large language models (LLMs), have dramatically enhanced the capabilities of these distributed systems, yet introduce significant challenges in model deployment and resource management. In this survey, we comprehensive examine the intersection of distributed intelligence and model optimization within edge-cloud environments, providing a structured tutorial on fundamental architectures, enabling technologies, and emerging applications. Additionally, we systematically analyze model optimization approaches, including compression, adaptation, and neural architecture search, alongside AI-driven resource management strategies that balance performance, energy efficiency, and latency requirements. We further explore critical aspects of privacy protection and security enhancement within ECCC systems and examines practical deployments through diverse applications, spanning autonomous driving, healthcare, and industrial automation. Performance analysis and benchmarking techniques are also thoroughly explored to establish evaluation standards for these complex systems. Furthermore, the review identifies critical research directions including LLMs deployment, 6G integration, neuromorphic computing, and quantum computing, offering a roadmap for addressing persistent challenges in heterogeneity management, real-time processing, and scalability. By bridging theoretical advancements and practical deployments, this survey offers researchers and practitioners a holistic perspective on leveraging AI to optimize distributed computing environments, fostering innovation in next-generation intelligent systems.
The Role of Visual Modality in Multimodal Mathematical Reasoning: Challenges and Insights
Mar 06, 2025Recent research has increasingly focused on multimodal mathematical reasoning, particularly emphasizing the creation of relevant datasets and benchmarks. Despite this, the role of visual information in reasoning has been underexplored. Our findings show that existing multimodal mathematical models minimally leverage visual information, and model performance remains largely unaffected by changes to or removal of images in the dataset. We attribute this to the dominance of textual information and answer options that inadvertently guide the model to correct answers. To improve evaluation methods, we introduce the HC-M3D dataset, specifically designed to require image reliance for problem-solving and to challenge models with similar, yet distinct, images that change the correct answer. In testing leading models, their failure to detect these subtle visual differences suggests limitations in current visual perception capabilities. Additionally, we observe that the common approach of improving general VQA capabilities by combining various types of image encoders does not contribute to math reasoning performance. This finding also presents a challenge to enhancing visual reliance during math reasoning. Our benchmark and code would be available at \href{https://github.com/Yufang-Liu/visual_modality_role}{https://github.com/Yufang-Liu/visual\_modality\_role}.
Diffusion-based Virtual Staining from Polarimetric Mueller Matrix Imaging
Mar 03, 2025


Polarization, as a new optical imaging tool, has been explored to assist in the diagnosis of pathology. Moreover, converting the polarimetric Mueller Matrix (MM) to standardized stained images becomes a promising approach to help pathologists interpret the results. However, existing methods for polarization-based virtual staining are still in the early stage, and the diffusion-based model, which has shown great potential in enhancing the fidelity of the generated images, has not been studied yet. In this paper, a Regulated Bridge Diffusion Model (RBDM) for polarization-based virtual staining is proposed. RBDM utilizes the bidirectional bridge diffusion process to learn the mapping from polarization images to other modalities such as H\&E and fluorescence. And to demonstrate the effectiveness of our model, we conduct the experiment on our manually collected dataset, which consists of 18,000 paired polarization, fluorescence and H\&E images, due to the unavailability of the public dataset. The experiment results show that our model greatly outperforms other benchmark methods. Our dataset and code will be released upon acceptance.
EAGLE: Elevating Geometric Reasoning through LLM-empowered Visual Instruction Tuning
Aug 21, 2024



Multi-modal Large Language Models have recently experienced rapid developments and excel in various multi-modal tasks. However, they still struggle with mathematical geometric problem solving, which requires exceptional visual perception proficiency. Existing MLLMs mostly optimize the LLM backbone to acquire geometric reasoning capabilities, while rarely emphasizing improvements in visual comprehension. In this paper, we first investigate the visual perception performance of MLLMs when facing geometric diagrams. Our findings reveal that current MLLMs severely suffer from inaccurate geometric perception and hallucinations. To address these limitations, we propose EAGLE, a novel two-stage end-to-end visual enhancement MLLM framework designed to ElevAte Geometric reasoning through LLM-Empowered visual instruction tuning. Specifically, in the preliminary stage, we feed geometric image-caption pairs into our MLLM that contains a fully fine-tuning CLIP ViT and a frozen LLM, aiming to endow our model with basic geometric knowledge. In the subsequent advanced stage, we incorporate LoRA modules into the vision encoder and unfreeze the LLM backbone. This enables the model to leverage the inherent CoT rationales within question-answer pairs, guiding the MLLM to focus on nuanced visual cues and enhancing its overall perceptual capacity. Moreover, we optimize the cross-modal projector in both stages to foster adaptive visual-linguistic alignments. After the two-stage visual enhancement, we develop the geometry expert model EAGLE-7B. Extensive experiments on popular benchmarks demonstrate the effectiveness of our model. For example, on the GeoQA benchmark, EAGLE-7B not only surpasses the exemplary G-LLaVA 7B model by 2.9%, but also marginally outperforms the larger G-LLaVA 13B model. On the MathVista benchmark, EAGLE-7B achieves remarkable 3.8% improvements compared with the proprietary model GPT-4V.
Teach CLIP to Develop a Number Sense for Ordinal Regression
Aug 07, 2024



Ordinal regression is a fundamental problem within the field of computer vision, with customised well-trained models on specific tasks. While pre-trained vision-language models (VLMs) have exhibited impressive performance on various vision tasks, their potential for ordinal regression has received less exploration. In this study, we first investigate CLIP's potential for ordinal regression, from which we expect the model could generalise to different ordinal regression tasks and scenarios. Unfortunately, vanilla CLIP fails on this task, since current VLMs have a well-documented limitation of encapsulating compositional concepts such as number sense. We propose a simple yet effective method called NumCLIP to improve the quantitative understanding of VLMs. We disassemble the exact image to number-specific text matching problem into coarse classification and fine prediction stages. We discretize and phrase each numerical bin with common language concept to better leverage the available pre-trained alignment in CLIP. To consider the inherent continuous property of ordinal regression, we propose a novel fine-grained cross-modal ranking-based regularisation loss specifically designed to keep both semantic and ordinal alignment in CLIP's feature space. Experimental results on three general ordinal regression tasks demonstrate the effectiveness of NumCLIP, with 10% and 3.83% accuracy improvement on historical image dating and image aesthetics assessment task, respectively. Code is publicly available at https://github.com/xmed-lab/NumCLIP.
MIPI 2024 Challenge on Few-shot RAW Image Denoising: Methods and Results
Jun 11, 2024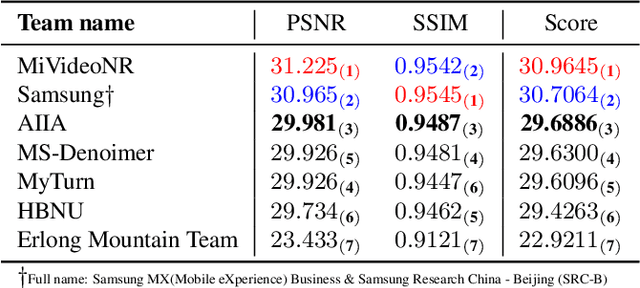
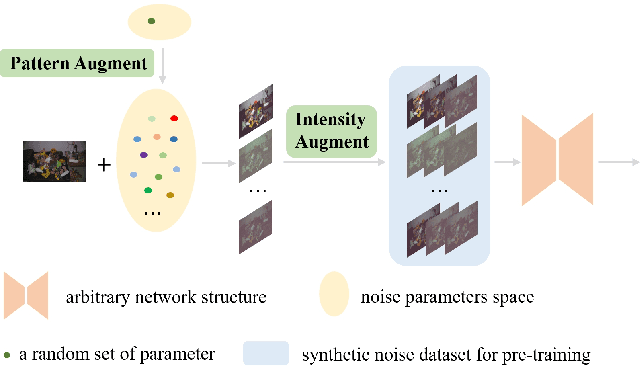

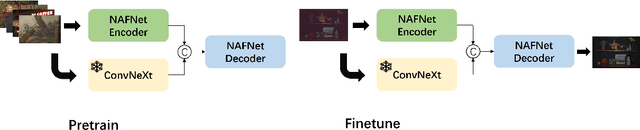
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Few-shot RAW Image Denoising track on MIPI 2024. In total, 165 participants were successfully registered, and 7 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art erformance on Few-shot RAW Image Denoising. More details of this challenge and the link to the dataset can be found at https://mipichallenge.org/MIPI2024.
Toward Efficient Visual Gyroscopes: Spherical Moments, Harmonics Filtering, and Masking Techniques for Spherical Camera Applications
Apr 02, 2024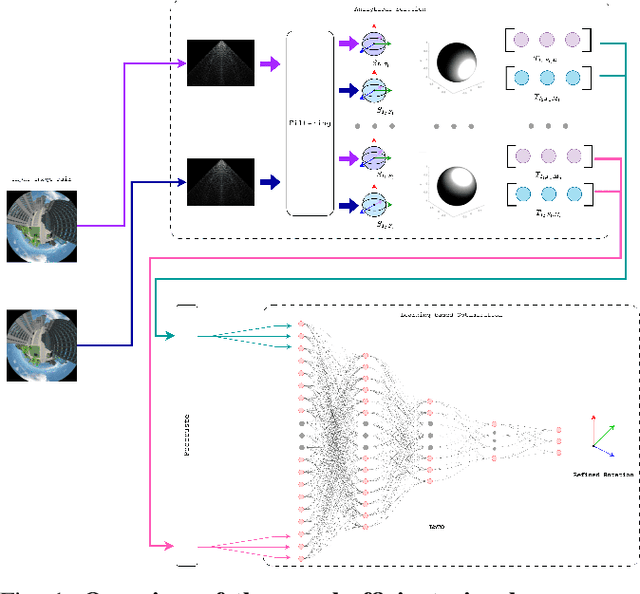



Unlike a traditional gyroscope, a visual gyroscope estimates camera rotation through images. The integration of omnidirectional cameras, offering a larger field of view compared to traditional RGB cameras, has proven to yield more accurate and robust results. However, challenges arise in situations that lack features, have substantial noise causing significant errors, and where certain features in the images lack sufficient strength, leading to less precise prediction results. Here, we address these challenges by introducing a novel visual gyroscope, which combines an analytical method with a neural network approach to provide a more efficient and accurate rotation estimation from spherical images. The presented method relies on three key contributions: an adapted analytical approach to compute the spherical moments coefficients, introduction of masks for better global feature representation, and the use of a multilayer perceptron to adaptively choose the best combination of masks and filters. Experimental results demonstrate superior performance of the proposed approach in terms of accuracy. The paper emphasizes the advantages of integrating machine learning to optimize analytical solutions, discusses limitations, and suggests directions for future research.
Sign Language Production with Latent Motion Transformer
Dec 20, 2023



Sign Language Production (SLP) is the tough task of turning sign language into sign videos. The main goal of SLP is to create these videos using a sign gloss. In this research, we've developed a new method to make high-quality sign videos without using human poses as a middle step. Our model works in two main parts: first, it learns from a generator and the video's hidden features, and next, it uses another model to understand the order of these hidden features. To make this method even better for sign videos, we make several significant improvements. (i) In the first stage, we take an improved 3D VQ-GAN to learn downsampled latent representations. (ii) In the second stage, we introduce sequence-to-sequence attention to better leverage conditional information. (iii) The separated two-stage training discards the realistic visual semantic of the latent codes in the second stage. To endow the latent sequences semantic information, we extend the token-level autoregressive latent codes learning with perceptual loss and reconstruction loss for the prior model with visual perception. Compared with previous state-of-the-art approaches, our model performs consistently better on two word-level sign language datasets, i.e., WLASL and NMFs-CSL.