 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Semi-Supervised Deep Regression with Generalized Ordinal Rankings from Spectral Seriation
Dec 10, 2025Contrastive learning methods enforce label distance relationships in feature space to improve representation capability for regression models. However, these methods highly depend on label information to correctly recover ordinal relationships of features, limiting their applications to semi-supervised regression. In this work, we extend contrastive regression methods to allow unlabeled data to be used in the semi-supervised setting, thereby reducing the dependence on costly annotations. Particularly we construct the feature similarity matrix with both labeled and unlabeled samples in a mini-batch to reflect inter-sample relationships, and an accurate ordinal ranking of involved unlabeled samples can be recovered through spectral seriation algorithms if the level of error is within certain bounds. The introduction of labeled samples above provides regularization of the ordinal ranking with guidance from the ground-truth label information, making the ranking more reliable. To reduce feature perturbations, we further utilize the dynamic programming algorithm to select robust features for the matrix construction. The recovered ordinal relationship is then used for contrastive learning on unlabeled samples, and we thus allow more data to be used for feature representation learning, thereby achieving more robust results. The ordinal rankings can also be used to supervise predictions on unlabeled samples, serving as an additional training signal. We provide theoretical guarantees and empirical verification through experiments on various datasets, demonstrating that our method can surpass existing state-of-the-art semi-supervised deep regression methods. Our code have been released on https://github.com/xmed-lab/CLSS.
A Survey of Deep Learning Methods in Protein Bioinformatics and its Impact on Protein Design
Jan 02, 2025



Proteins are sequences of amino acids that serve as the basic building blocks of living organisms. Despite rapidly growing databases documenting structural and functional information for various protein sequences, our understanding of proteins remains limited because of the large possible sequence space and the complex inter- and intra-molecular forces. Deep learning, which is characterized by its ability to learn relevant features directly from large datasets, has demonstrated remarkable performance in fields such as computer vision and natural language processing. It has also been increasingly applied in recent years to the data-rich domain of protein sequences with great success, most notably with Alphafold2's breakout performance in the protein structure prediction. The performance improvements achieved by deep learning unlocks new possibilities in the field of protein bioinformatics, including protein design, one of the most difficult but useful tasks. In this paper, we broadly categorize problems in protein bioinformatics into three main categories: 1) structural prediction, 2) functional prediction, and 3) protein design, and review the progress achieved from using deep learning methodologies in each of them. We expand on the main challenges of the protein design problem and highlight how advances in structural and functional prediction have directly contributed to design tasks. Finally, we conclude by identifying important topics and future research directions.
Teach CLIP to Develop a Number Sense for Ordinal Regression
Aug 07, 2024



Ordinal regression is a fundamental problem within the field of computer vision, with customised well-trained models on specific tasks. While pre-trained vision-language models (VLMs) have exhibited impressive performance on various vision tasks, their potential for ordinal regression has received less exploration. In this study, we first investigate CLIP's potential for ordinal regression, from which we expect the model could generalise to different ordinal regression tasks and scenarios. Unfortunately, vanilla CLIP fails on this task, since current VLMs have a well-documented limitation of encapsulating compositional concepts such as number sense. We propose a simple yet effective method called NumCLIP to improve the quantitative understanding of VLMs. We disassemble the exact image to number-specific text matching problem into coarse classification and fine prediction stages. We discretize and phrase each numerical bin with common language concept to better leverage the available pre-trained alignment in CLIP. To consider the inherent continuous property of ordinal regression, we propose a novel fine-grained cross-modal ranking-based regularisation loss specifically designed to keep both semantic and ordinal alignment in CLIP's feature space. Experimental results on three general ordinal regression tasks demonstrate the effectiveness of NumCLIP, with 10% and 3.83% accuracy improvement on historical image dating and image aesthetics assessment task, respectively. Code is publicly available at https://github.com/xmed-lab/NumCLIP.
Radiomics-Informed Deep Learning for Classification of Atrial Fibrillation Sub-Types from Left-Atrium CT Volumes
Aug 14, 2023



Atrial Fibrillation (AF) is characterized by rapid, irregular heartbeats, and can lead to fatal complications such as heart failure. The disease is divided into two sub-types based on severity, which can be automatically classified through CT volumes for disease screening of severe cases. However, existing classification approaches rely on generic radiomic features that may not be optimal for the task, whilst deep learning methods tend to over-fit to the high-dimensional volume inputs. In this work, we propose a novel radiomics-informed deep-learning method, RIDL, that combines the advantages of deep learning and radiomic approaches to improve AF sub-type classification. Unlike existing hybrid techniques that mostly rely on na\"ive feature concatenation, we observe that radiomic feature selection methods can serve as an information prior, and propose supplementing low-level deep neural network (DNN) features with locally computed radiomic features. This reduces DNN over-fitting and allows local variations between radiomic features to be better captured. Furthermore, we ensure complementary information is learned by deep and radiomic features by designing a novel feature de-correlation loss. Combined, our method addresses the limitations of deep learning and radiomic approaches and outperforms state-of-the-art radiomic, deep learning, and hybrid approaches, achieving 86.9% AUC for the AF sub-type classification task. Code is available at https://github.com/xmed-lab/RIDL.
Fundus-Enhanced Disease-Aware Distillation Model for Retinal Disease Classification from OCT Images
Aug 01, 2023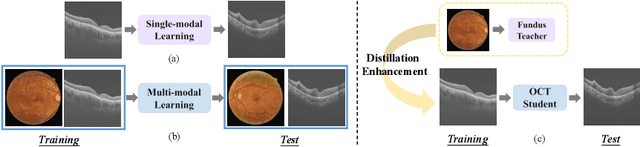

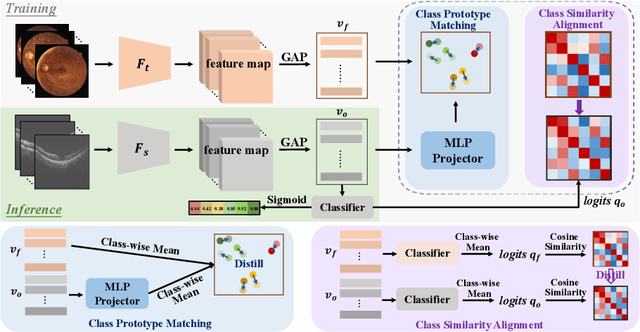
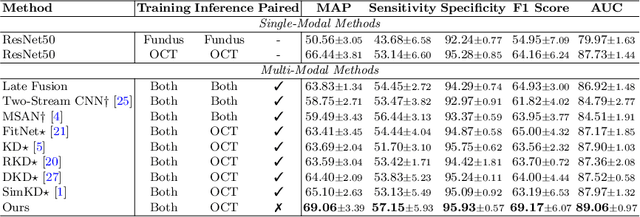
Optical Coherence Tomography (OCT) is a novel and effective screening tool for ophthalmic examination. Since collecting OCT images is relatively more expensive than fundus photographs, existing methods use multi-modal learning to complement limited OCT data with additional context from fundus images. However, the multi-modal framework requires eye-paired datasets of both modalities, which is impractical for clinical use. To address this problem, we propose a novel fundus-enhanced disease-aware distillation model (FDDM), for retinal disease classification from OCT images. Our framework enhances the OCT model during training by utilizing unpaired fundus images and does not require the use of fundus images during testing, which greatly improves the practicality and efficiency of our method for clinical use. Specifically, we propose a novel class prototype matching to distill disease-related information from the fundus model to the OCT model and a novel class similarity alignment to enforce consistency between disease distribution of both modalities. Experimental results show that our proposed approach outperforms single-modal, multi-modal, and state-of-the-art distillation methods for retinal disease classification. Code is available at https://github.com/xmed-lab/FDDM.
Semi-Supervised Deep Regression with Uncertainty Consistency and Variational Model Ensembling via Bayesian Neural Networks
Feb 15, 2023



Deep regression is an important problem with numerous applications. These range from computer vision tasks such as age estimation from photographs, to medical tasks such as ejection fraction estimation from echocardiograms for disease tracking. Semi-supervised approaches for deep regression are notably under-explored compared to classification and segmentation tasks, however. Unlike classification tasks, which rely on thresholding functions for generating class pseudo-labels, regression tasks use real number target predictions directly as pseudo-labels, making them more sensitive to prediction quality. In this work, we propose a novel approach to semi-supervised regression, namely Uncertainty-Consistent Variational Model Ensembling (UCVME), which improves training by generating high-quality pseudo-labels and uncertainty estimates for heteroscedastic regression. Given that aleatoric uncertainty is only dependent on input data by definition and should be equal for the same inputs, we present a novel uncertainty consistency loss for co-trained models. Our consistency loss significantly improves uncertainty estimates and allows higher quality pseudo-labels to be assigned greater importance under heteroscedastic regression. Furthermore, we introduce a novel variational model ensembling approach to reduce prediction noise and generate more robust pseudo-labels. We analytically show our method generates higher quality targets for unlabeled data and further improves training. Experiments show that our method outperforms state-of-the-art alternatives on different tasks and can be competitive with supervised methods that use full labels. Our code is available at https://github.com/xmed-lab/UCVME.
Cyclical Self-Supervision for Semi-Supervised Ejection Fraction Prediction from Echocardiogram Videos
Oct 20, 2022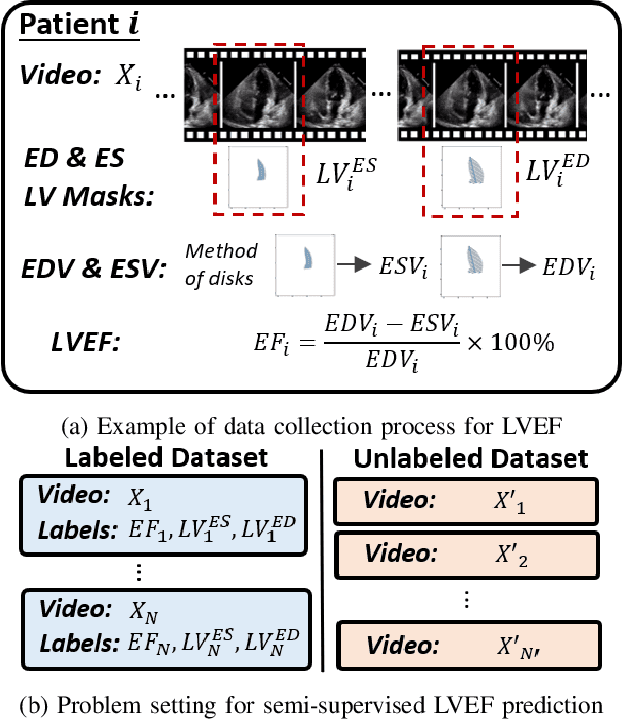
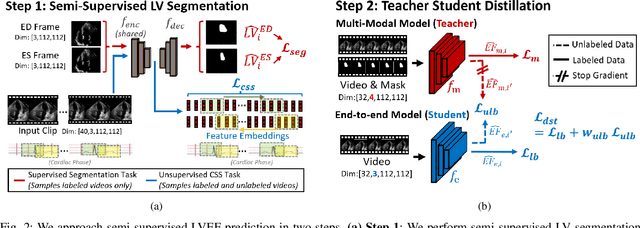
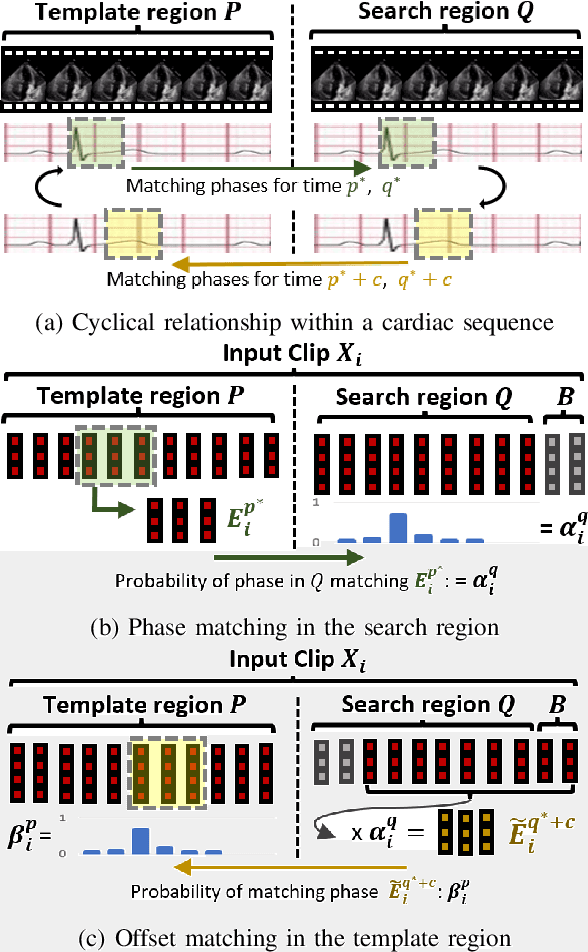
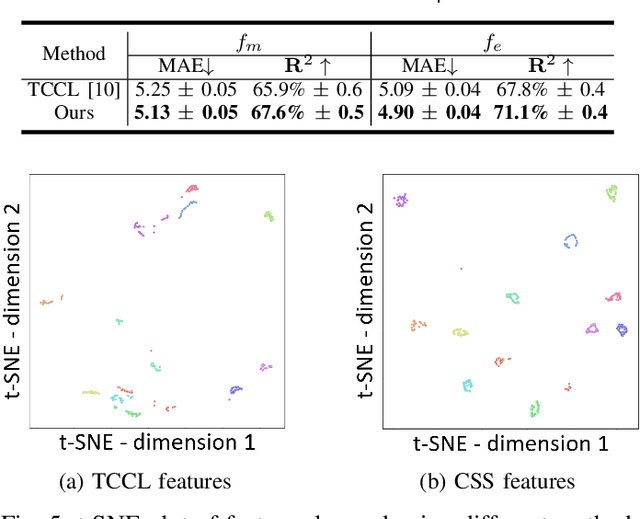
Left-ventricular ejection fraction (LVEF) is an important indicator of heart failure. Existing methods for LVEF estimation from video require large amounts of annotated data to achieve high performance, e.g. using 10,030 labeled echocardiogram videos to achieve mean absolute error (MAE) of 4.10. Labeling these videos is time-consuming however and limits potential downstream applications to other heart diseases. This paper presents the first semi-supervised approach for LVEF prediction. Unlike general video prediction tasks, LVEF prediction is specifically related to changes in the left ventricle (LV) in echocardiogram videos. By incorporating knowledge learned from predicting LV segmentations into LVEF regression, we can provide additional context to the model for better predictions. To this end, we propose a novel Cyclical Self-Supervision (CSS) method for learning video-based LV segmentation, which is motivated by the observation that the heartbeat is a cyclical process with temporal repetition. Prediction masks from our segmentation model can then be used as additional input for LVEF regression to provide spatial context for the LV region. We also introduce teacher-student distillation to distill the information from LV segmentation masks into an end-to-end LVEF regression model that only requires video inputs. Results show our method outperforms alternative semi-supervised methods and can achieve MAE of 4.17, which is competitive with state-of-the-art supervised performance, using half the number of labels. Validation on an external dataset also shows improved generalization ability from using our method.
Adaptive Contrast for Image Regression in Computer-Aided Disease Assessment
Dec 22, 2021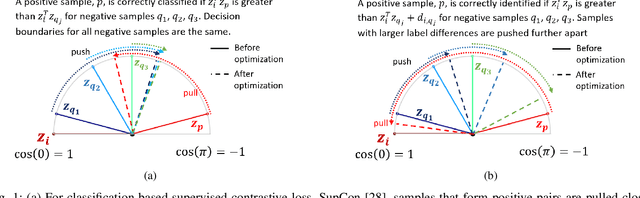
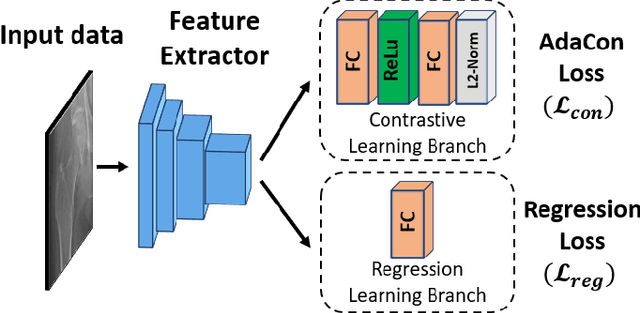
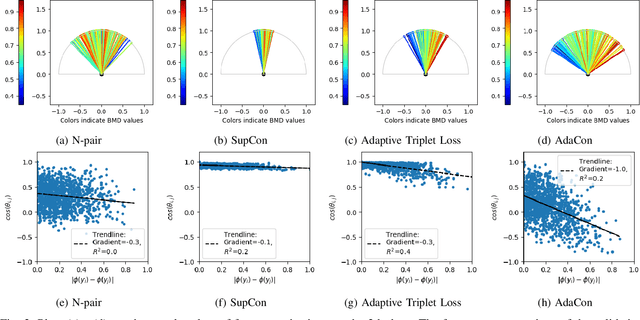
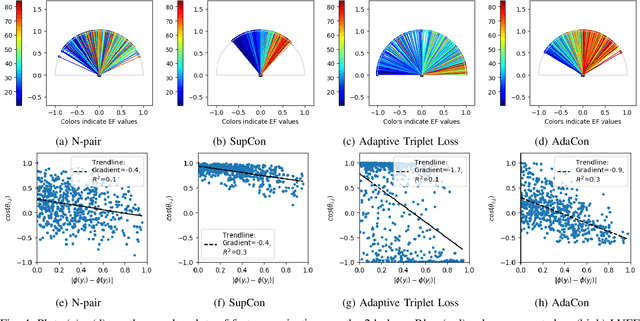
Image regression tasks for medical applications, such as bone mineral density (BMD) estimation and left-ventricular ejection fraction (LVEF) prediction, play an important role in computer-aided disease assessment. Most deep regression methods train the neural network with a single regression loss function like MSE or L1 loss. In this paper, we propose the first contrastive learning framework for deep image regression, namely AdaCon, which consists of a feature learning branch via a novel adaptive-margin contrastive loss and a regression prediction branch. Our method incorporates label distance relationships as part of the learned feature representations, which allows for better performance in downstream regression tasks. Moreover, it can be used as a plug-and-play module to improve performance of existing regression methods. We demonstrate the effectiveness of AdaCon on two medical image regression tasks, ie, bone mineral density estimation from X-ray images and left-ventricular ejection fraction prediction from echocardiogram videos. AdaCon leads to relative improvements of 3.3% and 5.9% in MAE over state-of-the-art BMD estimation and LVEF prediction methods, respectively.