 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclical Self-Supervision for Semi-Supervised Ejection Fraction Prediction from Echocardiogram Videos
Paper and Code
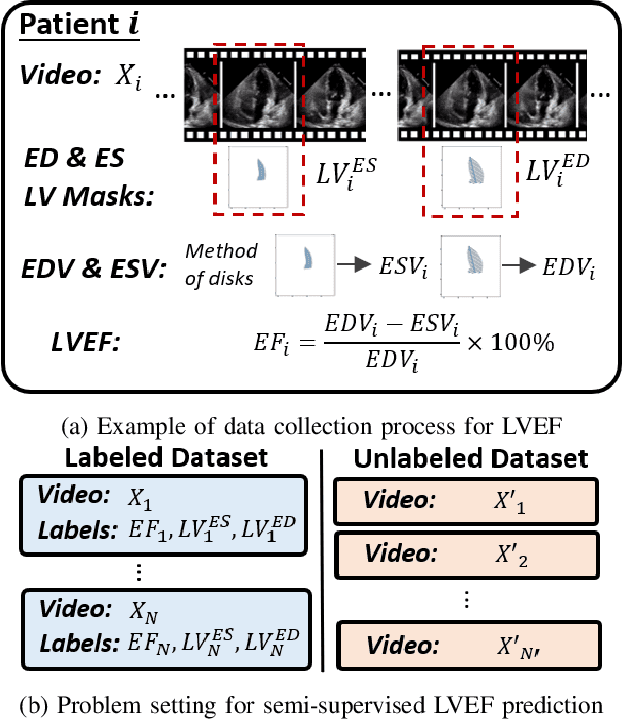
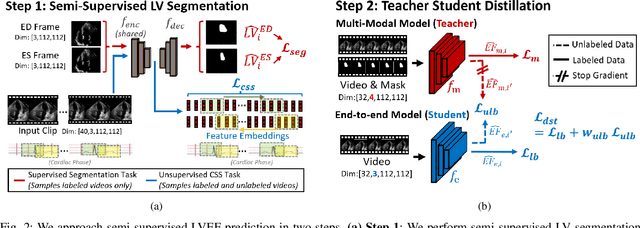
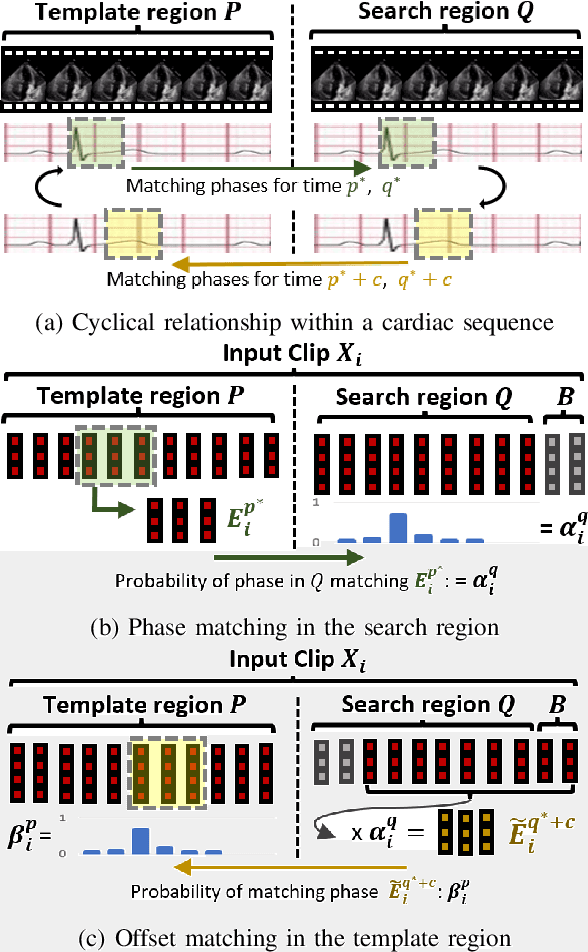
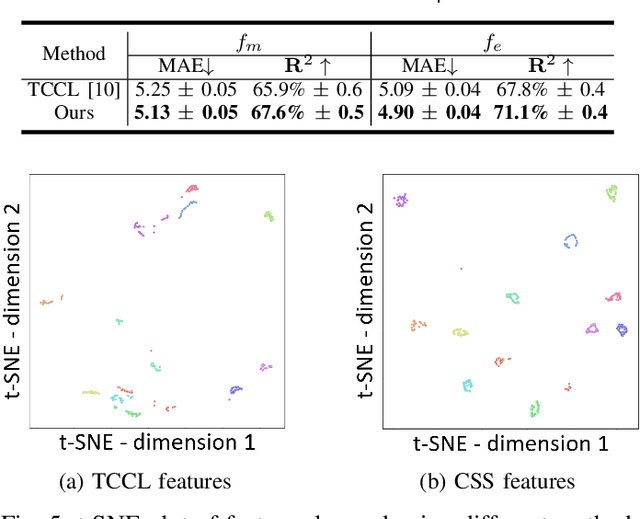
Left-ventricular ejection fraction (LVEF) is an important indicator of heart failure. Existing methods for LVEF estimation from video require large amounts of annotated data to achieve high performance, e.g. using 10,030 labeled echocardiogram videos to achieve mean absolute error (MAE) of 4.10. Labeling these videos is time-consuming however and limits potential downstream applications to other heart diseases. This paper presents the first semi-supervised approach for LVEF prediction. Unlike general video prediction tasks, LVEF prediction is specifically related to changes in the left ventricle (LV) in echocardiogram videos. By incorporating knowledge learned from predicting LV segmentations into LVEF regression, we can provide additional context to the model for better predictions. To this end, we propose a novel Cyclical Self-Supervision (CSS) method for learning video-based LV segmentation, which is motivated by the observation that the heartbeat is a cyclical process with temporal repetition. Prediction masks from our segmentation model can then be used as additional input for LVEF regression to provide spatial context for the LV region. We also introduce teacher-student distillation to distill the information from LV segmentation masks into an end-to-end LVEF regression model that only requires video inputs. Results show our method outperforms alternative semi-supervised methods and can achieve MAE of 4.17, which is competitive with state-of-the-art supervised performance, using half the number of labels. Validation on an external dataset also shows improved generalization ability from using our method.