 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Contrast for Image Regression in Computer-Aided Disease Assessment
Dec 22, 2021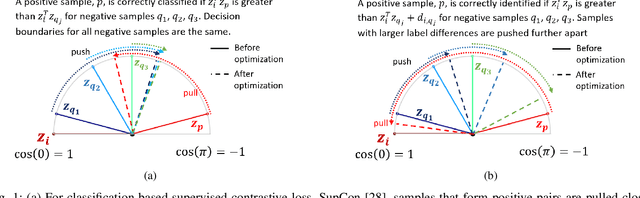
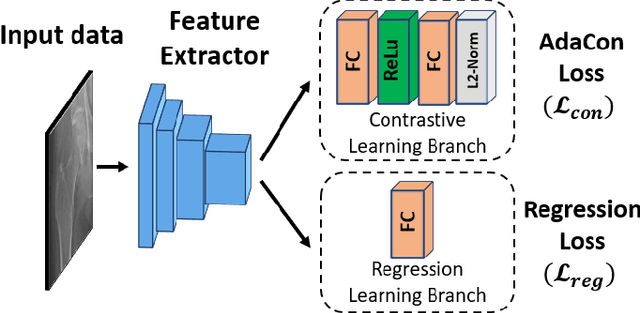
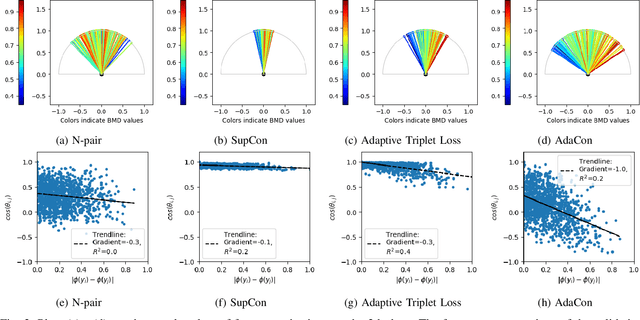
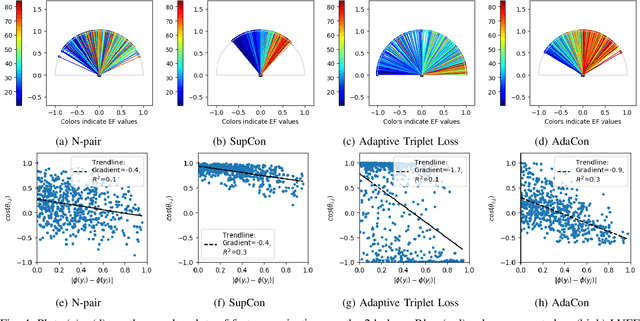
Image regression tasks for medical applications, such as bone mineral density (BMD) estimation and left-ventricular ejection fraction (LVEF) prediction, play an important role in computer-aided disease assessment. Most deep regression methods train the neural network with a single regression loss function like MSE or L1 loss. In this paper, we propose the first contrastive learning framework for deep image regression, namely AdaCon, which consists of a feature learning branch via a novel adaptive-margin contrastive loss and a regression prediction branch. Our method incorporates label distance relationships as part of the learned feature representations, which allows for better performance in downstream regression tasks. Moreover, it can be used as a plug-and-play module to improve performance of existing regression methods. We demonstrate the effectiveness of AdaCon on two medical image regression tasks, ie, bone mineral density estimation from X-ray images and left-ventricular ejection fraction prediction from echocardiogram videos. AdaCon leads to relative improvements of 3.3% and 5.9% in MAE over state-of-the-art BMD estimation and LVEF prediction methods, respectively.
A Variational Approach to Unsupervised Sentiment Analysis
Aug 21, 2020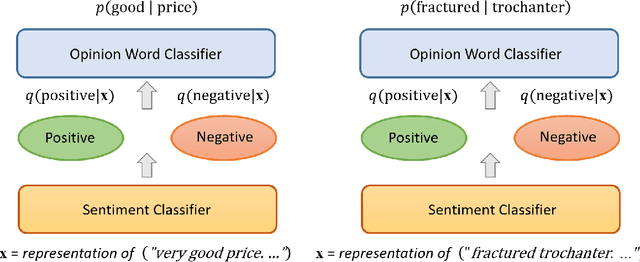
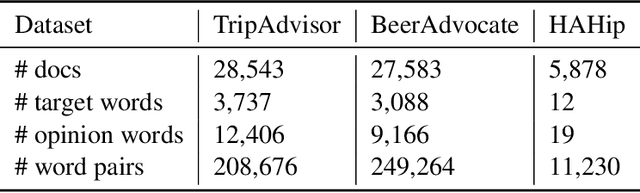
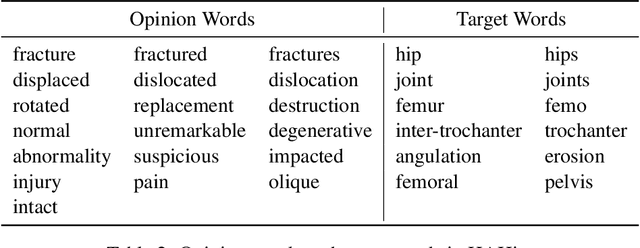
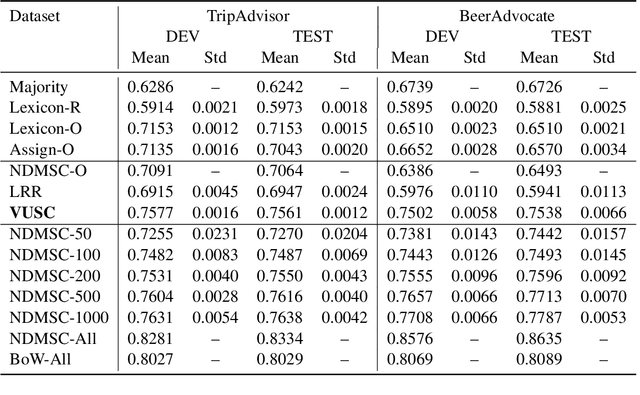
In this paper, we propose a variational approach to unsupervised sentiment analysis. Instead of using ground truth provided by domain experts, we use target-opinion word pairs as a supervision signal. For example, in a document snippet "the room is big," (room, big) is a target-opinion word pair. These word pairs can be extracted by using dependency parsers and simple rules. Our objective function is to predict an opinion word given a target word while our ultimate goal is to learn a sentiment classifier. By introducing a latent variable, i.e., the sentiment polarity, to the objective function, we can inject the sentiment classifier to the objective function via the evidence lower bound. We can learn a sentiment classifier by optimizing the lower bound. We also impose sophisticated constraints on opinion words as regularization which encourages that if two documents have similar (dissimilar) opinion words, the sentiment classifiers should produce similar (different) probability distribution. We apply our method to sentiment analysis on customer reviews and clinical narratives. The experiment results show our method can outperform unsupervised baselines in sentiment analysis task on both domains, and our method obtains comparable results to the supervised method with hundreds of labels per aspect in customer reviews domain, and obtains comparable results to supervised methods in clinical narratives domain.