 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Constraints with Prompting for Zero-Shot Event Argument Classification
Feb 09, 2023Determining the role of event arguments is a crucial subtask of event extraction. Most previous supervised models leverage costly annotations, which is not practical for open-domain applications. In this work, we propose to use global constraints with prompting to effectively tackles event argument classification without any annotation and task-specific training. Specifically, given an event and its associated passage, the model first creates several new passages by prefix prompts and cloze prompts, where prefix prompts indicate event type and trigger span, and cloze prompts connect each candidate role with the target argument span. Then, a pre-trained language model scores the new passages, making the initial prediction. Our novel prompt templates can easily adapt to all events and argument types without manual effort. Next, the model regularizes the prediction by global constraints exploiting cross-task, cross-argument, and cross-event relations. Extensive experiments demonstrate our model's effectiveness: it outperforms the best zero-shot baselines by 12.5% and 10.9% F1 on ACE and ERE with given argument spans and by 4.3% and 3.3% F1, respectively, without given argument spans. We have made our code publicly available.
A Variational Approach to Unsupervised Sentiment Analysis
Aug 21, 2020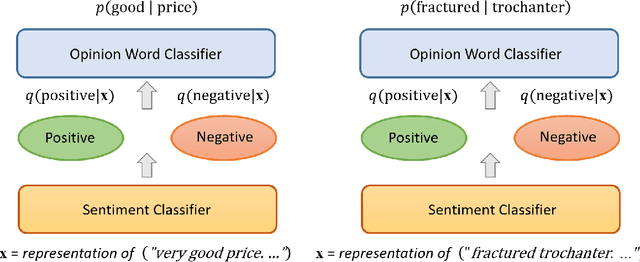
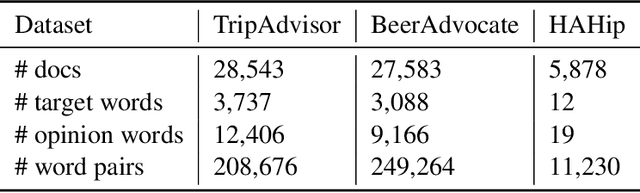
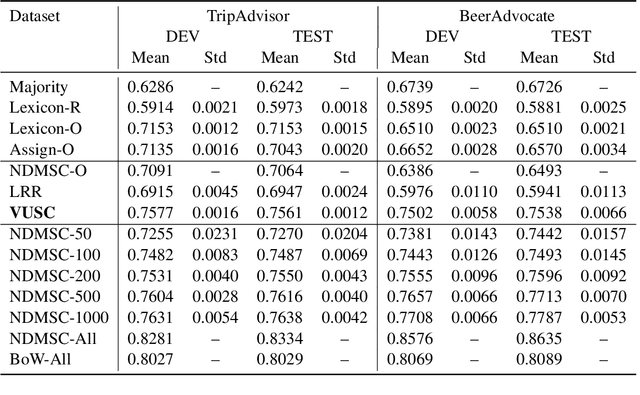
In this paper, we propose a variational approach to unsupervised sentiment analysis. Instead of using ground truth provided by domain experts, we use target-opinion word pairs as a supervision signal. For example, in a document snippet "the room is big," (room, big) is a target-opinion word pair. These word pairs can be extracted by using dependency parsers and simple rules. Our objective function is to predict an opinion word given a target word while our ultimate goal is to learn a sentiment classifier. By introducing a latent variable, i.e., the sentiment polarity, to the objective function, we can inject the sentiment classifier to the objective function via the evidence lower bound. We can learn a sentiment classifier by optimizing the lower bound. We also impose sophisticated constraints on opinion words as regularization which encourages that if two documents have similar (dissimilar) opinion words, the sentiment classifiers should produce similar (different) probability distribution. We apply our method to sentiment analysis on customer reviews and clinical narratives. The experiment results show our method can outperform unsupervised baselines in sentiment analysis task on both domains, and our method obtains comparable results to the supervised method with hundreds of labels per aspect in customer reviews domain, and obtains comparable results to supervised methods in clinical narratives domain.
Multilingual and Multi-Aspect Hate Speech Analysis
Aug 29, 2019


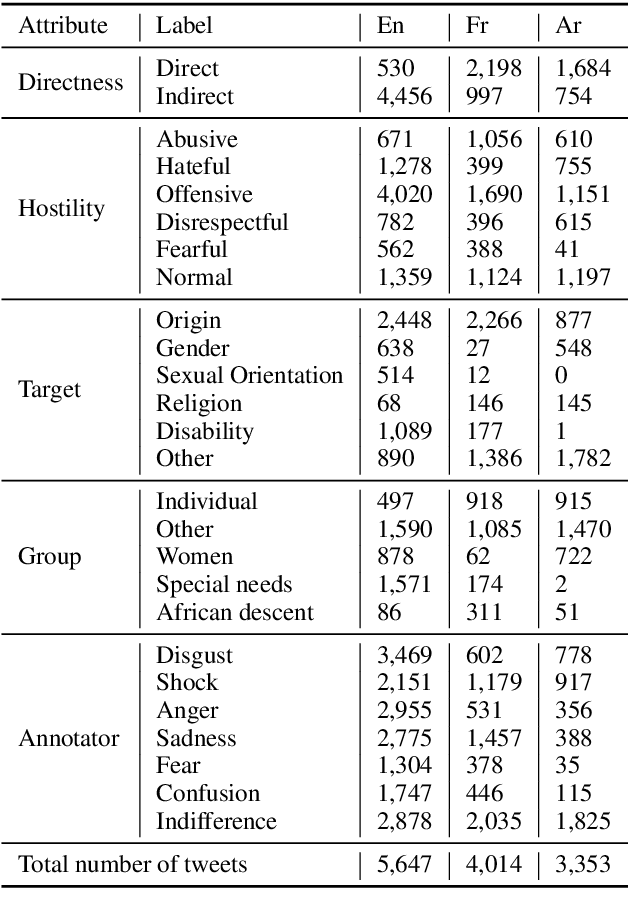
Current research on hate speech analysis is typically oriented towards monolingual and single classification tasks. In this paper, we present a new multilingual multi-aspect hate speech analysis dataset and use it to test the current state-of-the-art multilingual multitask learning approaches. We evaluate our dataset in various classification settings, then we discuss how to leverage our annotations in order to improve hate speech detection and classification in general.
Incorporating Features Learned by an Enhanced Deep Knowledge Tracing Model for STEM/Non-STEM Job Prediction
Jun 06, 2018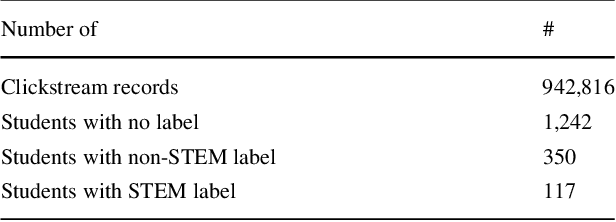
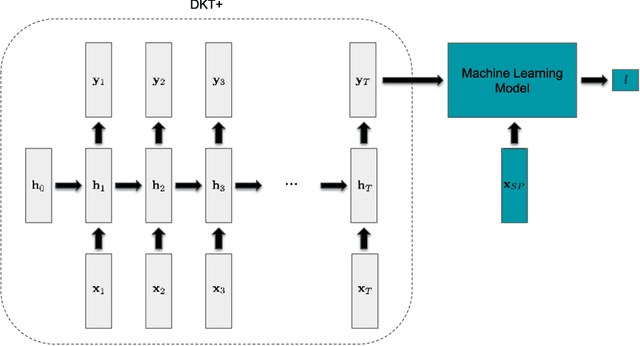
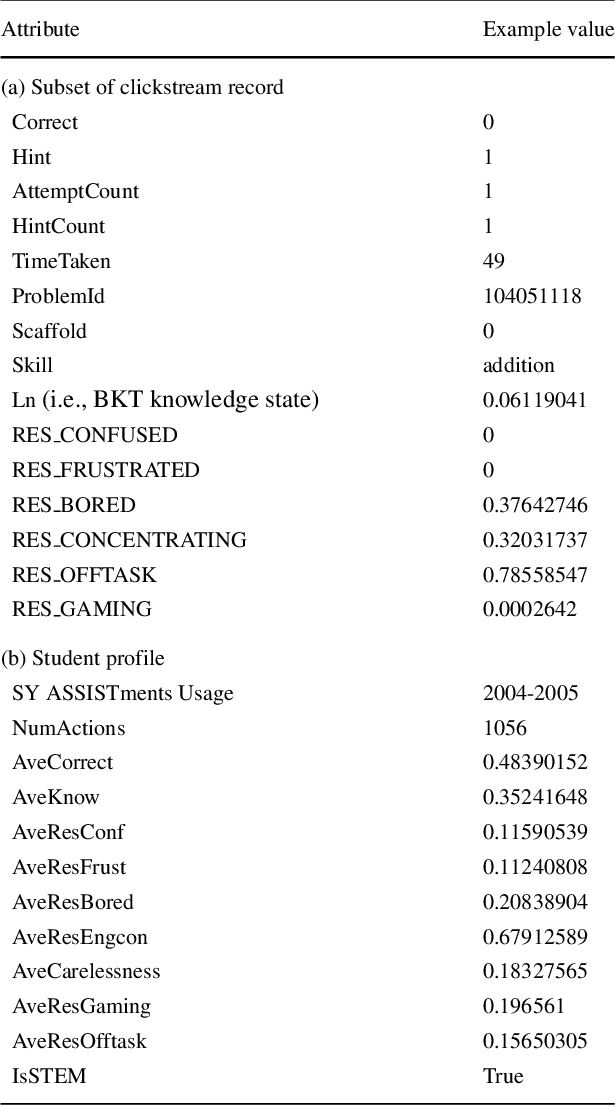
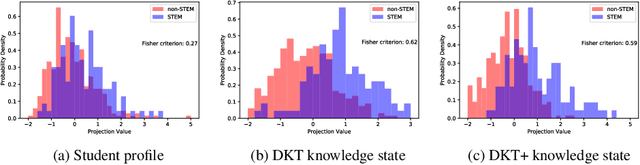
The 2017 ASSISTments Data Mining competition aims to use data from a longitudinal study for predicting a brand-new outcome of students which had never been studied before by the educational data mining research community. Specifically, it facilitates research in developing predictive models that predict whether the first job of a student out of college belongs to a STEM (the acronym for science, technology, engineering, and mathematics) field. This is based on the student's learning history on the ASSISTments blended learning platform in the form of extensive clickstream data gathered during the middle school years. To tackle this challenge, we first estimate the expected knowledge state of students with respect to different mathematical skills using a deep knowledge tracing (DKT) model and an enhanced DKT (DKT+) model. We then combine the features corresponding to the DKT/DKT+ expected knowledge state with other features extracted directly from the student profile in the dataset to train several machine learning models for the STEM/non-STEM job prediction. Our experiments show that models trained with the combined features generally perform better than the models trained with the student profile alone. Detailed analysis of the student's knowledge state reveals that, when compared with non-STEM students, STEM students generally show a higher mastery level and a higher learning gain in mathematics.