 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePingPong: A Natural Benchmark for Multi-Turn Code-Switching Dialogues
Jan 24, 2026Code-switching is a widespread practice among the world's multilingual majority, yet few benchmarks accurately reflect its complexity in everyday communication. We present PingPong, a benchmark for natural multi-party code-switching dialogues covering five language-combination variations, some of which are trilingual. Our dataset consists of human-authored conversations among 2 to 4 participants covering authentic, multi-threaded structures where replies frequently reference much earlier points in the dialogue. We demonstrate that our data is significantly more natural and structurally diverse than machine-generated alternatives, offering greater variation in message length, speaker dominance, and reply distance. Based on these dialogues, we define three downstream tasks: Question Answering, Dialogue Summarization, and Topic Classification. Evaluations of several state-of-the-art language models on PingPong reveal that performance remains limited on code-switched inputs, underscoring the urgent need for more robust NLP systems capable of addressing the intricacies of real-world multilingual discourse.
Annotating Dimensions of Social Perception in Text: The First Sentence-Level Dataset of Warmth and Competence
Jan 09, 2026Warmth (W) (often further broken down into Trust (T) and Sociability (S)) and Competence (C) are central dimensions along which people evaluate individuals and social groups (Fiske, 2018). While these constructs are well established in social psychology, they are only starting to get attention in NLP research through word-level lexicons, which do not completely capture their contextual expression in larger text units and discourse. In this work, we introduce Warmth and Competence Sentences (W&C-Sent), the first sentence-level dataset annotated for warmth and competence. The dataset includes over 1,600 English sentence--target pairs annotated along three dimensions: trust and sociability (components of warmth), and competence. The sentences in W&C-Sent are from social media and often express attitudes and opinions about specific individuals or social groups (the targets of our annotations). We describe the data collection, annotation, and quality-control procedures in detail, and evaluate a range of large language models (LLMs) on their ability to identify trust, sociability, and competence in text. W&C-Sent provides a new resource for analyzing warmth and competence in language and supports future research at the intersection of NLP and computational social science.
Insights from the ICLR Peer Review and Rebuttal Process
Nov 19, 2025Peer review is a cornerstone of scientific publishing, including at premier machine learning conferences such as ICLR. As submission volumes increase, understanding the nature and dynamics of the review process is crucial for improving its efficiency, effectiveness, and the quality of published papers. We present a large-scale analysis of the ICLR 2024 and 2025 peer review processes, focusing on before- and after-rebuttal scores and reviewer-author interactions. We examine review scores, author-reviewer engagement, temporal patterns in review submissions, and co-reviewer influence effects. Combining quantitative analyses with LLM-based categorization of review texts and rebuttal discussions, we identify common strengths and weaknesses for each rating group, as well as trends in rebuttal strategies that are most strongly associated with score changes. Our findings show that initial scores and the ratings of co-reviewers are the strongest predictors of score changes during the rebuttal, pointing to a degree of reviewer influence. Rebuttals play a valuable role in improving outcomes for borderline papers, where thoughtful author responses can meaningfully shift reviewer perspectives. More broadly, our study offers evidence-based insights to improve the peer review process, guiding authors on effective rebuttal strategies and helping the community design fairer and more efficient review processes. Our code and score changes data are available at https://github.com/papercopilot/iclr-insights.
Beyond Keywords: Evaluating Large Language Model Classification of Nuanced Ableism
May 26, 2025Large language models (LLMs) are increasingly used in decision-making tasks like r\'esum\'e screening and content moderation, giving them the power to amplify or suppress certain perspectives. While previous research has identified disability-related biases in LLMs, little is known about how they conceptualize ableism or detect it in text. We evaluate the ability of four LLMs to identify nuanced ableism directed at autistic individuals. We examine the gap between their understanding of relevant terminology and their effectiveness in recognizing ableist content in context. Our results reveal that LLMs can identify autism-related language but often miss harmful or offensive connotations. Further, we conduct a qualitative comparison of human and LLM explanations. We find that LLMs tend to rely on surface-level keyword matching, leading to context misinterpretations, in contrast to human annotators who consider context, speaker identity, and potential impact. On the other hand, both LLMs and humans agree on the annotation scheme, suggesting that a binary classification is adequate for evaluating LLM performance, which is consistent with findings from prior studies involving human annotators.
Social Good or Scientific Curiosity? Uncovering the Research Framing Behind NLP Artefacts
May 24, 2025



Clarifying the research framing of NLP artefacts (e.g., models, datasets, etc.) is crucial to aligning research with practical applications. Recent studies manually analyzed NLP research across domains, showing that few papers explicitly identify key stakeholders, intended uses, or appropriate contexts. In this work, we propose to automate this analysis, developing a three-component system that infers research framings by first extracting key elements (means, ends, stakeholders), then linking them through interpretable rules and contextual reasoning. We evaluate our approach on two domains: automated fact-checking using an existing dataset, and hate speech detection for which we annotate a new dataset-achieving consistent improvements over strong LLM baselines. Finally, we apply our system to recent automated fact-checking papers and uncover three notable trends: a rise in vague or underspecified research goals, increased emphasis on scientific exploration over application, and a shift toward supporting human fact-checkers rather than pursuing full automation.
SemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection
Mar 10, 2025We present our shared task on text-based emotion detection, covering more than 30 languages from seven distinct language families. These languages are predominantly low-resource and spoken across various continents. The data instances are multi-labeled into six emotional classes, with additional datasets in 11 languages annotated for emotion intensity. Participants were asked to predict labels in three tracks: (a) emotion labels in monolingual settings, (b) emotion intensity scores, and (c) emotion labels in cross-lingual settings. The task attracted over 700 participants. We received final submissions from more than 200 teams and 93 system description papers. We report baseline results, as well as findings on the best-performing systems, the most common approaches, and the most effective methods across various tracks and languages. The datasets for this task are publicly available.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
AfriHate: A Multilingual Collection of Hate Speech and Abusive Language Datasets for African Languages
Jan 15, 2025



Hate speech and abusive language are global phenomena that need socio-cultural background knowledge to be understood, identified, and moderated. However, in many regions of the Global South, there have been several documented occurrences of (1) absence of moderation and (2) censorship due to the reliance on keyword spotting out of context. Further, high-profile individuals have frequently been at the center of the moderation process, while large and targeted hate speech campaigns against minorities have been overlooked. These limitations are mainly due to the lack of high-quality data in the local languages and the failure to include local communities in the collection, annotation, and moderation processes. To address this issue, we present AfriHate: a multilingual collection of hate speech and abusive language datasets in 15 African languages. Each instance in AfriHate is annotated by native speakers familiar with the local culture. We report the challenges related to the construction of the datasets and present various classification baseline results with and without using LLMs. The datasets, individual annotations, and hate speech and offensive language lexicons are available on https://github.com/AfriHate/AfriHate
AUTALIC: A Dataset for Anti-AUTistic Ableist Language In Context
Oct 21, 2024



As our understanding of autism and ableism continues to increase, so does our understanding of ableist language towards autistic people. Such language poses a significant challenge in NLP research due to its subtle and context-dependent nature. Yet, detecting anti-autistic ableist language remains underexplored, with existing NLP tools often failing to capture its nuanced expressions. We present AUTALIC, the first benchmark dataset dedicated to the detection of anti-autistic ableist language in context, addressing a significant gap in the field. The dataset comprises 2,400 autism-related sentences collected from Reddit, accompanied by surrounding context, and is annotated by trained experts with backgrounds in neurodiversity. Our comprehensive evaluation reveals that current language models, including state-of-the-art LLMs, struggle to reliably identify anti-autistic ableism and align with human judgments, underscoring their limitations in this domain. We publicly release AUTALIC along with the individual annotations which serve as a valuable resource to researchers working on ableism, neurodiversity, and also studying disagreements in annotation tasks. This dataset serves as a crucial step towards developing more inclusive and context-aware NLP systems that better reflect diverse perspectives.
Building Better: Avoiding Pitfalls in Developing Language Resources when Data is Scarce
Oct 17, 2024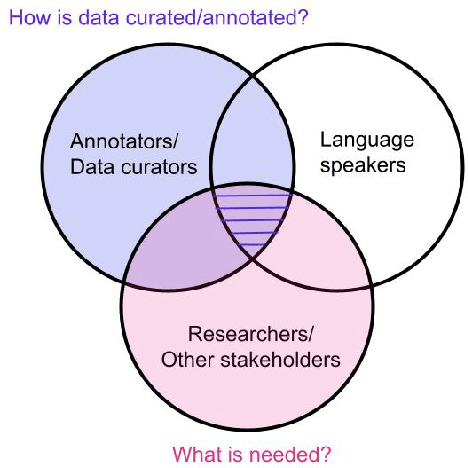

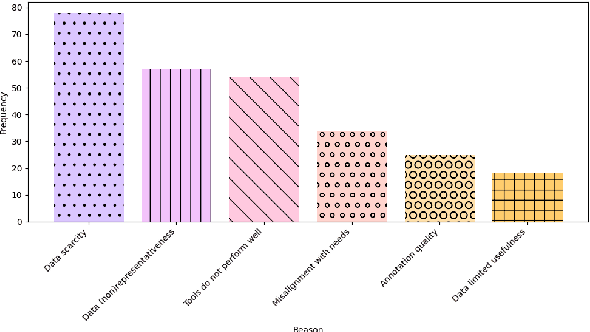
Language is a symbolic capital that affects people's lives in many ways (Bourdieu, 1977, 1991). It is a powerful tool that accounts for identities, cultures, traditions, and societies in general. Hence, data in a given language should be viewed as more than a collection of tokens. Good data collection and labeling practices are key to building more human-centered and socially aware technologies. While there has been a rising interest in mid- to low-resource languages within the NLP community, work in this space has to overcome unique challenges such as data scarcity and access to suitable annotators. In this paper, we collect feedback from those directly involved in and impacted by NLP artefacts for mid- to low-resource languages. We conduct a quantitative and qualitative analysis of the responses and highlight the main issues related to (1) data quality such as linguistic and cultural data suitability; and (2) the ethics of common annotation practices such as the misuse of online community services. Based on these findings, we make several recommendations for the creation of high-quality language artefacts that reflect the cultural milieu of its speakers, while simultaneously respecting the dignity and labor of data workers.