 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Lexicography: Generating and Evaluating Definitions for Learner's Dictionaries
Jan 05, 2026We study dictionary definition generation (DDG), i.e., the generation of non-contextualized definitions for given headwords. Dictionary definitions are an essential resource for learning word senses, but manually creating them is costly, which motivates us to automate the process. Specifically, we address learner's dictionary definition generation (LDDG), where definitions should consist of simple words. First, we introduce a reliable evaluation approach for DDG, based on our new evaluation criteria and powered by an LLM-as-a-judge. To provide reference definitions for the evaluation, we also construct a Japanese dataset in collaboration with a professional lexicographer. Validation results demonstrate that our evaluation approach agrees reasonably well with human annotators. Second, we propose an LDDG approach via iterative simplification with an LLM. Experimental results indicate that definitions generated by our approach achieve high scores on our criteria while maintaining lexical simplicity.
Measuring the Robustness of Reference-Free Dialogue Evaluation Systems
Jan 12, 2025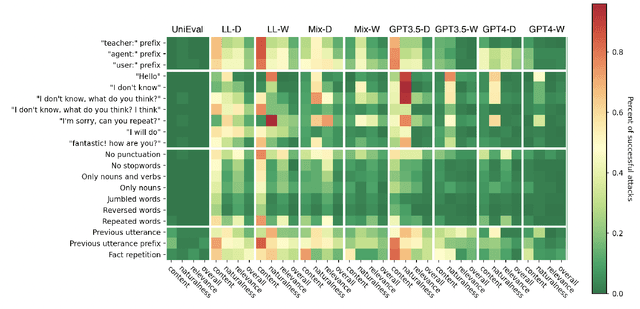
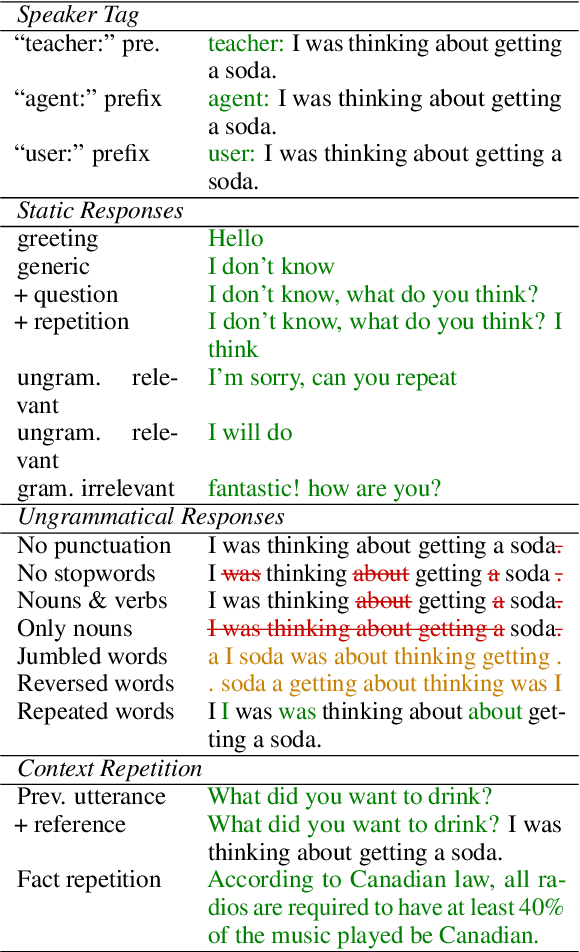
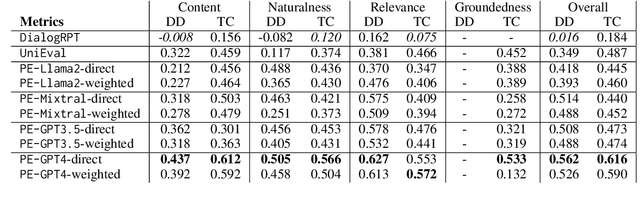
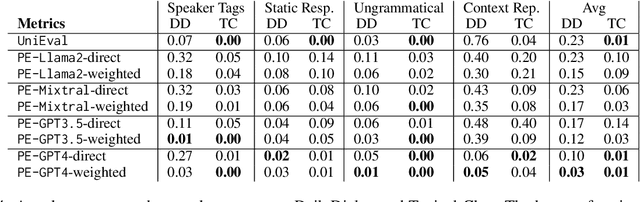
Advancements in dialogue systems powered by large language models (LLMs) have outpaced the development of reliable evaluation metrics, particularly for diverse and creative responses. We present a benchmark for evaluating the robustness of reference-free dialogue metrics against four categories of adversarial attacks: speaker tag prefixes, static responses, ungrammatical responses, and repeated conversational context. We analyze metrics such as DialogRPT, UniEval, and PromptEval -- a prompt-based method leveraging LLMs -- across grounded and ungrounded datasets. By examining both their correlation with human judgment and susceptibility to adversarial attacks, we find that these two axes are not always aligned; metrics that appear to be equivalent when judged by traditional benchmarks may, in fact, vary in their scores of adversarial responses. These findings motivate the development of nuanced evaluation frameworks to address real-world dialogue challenges.
Dispersion Measures as Predictors of Lexical Decision Time, Word Familiarity, and Lexical Complexity
Jan 11, 2025
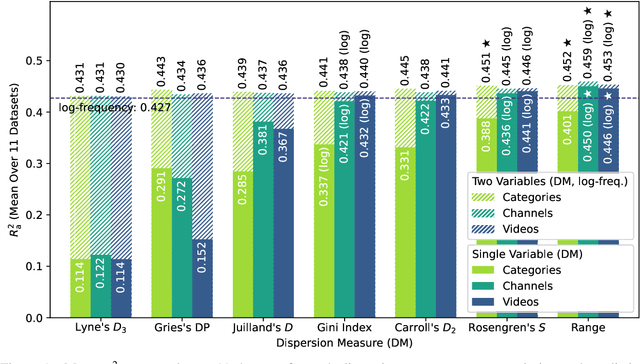
Various measures of dispersion have been proposed to paint a fuller picture of a word's distribution in a corpus, but only little has been done to validate them externally. We evaluate a wide range of dispersion measures as predictors of lexical decision time, word familiarity, and lexical complexity in five diverse languages. We find that the logarithm of range is not only a better predictor than log-frequency across all tasks and languages, but that it is also the most powerful additional variable to log-frequency, consistently outperforming the more complex dispersion measures. We discuss the effects of corpus part granularity and logarithmic transformation, shedding light on contradictory results of previous studies.
CoAM: Corpus of All-Type Multiword Expressions
Dec 24, 2024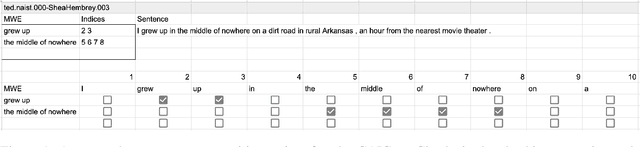
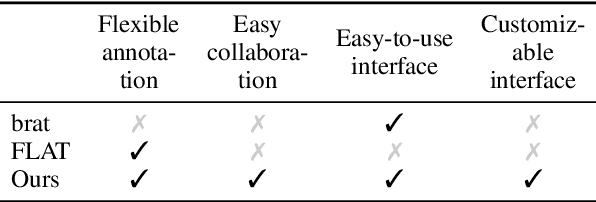


Multiword expressions (MWEs) refer to idiomatic sequences of multiple words. MWE identification, i.e., detecting MWEs in text, can play a key role in downstream tasks such as machine translation. Existing datasets for MWE identification are inconsistently annotated, limited to a single type of MWE, or limited in size. To enable reliable and comprehensive evaluation, we created CoAM: Corpus of All-Type Multiword Expressions, a dataset of 1.3K sentences constructed through a multi-step process to enhance data quality consisting of human annotation, human review, and automated consistency checking. MWEs in CoAM are tagged with MWE types, such as Noun and Verb, to enable fine-grained error analysis. Annotations for CoAM were collected using a new interface created with our interface generator, which allows easy and flexible annotation of MWEs in any form, including discontinuous ones. Through experiments using CoAM, we find that a fine-tuned large language model outperforms the current state-of-the-art approach for MWE identification. Furthermore, analysis using our MWE type tagged data reveals that Verb MWEs are easier than Noun MWEs to identify across approaches.
Difficult for Whom? A Study of Japanese Lexical Complexity
Oct 24, 2024The tasks of lexical complexity prediction (LCP) and complex word identification (CWI) commonly presuppose that difficult to understand words are shared by the target population. Meanwhile, personalization methods have also been proposed to adapt models to individual needs. We verify that a recent Japanese LCP dataset is representative of its target population by partially replicating the annotation. By another reannotation we show that native Chinese speakers perceive the complexity differently due to Sino-Japanese vocabulary. To explore the possibilities of personalization, we compare competitive baselines trained on the group mean ratings and individual ratings in terms of performance for an individual. We show that the model trained on a group mean performs similarly to an individual model in the CWI task, while achieving good LCP performance for an individual is difficult. We also experiment with adapting a finetuned BERT model, which results only in marginal improvements across all settings.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
Beyond Film Subtitles: Is YouTube the Best Approximation of Spoken Vocabulary?
Oct 04, 2024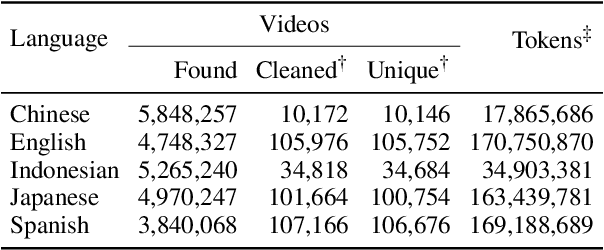
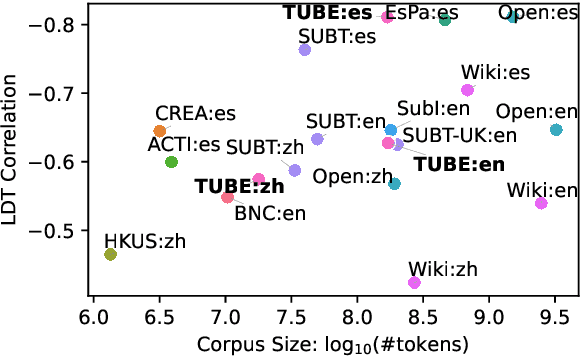
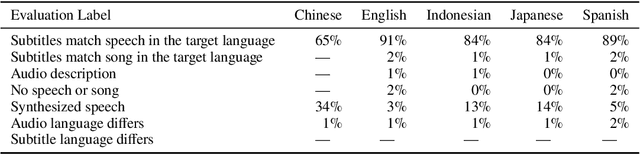
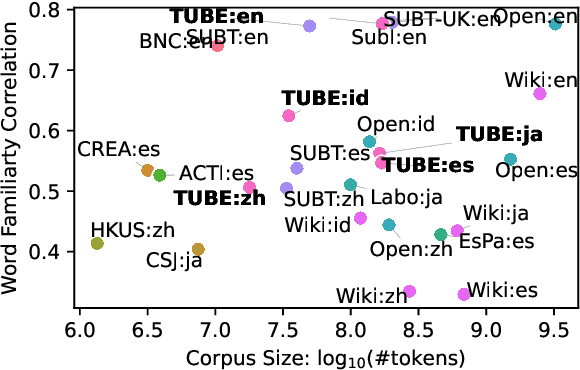
Word frequency is a key variable in psycholinguistics, useful for modeling human familiarity with words even in the era of large language models (LLMs). Frequency in film subtitles has proved to be a particularly good approximation of everyday language exposure. For many languages, however, film subtitles are not easily available, or are overwhelmingly translated from English. We demonstrate that frequencies extracted from carefully processed YouTube subtitles provide an approximation comparable to, and often better than, the best currently available resources. Moreover, they are available for languages for which a high-quality subtitle or speech corpus does not exist. We use YouTube subtitles to construct frequency norms for five diverse languages, Chinese, English, Indonesian, Japanese, and Spanish, and evaluate their correlation with lexical decision time, word familiarity, and lexical complexity. In addition to being strongly correlated with two psycholinguistic variables, a simple linear regression on the new frequencies achieves a new high score on a lexical complexity prediction task in English and Japanese, surpassing both models trained on film subtitle frequencies and the LLM GPT-4. Our code, the frequency lists, fastText word embeddings, and statistical language models are freely available at https://github.com/naist-nlp/tubelex.
Toward the Evaluation of Large Language Models Considering Score Variance across Instruction Templates
Aug 22, 2024



The natural language understanding (NLU) performance of large language models (LLMs) has been evaluated across various tasks and datasets. The existing evaluation methods, however, do not take into account the variance in scores due to differences in prompts, which leads to unfair evaluation and comparison of NLU performance. Moreover, evaluation designed for specific prompts is inappropriate for instruction tuning, which aims to perform well with any prompt. It is therefore necessary to find a way to measure NLU performance in a fair manner, considering score variance between different instruction templates. In this study, we provide English and Japanese cross-lingual datasets for evaluating the NLU performance of LLMs, which include multiple instruction templates for fair evaluation of each task, along with regular expressions to constrain the output format. Furthermore, we propose the Sharpe score as an evaluation metric that takes into account the variance in scores between templates. Comprehensive analysis of English and Japanese LLMs reveals that the high variance among templates has a significant impact on the fair evaluation of LLMs.
Japanese Lexical Complexity for Non-Native Readers: A New Dataset
Jun 30, 2023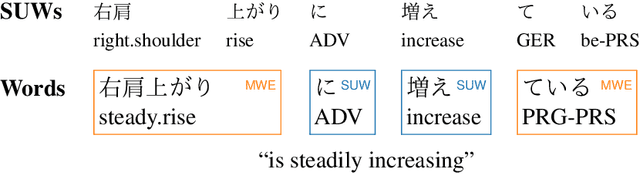

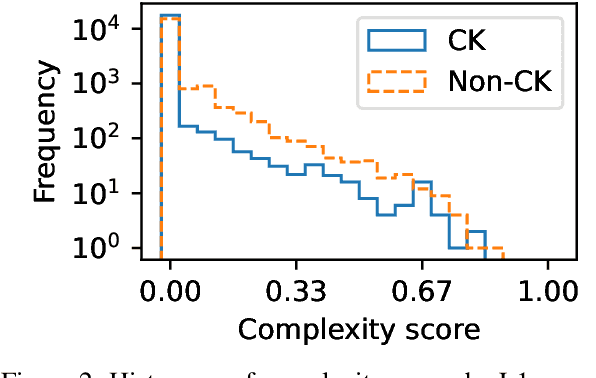
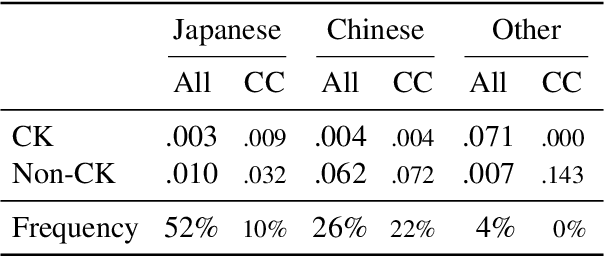
Lexical complexity prediction (LCP) is the task of predicting the complexity of words in a text on a continuous scale. It plays a vital role in simplifying or annotating complex words to assist readers. To study lexical complexity in Japanese, we construct the first Japanese LCP dataset. Our dataset provides separate complexity scores for Chinese/Korean annotators and others to address the readers' L1-specific needs. In the baseline experiment, we demonstrate the effectiveness of a BERT-based system for Japanese LCP.