Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDispersion Measures as Predictors of Lexical Decision Time, Word Familiarity, and Lexical Complexity
Paper and Code
Jan 11, 2025
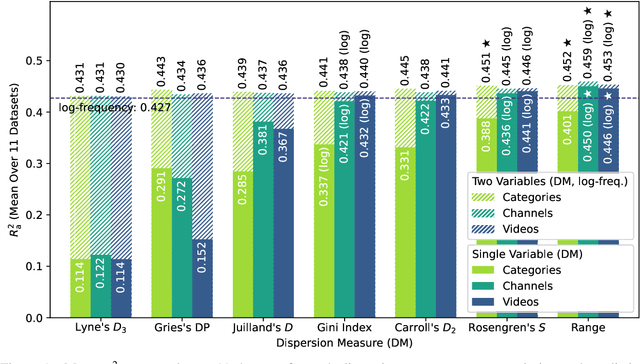
Various measures of dispersion have been proposed to paint a fuller picture of a word's distribution in a corpus, but only little has been done to validate them externally. We evaluate a wide range of dispersion measures as predictors of lexical decision time, word familiarity, and lexical complexity in five diverse languages. We find that the logarithm of range is not only a better predictor than log-frequency across all tasks and languages, but that it is also the most powerful additional variable to log-frequency, consistently outperforming the more complex dispersion measures. We discuss the effects of corpus part granularity and logarithmic transformation, shedding light on contradictory results of previous studies.
* Pre-print, to be presented at the NLP Meeting 2025 (www.anlp.jp -
NON-REVIEWED)
View paper on