 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Lexicography: Generating and Evaluating Definitions for Learner's Dictionaries
Jan 05, 2026We study dictionary definition generation (DDG), i.e., the generation of non-contextualized definitions for given headwords. Dictionary definitions are an essential resource for learning word senses, but manually creating them is costly, which motivates us to automate the process. Specifically, we address learner's dictionary definition generation (LDDG), where definitions should consist of simple words. First, we introduce a reliable evaluation approach for DDG, based on our new evaluation criteria and powered by an LLM-as-a-judge. To provide reference definitions for the evaluation, we also construct a Japanese dataset in collaboration with a professional lexicographer. Validation results demonstrate that our evaluation approach agrees reasonably well with human annotators. Second, we propose an LDDG approach via iterative simplification with an LLM. Experimental results indicate that definitions generated by our approach achieve high scores on our criteria while maintaining lexical simplicity.
CoAM: Corpus of All-Type Multiword Expressions
Dec 24, 2024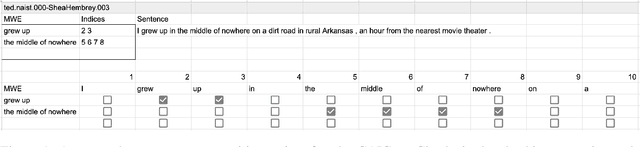


Multiword expressions (MWEs) refer to idiomatic sequences of multiple words. MWE identification, i.e., detecting MWEs in text, can play a key role in downstream tasks such as machine translation. Existing datasets for MWE identification are inconsistently annotated, limited to a single type of MWE, or limited in size. To enable reliable and comprehensive evaluation, we created CoAM: Corpus of All-Type Multiword Expressions, a dataset of 1.3K sentences constructed through a multi-step process to enhance data quality consisting of human annotation, human review, and automated consistency checking. MWEs in CoAM are tagged with MWE types, such as Noun and Verb, to enable fine-grained error analysis. Annotations for CoAM were collected using a new interface created with our interface generator, which allows easy and flexible annotation of MWEs in any form, including discontinuous ones. Through experiments using CoAM, we find that a fine-tuned large language model outperforms the current state-of-the-art approach for MWE identification. Furthermore, analysis using our MWE type tagged data reveals that Verb MWEs are easier than Noun MWEs to identify across approaches.
Difficult for Whom? A Study of Japanese Lexical Complexity
Oct 24, 2024The tasks of lexical complexity prediction (LCP) and complex word identification (CWI) commonly presuppose that difficult to understand words are shared by the target population. Meanwhile, personalization methods have also been proposed to adapt models to individual needs. We verify that a recent Japanese LCP dataset is representative of its target population by partially replicating the annotation. By another reannotation we show that native Chinese speakers perceive the complexity differently due to Sino-Japanese vocabulary. To explore the possibilities of personalization, we compare competitive baselines trained on the group mean ratings and individual ratings in terms of performance for an individual. We show that the model trained on a group mean performs similarly to an individual model in the CWI task, while achieving good LCP performance for an individual is difficult. We also experiment with adapting a finetuned BERT model, which results only in marginal improvements across all settings.
How to Make the Most of LLMs' Grammatical Knowledge for Acceptability Judgments
Aug 19, 2024



The grammatical knowledge of language models (LMs) is often measured using a benchmark of linguistic minimal pairs, where LMs are presented with a pair of acceptable and unacceptable sentences and required to judge which is acceptable. The existing dominant approach, however, naively calculates and compares the probabilities of paired sentences using LMs. Additionally, large language models (LLMs) have yet to be thoroughly examined in this field. We thus investigate how to make the most of LLMs' grammatical knowledge to comprehensively evaluate it. Through extensive experiments of nine judgment methods in English and Chinese, we demonstrate that a probability readout method, in-template LP, and a prompting-based method, Yes/No probability computing, achieve particularly high performance, surpassing the conventional approach. Our analysis reveals their different strengths, e.g., Yes/No probability computing is robust against token-length bias, suggesting that they harness different aspects of LLMs' grammatical knowledge. Consequently, we recommend using diverse judgment methods to evaluate LLMs comprehensively.
Evaluating Image Review Ability of Vision Language Models
Feb 19, 2024Large-scale vision language models (LVLMs) are language models that are capable of processing images and text inputs by a single model. This paper explores the use of LVLMs to generate review texts for images. The ability of LVLMs to review images is not fully understood, highlighting the need for a methodical evaluation of their review abilities. Unlike image captions, review texts can be written from various perspectives such as image composition and exposure. This diversity of review perspectives makes it difficult to uniquely determine a single correct review for an image. To address this challenge, we introduce an evaluation method based on rank correlation analysis, in which review texts are ranked by humans and LVLMs, then, measures the correlation between these rankings. We further validate this approach by creating a benchmark dataset aimed at assessing the image review ability of recent LVLMs. Our experiments with the dataset reveal that LVLMs, particularly those with proven superiority in other evaluative contexts, excel at distinguishing between high-quality and substandard image reviews.
Japanese Lexical Complexity for Non-Native Readers: A New Dataset
Jun 30, 2023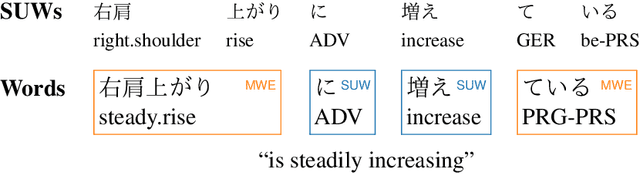

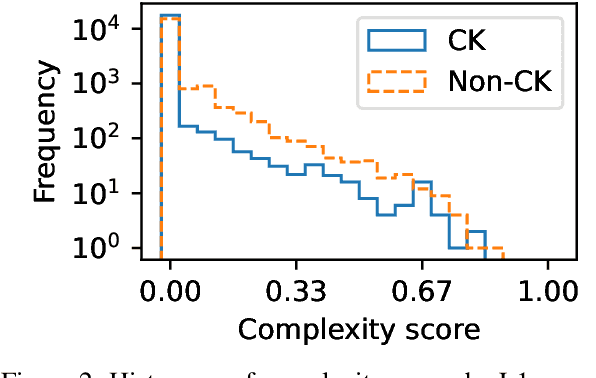
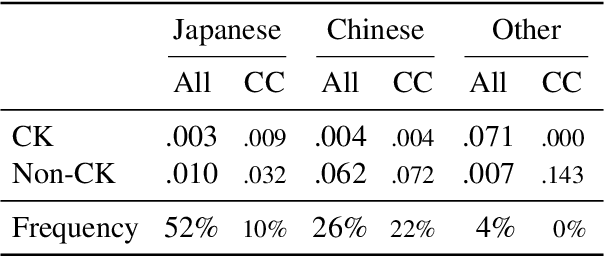
Lexical complexity prediction (LCP) is the task of predicting the complexity of words in a text on a continuous scale. It plays a vital role in simplifying or annotating complex words to assist readers. To study lexical complexity in Japanese, we construct the first Japanese LCP dataset. Our dataset provides separate complexity scores for Chinese/Korean annotators and others to address the readers' L1-specific needs. In the baseline experiment, we demonstrate the effectiveness of a BERT-based system for Japanese LCP.
Arukikata Travelogue Dataset with Geographic Entity Mention, Coreference, and Link Annotation
May 23, 2023
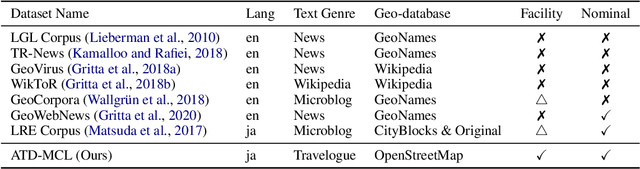
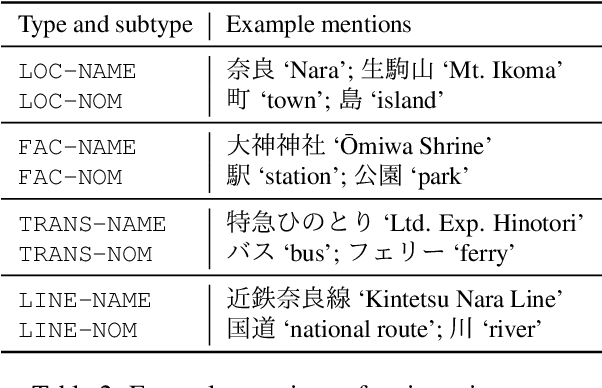

Geoparsing is a fundamental technique for analyzing geo-entity information in text. We focus on document-level geoparsing, which considers geographic relatedness among geo-entity mentions, and presents a Japanese travelogue dataset designed for evaluating document-level geoparsing systems. Our dataset comprises 200 travelogue documents with rich geo-entity information: 12,171 mentions, 6,339 coreference clusters, and 2,551 geo-entities linked to geo-database entries.