 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Vision Language Models' Perception by Leveraging Human Methods for Color Vision Deficiencies
May 23, 2025Large-scale Vision Language Models (LVLMs) are increasingly being applied to a wide range of real-world multimodal applications, involving complex visual and linguistic reasoning. As these models become more integrated into practical use, they are expected to handle complex aspects of human interaction. Among these, color perception is a fundamental yet highly variable aspect of visual understanding. It differs across individuals due to biological factors such as Color Vision Deficiencies (CVDs), as well as differences in culture and language. Despite its importance, perceptual diversity has received limited attention. In our study, we evaluate LVLMs' ability to account for individual level perceptual variation using the Ishihara Test, a widely used method for detecting CVDs. Our results show that LVLMs can explain CVDs in natural language, but they cannot simulate how people with CVDs perceive color in image based tasks. These findings highlight the need for multimodal systems that can account for color perceptual diversity and support broader discussions on perceptual inclusiveness and fairness in multimodal AI.
IterKey: Iterative Keyword Generation with LLMs for Enhanced Retrieval Augmented Generation
May 13, 2025



Retrieval-Augmented Generation (RAG) has emerged as a way to complement the in-context knowledge of Large Language Models (LLMs) by integrating external documents. However, real-world applications demand not only accuracy but also interpretability. While dense retrieval methods provide high accuracy, they lack interpretability; conversely, sparse retrieval methods offer transparency but often fail to capture the full intent of queries due to their reliance on keyword matching. To address these issues, we introduce IterKey, an LLM-driven iterative keyword generation framework that enhances RAG via sparse retrieval. IterKey consists of three LLM-driven stages: generating keywords for retrieval, generating answers based on retrieved documents, and validating the answers. If validation fails, the process iteratively repeats with refined keywords. Across four QA tasks, experimental results show that IterKey achieves 5% to 20% accuracy improvements over BM25-based RAG and simple baselines. Its performance is comparable to dense retrieval-based RAG and prior iterative query refinement methods using dense models. In summary, IterKey is a novel BM25-based approach leveraging LLMs to iteratively refine RAG, effectively balancing accuracy with interpretability.
TextTIGER: Text-based Intelligent Generation with Entity Prompt Refinement for Text-to-Image Generation
Apr 25, 2025



Generating images from prompts containing specific entities requires models to retain as much entity-specific knowledge as possible. However, fully memorizing such knowledge is impractical due to the vast number of entities and their continuous emergence. To address this, we propose Text-based Intelligent Generation with Entity prompt Refinement (TextTIGER), which augments knowledge on entities included in the prompts and then summarizes the augmented descriptions using Large Language Models (LLMs) to mitigate performance degradation from longer inputs. To evaluate our method, we introduce WiT-Cub (WiT with Captions and Uncomplicated Background-explanations), a dataset comprising captions, images, and an entity list. Experiments on four image generation models and five LLMs show that TextTIGER improves image generation performance in standard metrics (IS, FID, and CLIPScore) compared to caption-only prompts. Additionally, multiple annotators' evaluation confirms that the summarized descriptions are more informative, validating LLMs' ability to generate concise yet rich descriptions. These findings demonstrate that refining prompts with augmented and summarized entity-related descriptions enhances image generation capabilities. The code and dataset will be available upon acceptance.
Understanding the Impact of Confidence in Retrieval Augmented Generation: A Case Study in the Medical Domain
Dec 29, 2024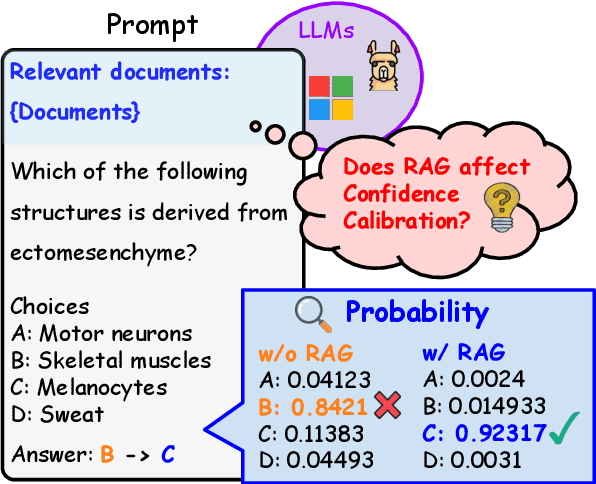



Retrieval Augmented Generation (RAG) complements the knowledge of Large Language Models (LLMs) by leveraging external information to enhance response accuracy for queries. This approach is widely applied in several fields by taking its advantage of injecting the most up-to-date information, and researchers are focusing on understanding and improving this aspect to unlock the full potential of RAG in such high-stakes applications. However, despite the potential of RAG to address these needs, the mechanisms behind the confidence levels of its outputs remain underexplored, although the confidence of information is very critical in some domains, such as finance, healthcare, and medicine. Our study focuses the impact of RAG on confidence within the medical domain under various configurations and models. We evaluate confidence by treating the model's predicted probability as its output and calculating Expected Calibration Error (ECE) and Adaptive Calibration Error (ACE) scores based on the probabilities and accuracy. In addition, we analyze whether the order of retrieved documents within prompts calibrates the confidence. Our findings reveal large variation in confidence and accuracy depending on the model, settings, and the format of input prompts. These results underscore the necessity of optimizing configurations based on the specific model and conditions.
Topology optimization of periodic lattice structures for specified mechanical properties using machine learning considering member connectivity
Nov 21, 2024



This study proposes a methodology to utilize machine learning (ML) for topology optimization of periodic lattice structures. In particular, we investigate data representation of lattice structures used as input data for ML models to improve the performance of the models, focusing on the filtering process and feature selection. We use the filtering technique to explicitly consider the connectivity of lattice members and perform feature selection to reduce the input data size. In addition, we propose a convolution approach to apply pre-trained models for small structures to structures of larger sizes. The computational cost for obtaining optimal topologies by a heuristic method is reduced by incorporating the prediction of the trained ML model into the optimization process. In the numerical examples, a response prediction model is constructed for a lattice structure of 4x4 units, and topology optimization of 4x4-unit and 8x8-unit structures is performed by simulated annealing assisted by the trained ML model. The example demonstrates that ML models perform higher accuracy by using the filtered data as input than by solely using the data representing the existence of each member. It is also demonstrated that a small-scale prediction model can be constructed with sufficient accuracy by feature selection. Additionally, the proposed method can find the optimal structure in less computation time than the pure simulated annealing.
BQA: Body Language Question Answering Dataset for Video Large Language Models
Oct 17, 2024



A large part of human communication relies on nonverbal cues such as facial expressions, eye contact, and body language. Unlike language or sign language, such nonverbal communication lacks formal rules, requiring complex reasoning based on commonsense understanding. Enabling current Video Large Language Models (VideoLLMs) to accurately interpret body language is a crucial challenge, as human unconscious actions can easily cause the model to misinterpret their intent. To address this, we propose a dataset, BQA, a body language question answering dataset, to validate whether the model can correctly interpret emotions from short clips of body language comprising 26 emotion labels of videos of body language. We evaluated various VideoLLMs on BQA and revealed that understanding body language is challenging, and our analyses of the wrong answers by VideoLLMs show that certain VideoLLMs made significantly biased answers depending on the age group and ethnicity of the individuals in the video. The dataset is available.
Towards Cross-Lingual Explanation of Artwork in Large-scale Vision Language Models
Sep 03, 2024



As the performance of Large-scale Vision Language Models (LVLMs) improves, they are increasingly capable of responding in multiple languages, and there is an expectation that the demand for explanations generated by LVLMs will grow. However, pre-training of Vision Encoder and the integrated training of LLMs with Vision Encoder are mainly conducted using English training data, leaving it uncertain whether LVLMs can completely handle their potential when generating explanations in languages other than English. In addition, multilingual QA benchmarks that create datasets using machine translation have cultural differences and biases, remaining issues for use as evaluation tasks. To address these challenges, this study created an extended dataset in multiple languages without relying on machine translation. This dataset that takes into account nuances and country-specific phrases was then used to evaluate the generation explanation abilities of LVLMs. Furthermore, this study examined whether Instruction-Tuning in resource-rich English improves performance in other languages. Our findings indicate that LVLMs perform worse in languages other than English compared to English. In addition, it was observed that LVLMs struggle to effectively manage the knowledge learned from English data.
Artwork Explanation in Large-scale Vision Language Models
Feb 29, 2024



Large-scale vision-language models (LVLMs) output text from images and instructions, demonstrating advanced capabilities in text generation and comprehension. However, it has not been clarified to what extent LVLMs understand the knowledge necessary for explaining images, the complex relationships between various pieces of knowledge, and how they integrate these understandings into their explanations. To address this issue, we propose a new task: the artwork explanation generation task, along with its evaluation dataset and metric for quantitatively assessing the understanding and utilization of knowledge about artworks. This task is apt for image description based on the premise that LVLMs are expected to have pre-existing knowledge of artworks, which are often subjects of wide recognition and documented information. It consists of two parts: generating explanations from both images and titles of artworks, and generating explanations using only images, thus evaluating the LVLMs' language-based and vision-based knowledge. Alongside, we release a training dataset for LVLMs to learn explanations that incorporate knowledge about artworks. Our findings indicate that LVLMs not only struggle with integrating language and visual information but also exhibit a more pronounced limitation in acquiring knowledge from images alone. The datasets (ExpArt=Explain Artworks) are available at https://huggingface.co/datasets/naist-nlp/ExpArt.
Evaluating Image Review Ability of Vision Language Models
Feb 19, 2024Large-scale vision language models (LVLMs) are language models that are capable of processing images and text inputs by a single model. This paper explores the use of LVLMs to generate review texts for images. The ability of LVLMs to review images is not fully understood, highlighting the need for a methodical evaluation of their review abilities. Unlike image captions, review texts can be written from various perspectives such as image composition and exposure. This diversity of review perspectives makes it difficult to uniquely determine a single correct review for an image. To address this challenge, we introduce an evaluation method based on rank correlation analysis, in which review texts are ranked by humans and LVLMs, then, measures the correlation between these rankings. We further validate this approach by creating a benchmark dataset aimed at assessing the image review ability of recent LVLMs. Our experiments with the dataset reveal that LVLMs, particularly those with proven superiority in other evaluative contexts, excel at distinguishing between high-quality and substandard image reviews.
An Independently Learnable Hierarchical Model for Bilateral Control-Based Imitation Learning Applications
Mar 16, 2022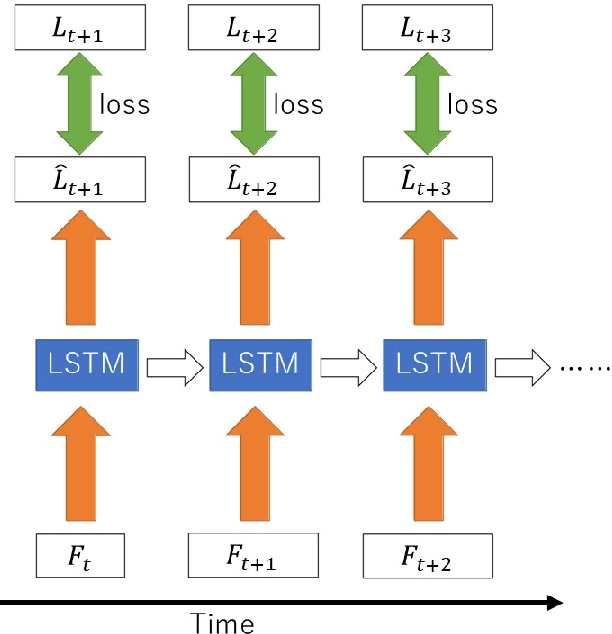

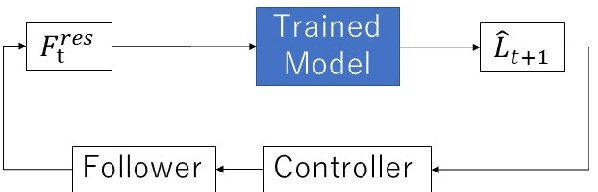

Recently, motion generation by machine learning has been actively researched to automate various tasks. Imitation learning is one such method that learns motions from data collected in advance. However, executing long-term tasks remains challenging. Therefore, a novel framework for imitation learning is proposed to solve this problem. The proposed framework comprises upper and lower layers, where the upper layer model, whose timescale is long, and lower layer model, whose timescale is short, can be independently trained. In this model, the upper layer learns long-term task planning, and the lower layer learns motion primitives. The proposed method was experimentally compared to hierarchical RNN-based methods to validate its effectiveness. Consequently, the proposed method showed a success rate equal to or greater than that of conventional methods. In addition, the proposed method required less than 1/20 of the training time compared to conventional methods. Moreover, it succeeded in executing unlearned tasks by reusing the trained lower layer.