 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and Diverse Recommendations via Propensity-Weighted Linear Autoencoders
Dec 24, 2025In real-world recommender systems, user-item interactions are Missing Not At Random (MNAR), as interactions with popular items are more frequently observed than those with less popular ones. Missing observations shift recommendations toward frequently interacted items, which reduces the diversity of the recommendation list. To alleviate this problem, Inverse Propensity Scoring (IPS) is widely used and commonly models propensities based on a power-law function of item interaction frequency. However, we found that such power-law-based correction overly penalizes popular items and harms their recommendation performance. We address this issue by redefining the propensity score to allow broader item recommendation without excessively penalizing popular items. The proposed score is formulated by applying a sigmoid function to the logarithm of the item observation frequency, maintaining the simplicity of power-law scoring while allowing for more flexible adjustment. Furthermore, we incorporate the redefined propensity score into a linear autoencoder model, which tends to favor popular items, and evaluate its effectiveness. Experimental results revealed that our method substantially improves the diversity of items in the recommendation list without sacrificing recommendation accuracy.
* Published in the proceedings of SIGIR-AP'25
A Simple but Effective Closed-form Solution for Extreme Multi-label Learning
Jan 17, 2025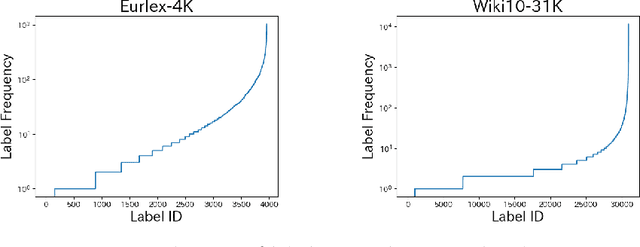
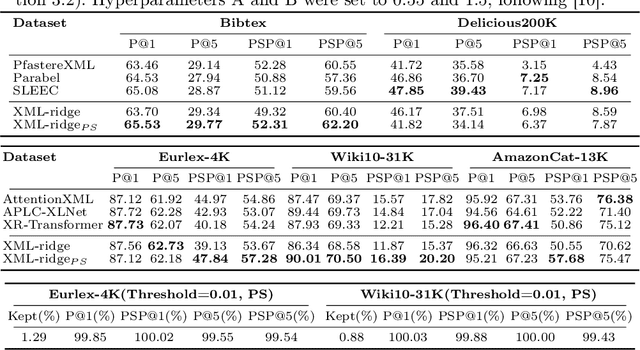
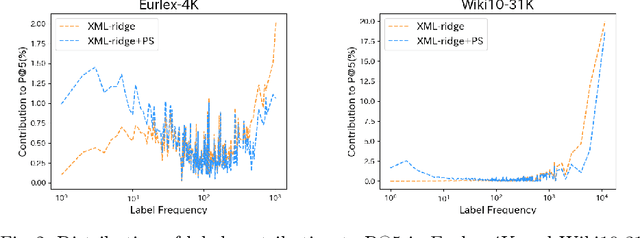
Extreme multi-label learning (XML) is a task of assigning multiple labels from an extremely large set of labels to each data instance. Many current high-performance XML models are composed of a lot of hyperparameters, which complicates the tuning process. Additionally, the models themselves are adapted specifically to XML, which complicates their reimplementation. To remedy this problem, we propose a simple method based on ridge regression for XML. The proposed method not only has a closed-form solution but also is composed of a single hyperparameter. Since there are no precedents on applying ridge regression to XML, this paper verified the performance of the method by using various XML benchmark datasets. Furthermore, we enhanced the prediction of low-frequency labels in XML, which hold informative content. This prediction is essential yet challenging because of the limited amount of data. Here, we employed a simple frequency-based weighting. This approach greatly simplifies the process compared with existing techniques. Experimental results revealed that it can achieve levels of performance comparable to, or even exceeding, those of models with numerous hyperparameters. Additionally, we found that the frequency-based weighting significantly improved the predictive performance for low-frequency labels, while requiring almost no changes in implementation. The source code for the proposed method is available on github at https://github.com/cars1015/XML-ridge.
Multi-label Learning with Random Circular Vectors
Jul 08, 2024The extreme multi-label classification~(XMC) task involves learning a classifier that can predict from a large label set the most relevant subset of labels for a data instance. While deep neural networks~(DNNs) have demonstrated remarkable success in XMC problems, the task is still challenging because it must deal with a large number of output labels, which make the DNN training computationally expensive. This paper addresses the issue by exploring the use of random circular vectors, where each vector component is represented as a complex amplitude. In our framework, we can develop an output layer and loss function of DNNs for XMC by representing the final output layer as a fully connected layer that directly predicts a low-dimensional circular vector encoding a set of labels for a data instance. We conducted experiments on synthetic datasets to verify that circular vectors have better label encoding capacity and retrieval ability than normal real-valued vectors. Then, we conducted experiments on actual XMC datasets and found that these appealing properties of circular vectors contribute to significant improvements in task performance compared with a previous model using random real-valued vectors, while reducing the size of the output layers by up to 99%.
Evaluating Image Review Ability of Vision Language Models
Feb 19, 2024Large-scale vision language models (LVLMs) are language models that are capable of processing images and text inputs by a single model. This paper explores the use of LVLMs to generate review texts for images. The ability of LVLMs to review images is not fully understood, highlighting the need for a methodical evaluation of their review abilities. Unlike image captions, review texts can be written from various perspectives such as image composition and exposure. This diversity of review perspectives makes it difficult to uniquely determine a single correct review for an image. To address this challenge, we introduce an evaluation method based on rank correlation analysis, in which review texts are ranked by humans and LVLMs, then, measures the correlation between these rankings. We further validate this approach by creating a benchmark dataset aimed at assessing the image review ability of recent LVLMs. Our experiments with the dataset reveal that LVLMs, particularly those with proven superiority in other evaluative contexts, excel at distinguishing between high-quality and substandard image reviews.
Implicit ZCA Whitening Effects of Linear Autoencoders for Recommendation
Aug 15, 2023Recently, in the field of recommendation systems, linear regression (autoencoder) models have been investigated as a way to learn item similarity. In this paper, we show a connection between a linear autoencoder model and ZCA whitening for recommendation data. In particular, we show that the dual form solution of a linear autoencoder model actually has ZCA whitening effects on feature vectors of items, while items are considered as input features in the primal problem of the autoencoder/regression model. We also show the correctness of applying a linear autoencoder to low-dimensional item vectors obtained using embedding methods such as Item2vec to estimate item-item similarities. Our experiments provide preliminary results indicating the effectiveness of whitening low-dimensional item embeddings.