 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructuring Quantitative Image Analysis with Object Prominence
Aug 30, 2024When photographers and other editors of image material produce an image, they make a statement about what matters by situating some objects in the foreground and others in the background. While this prominence of objects is a key analytical category to qualitative scholars, recent quantitative approaches to automated image analysis have not yet made this important distinction but treat all areas of an image similarly. We suggest carefully considering objects' prominence as an essential step in analyzing images as data. Its modeling requires defining an object and operationalizing and measuring how much attention a human eye would pay. Our approach combines qualitative analyses with the scalability of quantitative approaches. Exemplifying object prominence with different implementations -- object size and centeredness, the pixels' image depth, and salient image regions -- we showcase the usefulness of our approach with two applications. First, we scale the ideology of eight US newspapers based on images. Second, we analyze the prominence of women in the campaign videos of the U.S. presidential races in 2016 and 2020. We hope that our article helps all keen to study image data in a conceptually meaningful way at scale.
Words as Trigger Points in Social Media Discussions
May 16, 2024



Trigger points are a concept introduced by Mau, Lux, and Westheuser (2023) to study qualitative focus group interviews and understand polarisation in Germany. When people communicate, trigger points represent moments when individuals feel that their understanding of what is fair, normal, or appropriate in society is questioned. In the original studies, individuals react affectively to such triggers and show strong and negative emotional responses. In this paper, we introduce the first systematic study of the large-scale effect of individual words as trigger points by analysing a large amount of social media posts. We examine online deliberations on Reddit between 2020 and 2022 and collect >100 million posts from subreddits related to a set of words identified as trigger points in UK politics. We find that such trigger words affect user engagement and have noticeable consequences on animosity in online discussions. We share empirical evidence of trigger words causing animosity, and how they provide incentives for hate speech, adversarial debates, and disagreements. Our work is the first to introduce trigger points to computational studies of online communication. Our findings are relevant to researchers interested in online harms and who examine how citizens debate politics and society in light of affective polarisation.
How Alignment Helps Make the Most of Multimodal Data
May 14, 2024



When studying political communication, combining the information from text, audio, and video signals promises to reflect the richness of human communication more comprehensively than confining it to individual modalities alone. However, when modeling such multimodal data, its heterogeneity, connectedness, and interaction are challenging to address. We argue that aligning the respective modalities can be an essential step in entirely using the potential of multimodal data because it informs the model with human understanding. Exploring aligned modalities unlocks promising analytical leverage. First, it allows us to make the most of information in the data, which inter alia opens the door to better quality predictions. Second, it is possible to answer research questions that span multiple modalities with cross-modal queries. Finally, alignment addresses concerns about model interpretability. We illustrate the utility of this approach by analyzing how German MPs address members of the far-right AfD in their speeches, and predicting the tone of video advertising in the context of the 2020 US presidential race. Our paper offers important insights to all keen to analyze multimodal data effectively.
Really Useful Synthetic Data -- A Framework to Evaluate the Quality of Differentially Private Synthetic Data
Apr 16, 2020
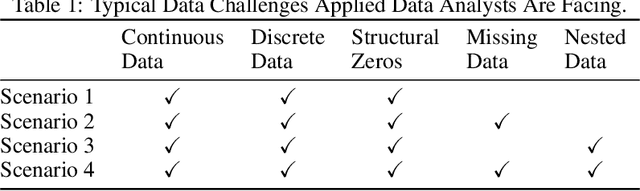
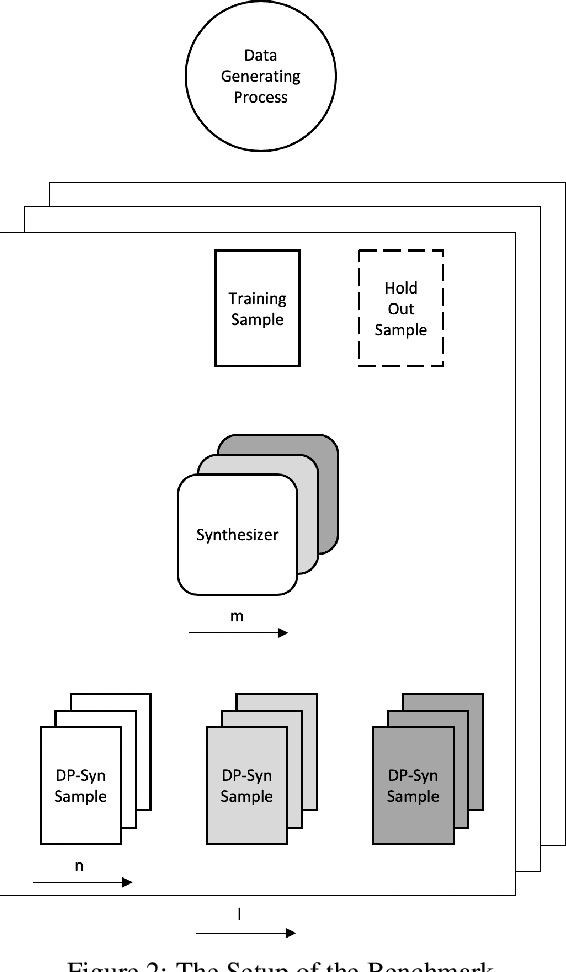
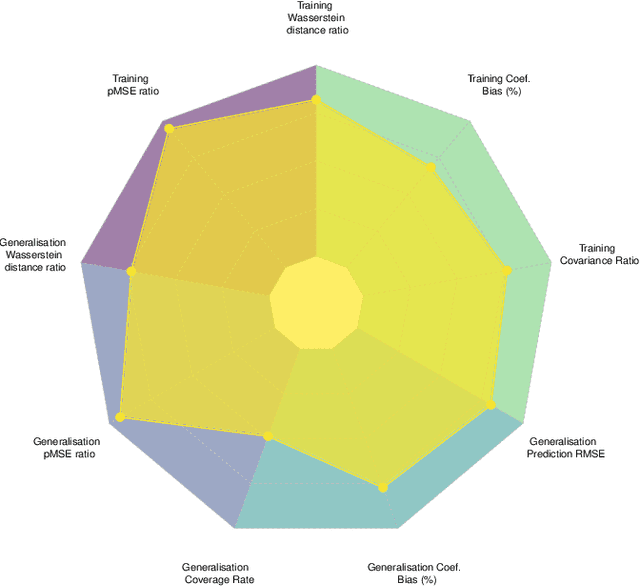
Recent advances in generating synthetic data that allow to add principled ways of protecting privacy -- such as Differential Privacy -- are a crucial step in sharing statistical information in a privacy preserving way. But while the focus has been on privacy guarantees, the resulting private synthetic data is only useful if it still carries statistical information from the original data. To further optimise the inherent trade-off between data privacy and data quality, it is necessary to think closely about the latter. What is it that data analysts want? Acknowledging that data quality is a subjective concept, we develop a framework to evaluate the quality of differentially private synthetic data from an applied researcher's perspective. Data quality can be measured along two dimensions. First, quality of synthetic data can be evaluated against training data or against an underlying population. Second, the quality of synthetic data depends on general similarity of distributions or specific tasks such as inference or prediction. It is clear that accommodating all goals at once is a formidable challenge. We invite the academic community to jointly advance the privacy-quality frontier.