 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Post-GAN Boosting
Jul 23, 2020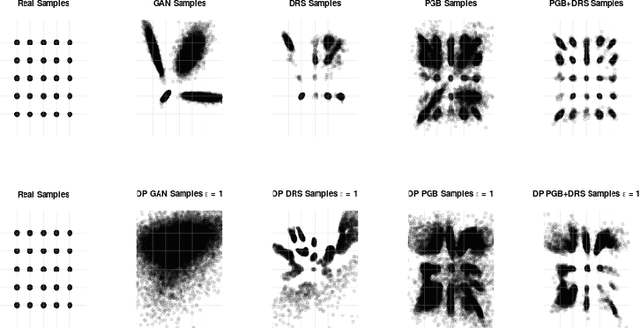
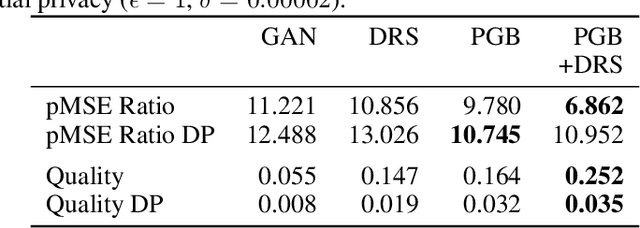
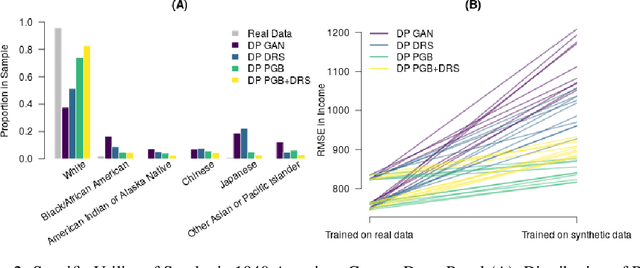
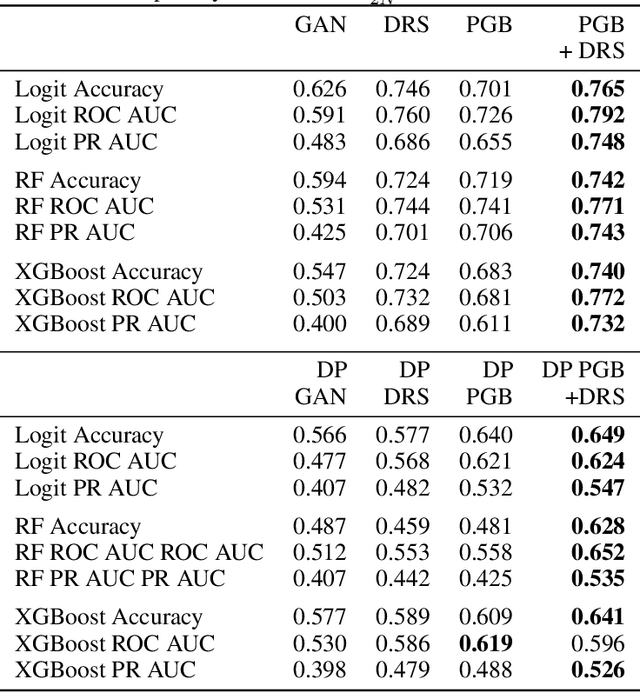
Differentially private GANs have proven to be a promising approach for generating realistic synthetic data without compromising the privacy of individuals. However, due to the privacy-protective noise introduced in the training, the convergence of GANs becomes even more elusive, which often leads to poor utility in the output generator at the end of training. We propose Private post-GAN boosting (Private PGB), a differentially private method that combines samples produced by the sequence of generators obtained during GAN training to create a high-quality synthetic dataset. Our method leverages the Private Multiplicative Weights method (Hardt and Rothblum, 2010) and the discriminator rejection sampling technique (Azadi et al., 2019) for reweighting generated samples, to obtain high quality synthetic data even in cases where GAN training does not converge. We evaluate Private PGB on a Gaussian mixture dataset and two US Census datasets, and demonstrate that Private PGB improves upon the standard private GAN approach across a collection of quality measures. Finally, we provide a non-private variant of PGB that improves the data quality of standard GAN training.
Really Useful Synthetic Data -- A Framework to Evaluate the Quality of Differentially Private Synthetic Data
Apr 16, 2020
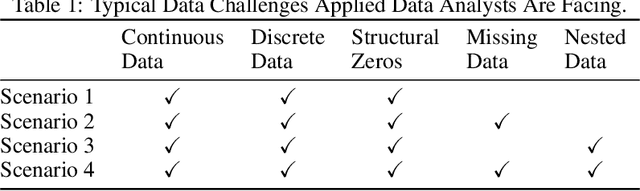
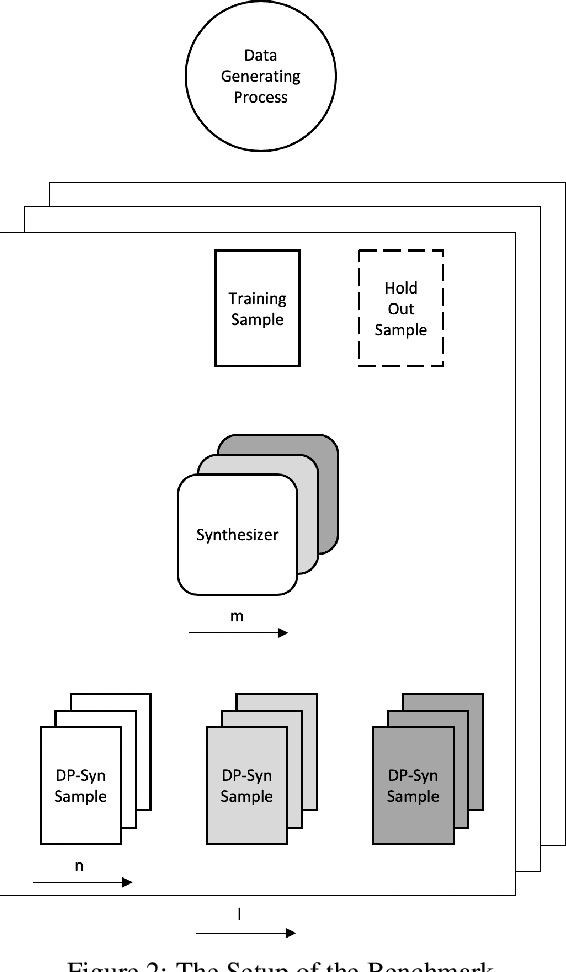
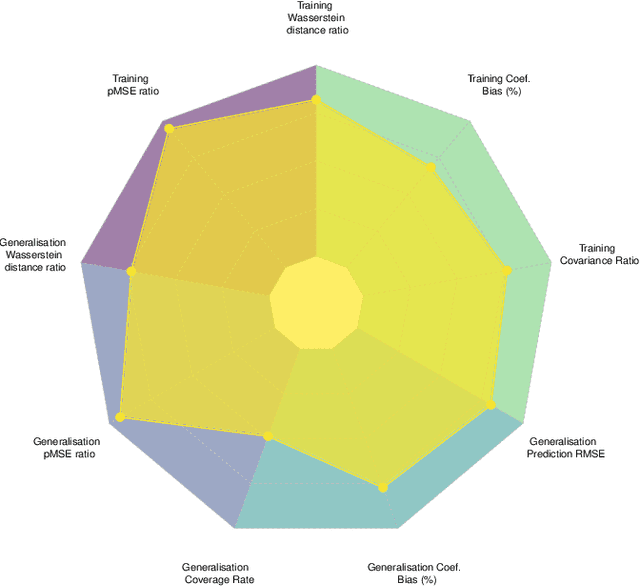
Recent advances in generating synthetic data that allow to add principled ways of protecting privacy -- such as Differential Privacy -- are a crucial step in sharing statistical information in a privacy preserving way. But while the focus has been on privacy guarantees, the resulting private synthetic data is only useful if it still carries statistical information from the original data. To further optimise the inherent trade-off between data privacy and data quality, it is necessary to think closely about the latter. What is it that data analysts want? Acknowledging that data quality is a subjective concept, we develop a framework to evaluate the quality of differentially private synthetic data from an applied researcher's perspective. Data quality can be measured along two dimensions. First, quality of synthetic data can be evaluated against training data or against an underlying population. Second, the quality of synthetic data depends on general similarity of distributions or specific tasks such as inference or prediction. It is clear that accommodating all goals at once is a formidable challenge. We invite the academic community to jointly advance the privacy-quality frontier.