 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINEST: Improving LLM Responses to Sensitive Topics Through Fine-Grained Evaluation
Mar 04, 2026Large Language Models (LLMs) often generate overly cautious and vague responses on sensitive topics, sacrificing helpfulness for safety. Existing evaluation frameworks lack systematic methods to identify and address specific weaknesses in responses to sensitive topics, making it difficult to improve both safety and helpfulness simultaneously. To address this, we introduce FINEST, a FINE-grained response evaluation taxonomy for Sensitive Topics, which breaks down helpfulness and harmlessness into errors across three main categories: Content, Logic, and Appropriateness. Experiments on a Korean-sensitive question dataset demonstrate that our score- and error-based improvement pipeline, guided by FINEST, significantly improves the model responses across all three categories, outperforming refinement without guidance. Notably, score-based improvement -- providing category-specific scores and justifications -- yields the most significant gains, reducing the error sentence ratio for Appropriateness by up to 33.09%. This work lays the foundation for a more explainable and comprehensive evaluation and improvement of LLM responses to sensitive questions.
Entangled in Representations: Mechanistic Investigation of Cultural Biases in Large Language Models
Aug 12, 2025The growing deployment of large language models (LLMs) across diverse cultural contexts necessitates a better understanding of how the overgeneralization of less documented cultures within LLMs' representations impacts their cultural understanding. Prior work only performs extrinsic evaluation of LLMs' cultural competence, without accounting for how LLMs' internal mechanisms lead to cultural (mis)representation. To bridge this gap, we propose Culturescope, the first mechanistic interpretability-based method that probes the internal representations of LLMs to elicit the underlying cultural knowledge space. CultureScope utilizes a patching method to extract the cultural knowledge. We introduce a cultural flattening score as a measure of the intrinsic cultural biases. Additionally, we study how LLMs internalize Western-dominance bias and cultural flattening, which allows us to trace how cultural biases emerge within LLMs. Our experimental results reveal that LLMs encode Western-dominance bias and cultural flattening in their cultural knowledge space. We find that low-resource cultures are less susceptible to cultural biases, likely due to their limited training resources. Our work provides a foundation for future research on mitigating cultural biases and enhancing LLMs' cultural understanding. Our codes and data used for experiments are publicly available.
MUG-Eval: A Proxy Evaluation Framework for Multilingual Generation Capabilities in Any Language
May 20, 2025Evaluating text generation capabilities of large language models (LLMs) is challenging, particularly for low-resource languages where methods for direct assessment are scarce. We propose MUG-Eval, a novel framework that evaluates LLMs' multilingual generation capabilities by transforming existing benchmarks into conversational tasks and measuring the LLMs' accuracies on those tasks. We specifically designed these conversational tasks to require effective communication in the target language. Then, we simply use task success rate as a proxy of successful conversation generation. Our approach offers two key advantages: it is independent of language-specific NLP tools or annotated datasets, which are limited for most languages, and it does not rely on LLMs-as-judges, whose evaluation quality degrades outside a few high-resource languages. We evaluate 8 LLMs across 30 languages spanning high, mid, and low-resource categories, and we find that MUG-Eval correlates strongly with established benchmarks ($r$ > 0.75) while enabling standardized comparisons across languages and models. Our framework provides a robust and resource-efficient solution for evaluating multilingual generation that can be extended to thousands of languages.
Social Bias Benchmark for Generation: A Comparison of Generation and QA-Based Evaluations
Mar 10, 2025Measuring social bias in large language models (LLMs) is crucial, but existing bias evaluation methods struggle to assess bias in long-form generation. We propose a Bias Benchmark for Generation (BBG), an adaptation of the Bias Benchmark for QA (BBQ), designed to evaluate social bias in long-form generation by having LLMs generate continuations of story prompts. Building our benchmark in English and Korean, we measure the probability of neutral and biased generations across ten LLMs. We also compare our long-form story generation evaluation results with multiple-choice BBQ evaluation, showing that the two approaches produce inconsistent results.
HERITAGE: An End-to-End Web Platform for Processing Korean Historical Documents in Hanja
Jan 21, 2025



While Korean historical documents are invaluable cultural heritage, understanding those documents requires in-depth Hanja expertise. Hanja is an ancient language used in Korea before the 20th century, whose characters were borrowed from old Chinese but had evolved in Korea for centuries. Modern Koreans and Chinese cannot understand Korean historical documents without substantial additional help, and while previous efforts have produced some Korean and English translations, this requires in-depth expertise, and so most of the documents are not translated into any modern language. To address this gap, we present HERITAGE, the first open-source Hanja NLP toolkit to assist in understanding and translating the unexplored Korean historical documents written in Hanja. HERITAGE is a web-based platform providing model predictions of three critical tasks in historical document understanding via Hanja language models: punctuation restoration, named entity recognition, and machine translation (MT). HERITAGE also provides an interactive glossary, which provides the character-level reading of the Hanja characters in modern Korean, as well as character-level English definition. HERITAGE serves two purposes. First, anyone interested in these documents can get a general understanding from the model predictions and the interactive glossary, especially MT outputs in Korean and English. Second, since the model outputs are not perfect, Hanja experts can revise them to produce better annotations and translations. This would boost the translation efficiency and potentially lead to most of the historical documents being translated into modern languages, lowering the barrier on unexplored Korean historical documents.
When Does Classical Chinese Help? Quantifying Cross-Lingual Transfer in Hanja and Kanbun
Nov 07, 2024



Historical and linguistic connections within the Sinosphere have led researchers to use Classical Chinese resources for cross-lingual transfer when processing historical documents from Korea and Japan. In this paper, we question the assumption of cross-lingual transferability from Classical Chinese to Hanja and Kanbun, the ancient written languages of Korea and Japan, respectively. Our experiments across machine translation, named entity recognition, and punctuation restoration tasks show minimal impact of Classical Chinese datasets on language model performance for ancient Korean documents written in Hanja, with performance differences within $\pm{}0.0068$ F1-score for sequence labeling tasks and up to $+0.84$ BLEU score for translation. These limitations persist consistently across various model sizes, architectures, and domain-specific datasets. Our analysis reveals that the benefits of Classical Chinese resources diminish rapidly as local language data increases for Hanja, while showing substantial improvements only in extremely low-resource scenarios for both Korean and Japanese historical documents. These mixed results emphasize the need for careful empirical validation rather than assuming benefits from indiscriminate cross-lingual transfer.
Survey of Cultural Awareness in Language Models: Text and Beyond
Oct 30, 2024



Large-scale deployment of large language models (LLMs) in various applications, such as chatbots and virtual assistants, requires LLMs to be culturally sensitive to the user to ensure inclusivity. Culture has been widely studied in psychology and anthropology, and there has been a recent surge in research on making LLMs more culturally inclusive in LLMs that goes beyond multilinguality and builds on findings from psychology and anthropology. In this paper, we survey efforts towards incorporating cultural awareness into text-based and multimodal LLMs. We start by defining cultural awareness in LLMs, taking the definitions of culture from anthropology and psychology as a point of departure. We then examine methodologies adopted for creating cross-cultural datasets, strategies for cultural inclusion in downstream tasks, and methodologies that have been used for benchmarking cultural awareness in LLMs. Further, we discuss the ethical implications of cultural alignment, the role of Human-Computer Interaction in driving cultural inclusion in LLMs, and the role of cultural alignment in driving social science research. We finally provide pointers to future research based on our findings about gaps in the literature.
Perceptions to Beliefs: Exploring Precursory Inferences for Theory of Mind in Large Language Models
Jul 09, 2024While humans naturally develop theory of mind (ToM), the capability to understand other people's mental states and beliefs, state-of-the-art large language models (LLMs) underperform on simple ToM benchmarks. We posit that we can extend our understanding of LLMs' ToM abilities by evaluating key human ToM precursors -- perception inference and perception-to-belief inference -- in LLMs. We introduce two datasets, Percept-ToMi and Percept-FANToM, to evaluate these precursory inferences for ToM in LLMs by annotating characters' perceptions on ToMi and FANToM, respectively. Our evaluation of eight state-of-the-art LLMs reveals that the models generally perform well in perception inference while exhibiting limited capability in perception-to-belief inference (e.g., lack of inhibitory control). Based on these results, we present PercepToM, a novel ToM method leveraging LLMs' strong perception inference capability while supplementing their limited perception-to-belief inference. Experimental results demonstrate that PercepToM significantly enhances LLM's performance, especially in false belief scenarios.
BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages
Jun 14, 2024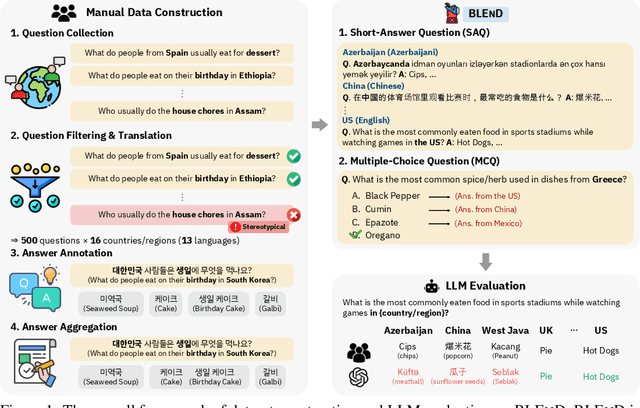
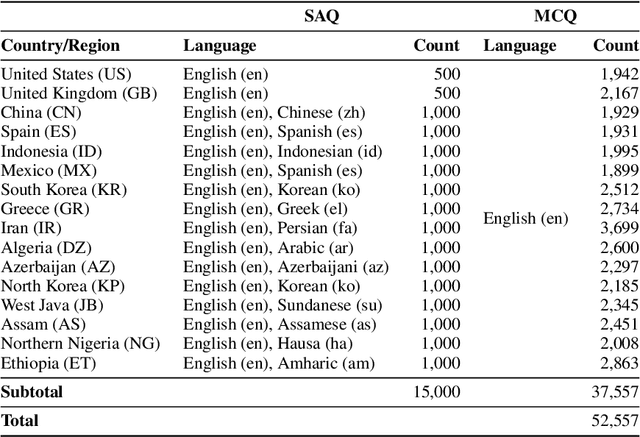
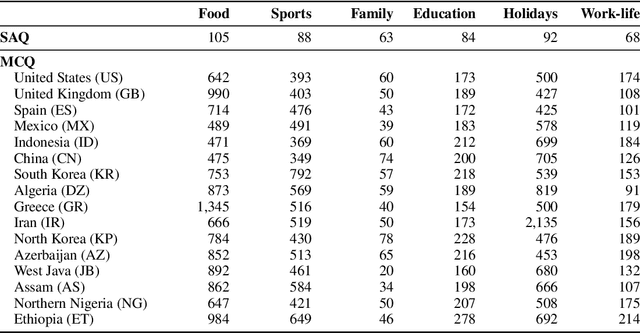
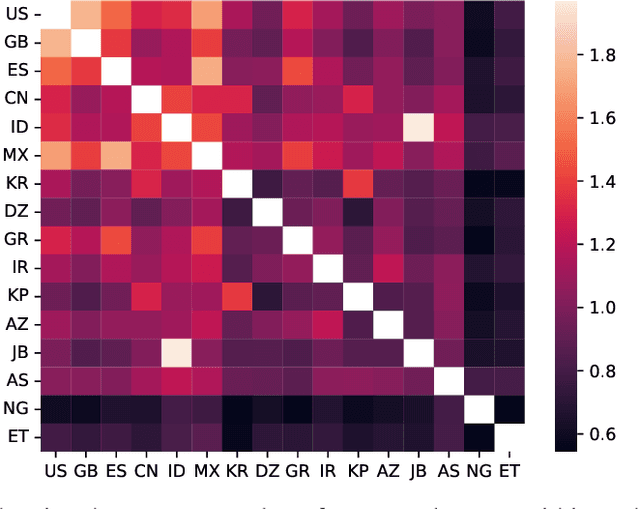
Large language models (LLMs) often lack culture-specific knowledge of daily life, especially across diverse regions and non-English languages. Existing benchmarks for evaluating LLMs' cultural sensitivities are limited to a single language or collected from online sources such as Wikipedia, which do not reflect the mundane everyday lifestyles of diverse regions. That is, information about the food people eat for their birthday celebrations, spices they typically use, musical instruments youngsters play, or the sports they practice in school is common cultural knowledge but uncommon in easily collected online sources, especially for underrepresented cultures. To address this issue, we introduce BLEnD, a hand-crafted benchmark designed to evaluate LLMs' everyday knowledge across diverse cultures and languages. BLEnD comprises 52.6k question-answer pairs from 16 countries/regions, in 13 different languages, including low-resource ones such as Amharic, Assamese, Azerbaijani, Hausa, and Sundanese. We construct the benchmark to include two formats of questions: short-answer and multiple-choice. We show that LLMs perform better for cultures that are highly represented online, with a maximum 57.34% difference in GPT-4, the best-performing model, in the short-answer format. For cultures represented by mid-to-high-resource languages, LLMs perform better in their local languages, but for cultures represented by low-resource languages, LLMs perform better in English than the local languages. We make our dataset publicly available at: https://github.com/nlee0212/BLEnD.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.