 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbientEye: A Dataset for Pupil Segmentation under Natural Ambient Infrared Illumination
Jun 02, 2026Eye tracking is essential for smart glasses, as it provides insight into user attention for ambient intelligence applications. However, most existing eye-tracking systems rely on active infrared (IR) illumination, creating practical barriers to all-day outdoor use due to power consumption. In this paper, we investigate whether passive IR cameras alone, without any active IR light source, can enable reliable pupil detection in unconstrained outdoor environments, where ambient sunlight serves as the sole illumination source. To support this investigation, we introduce AmbientEye, a large-scale dataset of 2,606,225 eye images collected from 35 participants from 19 countries. It is captured outdoors under natural sunlight with two off-axis camera configurations and two sun-orientation conditions. We provide high-quality pupil annotation through SAM2 automatic segmentation, followed by refinement by human annotators. We benchmark a state-of-the-art pupil segmentation algorithm on our dataset and compare its performance with that on existing datasets under controlled IR illumination. Results reveal a substantial drop in pupil segmentation performance from 0.928 on controlled IR datasets to 0.767 on AmbientEye. This performance gap highlights the challenge of the ambient-light setting. This positions AmbientEye as a first benchmark for an unexplored and highly practical eye-tracking scenario.
One-Topic-Doesn't-Fit-All: Transcreating Reading Comprehension Test for Personalized Learning
Nov 12, 2025


Personalized learning has gained attention in English as a Foreign Language (EFL) education, where engagement and motivation play crucial roles in reading comprehension. We propose a novel approach to generating personalized English reading comprehension tests tailored to students' interests. We develop a structured content transcreation pipeline using OpenAI's gpt-4o, where we start with the RACE-C dataset, and generate new passages and multiple-choice reading comprehension questions that are linguistically similar to the original passages but semantically aligned with individual learners' interests. Our methodology integrates topic extraction, question classification based on Bloom's taxonomy, linguistic feature analysis, and content transcreation to enhance student engagement. We conduct a controlled experiment with EFL learners in South Korea to examine the impact of interest-aligned reading materials on comprehension and motivation. Our results show students learning with personalized reading passages demonstrate improved comprehension and motivation retention compared to those learning with non-personalized materials.
Trans-EnV: A Framework for Evaluating the Linguistic Robustness of LLMs Against English Varieties
May 27, 2025Large Language Models (LLMs) are predominantly evaluated on Standard American English (SAE), often overlooking the diversity of global English varieties. This narrow focus may raise fairness concerns as degraded performance on non-standard varieties can lead to unequal benefits for users worldwide. Therefore, it is critical to extensively evaluate the linguistic robustness of LLMs on multiple non-standard English varieties. We introduce Trans-EnV, a framework that automatically transforms SAE datasets into multiple English varieties to evaluate the linguistic robustness. Our framework combines (1) linguistics expert knowledge to curate variety-specific features and transformation guidelines from linguistic literature and corpora, and (2) LLM-based transformations to ensure both linguistic validity and scalability. Using Trans-EnV, we transform six benchmark datasets into 38 English varieties and evaluate seven state-of-the-art LLMs. Our results reveal significant performance disparities, with accuracy decreasing by up to 46.3% on non-standard varieties. These findings highlight the importance of comprehensive linguistic robustness evaluation across diverse English varieties. Each construction of Trans-EnV was validated through rigorous statistical testing and consultation with a researcher in the field of second language acquisition, ensuring its linguistic validity. Our \href{https://github.com/jiyounglee-0523/TransEnV}{code} and \href{https://huggingface.co/collections/jiyounglee0523/transenv-681eadb3c0c8cf363b363fb1}{datasets} are publicly available.
Team ACK at SemEval-2025 Task 2: Beyond Word-for-Word Machine Translation for English-Korean Pairs
Apr 29, 2025Translating knowledge-intensive and entity-rich text between English and Korean requires transcreation to preserve language-specific and cultural nuances beyond literal, phonetic or word-for-word conversion. We evaluate 13 models (LLMs and MT models) using automatic metrics and human assessment by bilingual annotators. Our findings show LLMs outperform traditional MT systems but struggle with entity translation requiring cultural adaptation. By constructing an error taxonomy, we identify incorrect responses and entity name errors as key issues, with performance varying by entity type and popularity level. This work exposes gaps in automatic evaluation metrics and hope to enable future work in completing culturally-nuanced machine translation.
MSTS: A Multimodal Safety Test Suite for Vision-Language Models
Jan 17, 2025Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.
LLM-Driven Learning Analytics Dashboard for Teachers in EFL Writing Education
Oct 19, 2024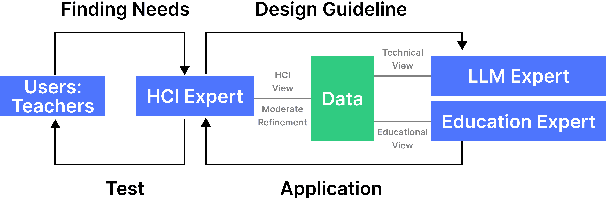
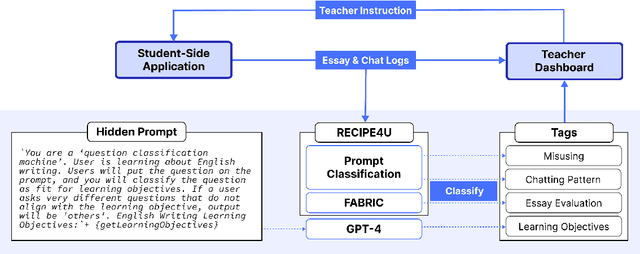
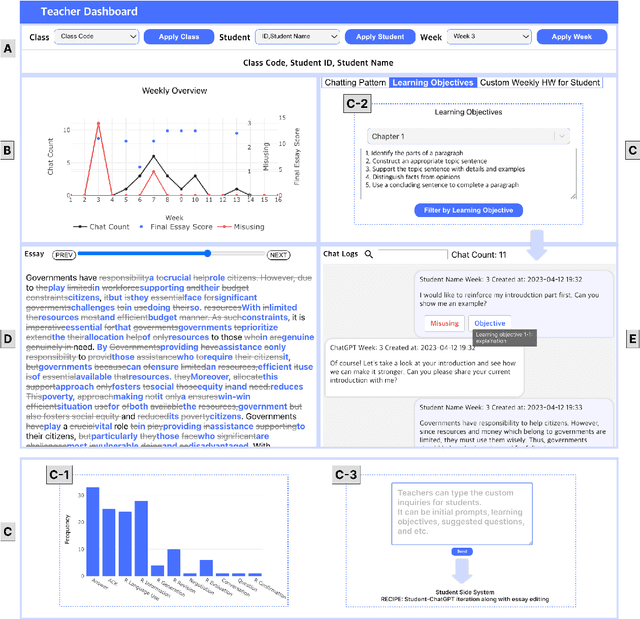
This paper presents the development of a dashboard designed specifically for teachers in English as a Foreign Language (EFL) writing education. Leveraging LLMs, the dashboard facilitates the analysis of student interactions with an essay writing system, which integrates ChatGPT for real-time feedback. The dashboard aids teachers in monitoring student behavior, identifying noneducational interaction with ChatGPT, and aligning instructional strategies with learning objectives. By combining insights from NLP and Human-Computer Interaction (HCI), this study demonstrates how a human-centered approach can enhance the effectiveness of teacher dashboards, particularly in ChatGPT-integrated learning.
RECIPE4U: Student-ChatGPT Interaction Dataset in EFL Writing Education
Mar 13, 2024
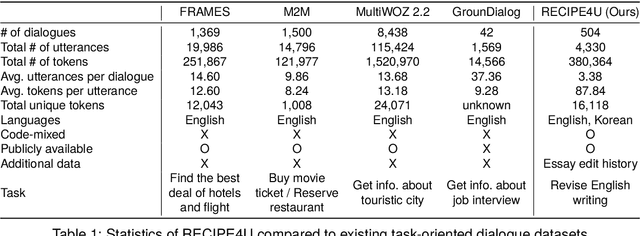
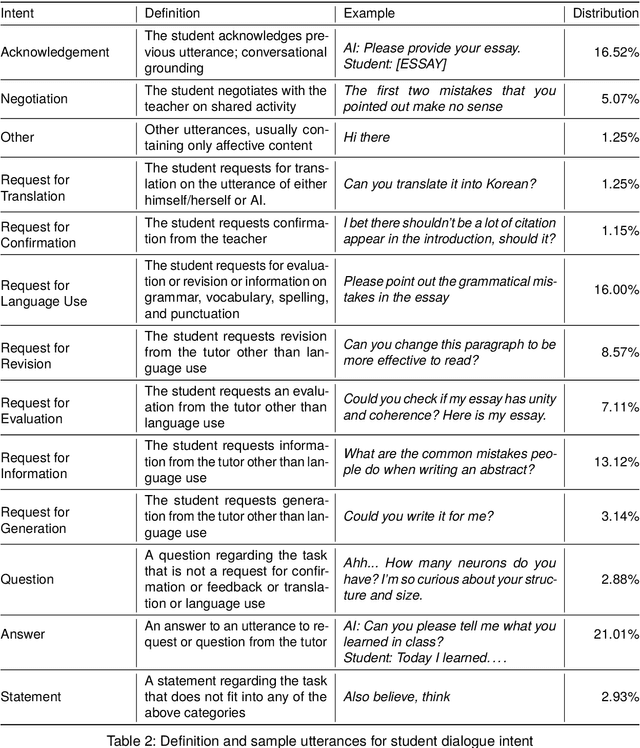
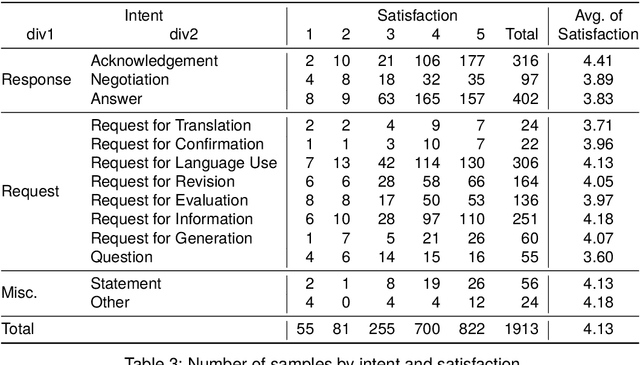
The integration of generative AI in education is expanding, yet empirical analyses of large-scale and real-world interactions between students and AI systems still remain limited. Addressing this gap, we present RECIPE4U (RECIPE for University), a dataset sourced from a semester-long experiment with 212 college students in English as Foreign Language (EFL) writing courses. During the study, students engaged in dialogues with ChatGPT to revise their essays. RECIPE4U includes comprehensive records of these interactions, including conversation logs, students' intent, students' self-rated satisfaction, and students' essay edit histories. In particular, we annotate the students' utterances in RECIPE4U with 13 intention labels based on our coding schemes. We establish baseline results for two subtasks in task-oriented dialogue systems within educational contexts: intent detection and satisfaction estimation. As a foundational step, we explore student-ChatGPT interaction patterns through RECIPE4U and analyze them by focusing on students' dialogue, essay data statistics, and students' essay edits. We further illustrate potential applications of RECIPE4U dataset for enhancing the incorporation of LLMs in educational frameworks. RECIPE4U is publicly available at https://zeunie.github.io/RECIPE4U/.
DREsS: Dataset for Rubric-based Essay Scoring on EFL Writing
Feb 21, 2024


Automated essay scoring (AES) is a useful tool in English as a Foreign Language (EFL) writing education, offering real-time essay scores for students and instructors. However, previous AES models were trained on essays and scores irrelevant to the practical scenarios of EFL writing education and usually provided a single holistic score due to the lack of appropriate datasets. In this paper, we release DREsS, a large-scale, standard dataset for rubric-based automated essay scoring. DREsS comprises three sub-datasets: DREsS_New, DREsS_Std., and DREsS_CASE. We collect DREsS_New, a real-classroom dataset with 1.7K essays authored by EFL undergraduate students and scored by English education experts. We also standardize existing rubric-based essay scoring datasets as DREsS_Std. We suggest CASE, a corruption-based augmentation strategy for essays, which generates 20K synthetic samples of DREsS_CASE and improves the baseline results by 45.44%. DREsS will enable further research to provide a more accurate and practical AES system for EFL writing education.
FABRIC: Automated Scoring and Feedback Generation for Essays
Oct 08, 2023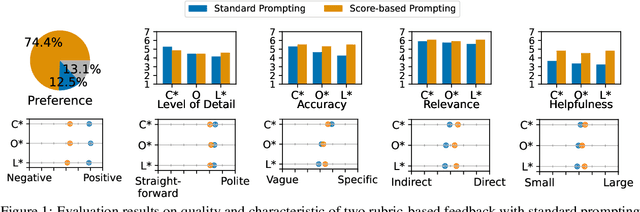
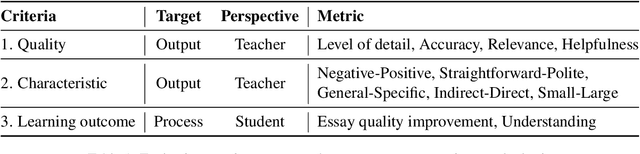
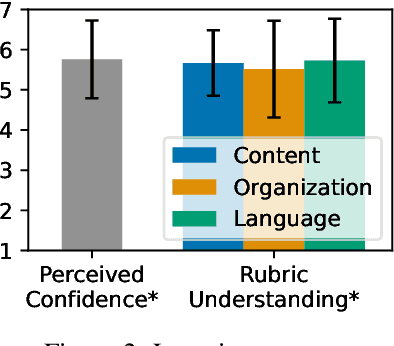
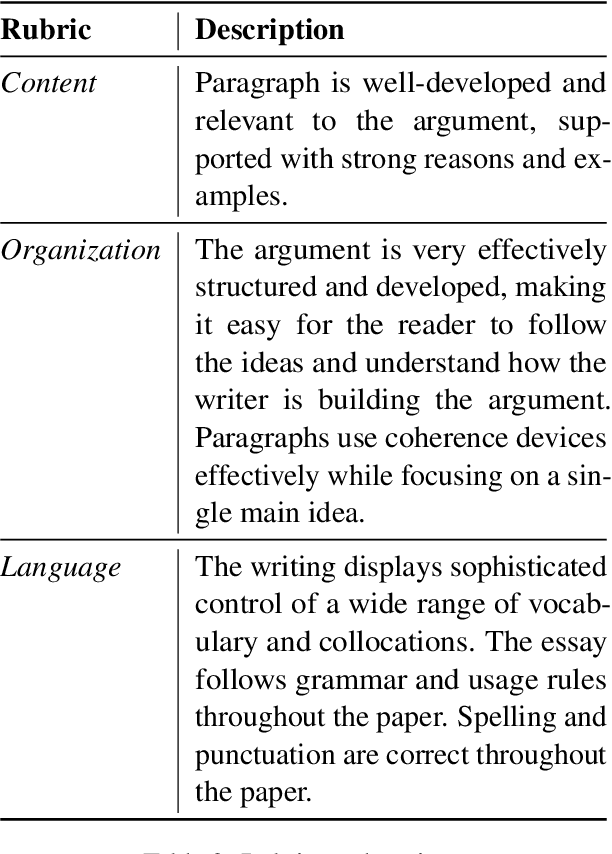
Automated essay scoring (AES) provides a useful tool for students and instructors in writing classes by generating essay scores in real-time. However, previous AES models do not provide more specific rubric-based scores nor feedback on how to improve the essays, which can be even more important than the overall scores for learning. We present FABRIC, a pipeline to help students and instructors in English writing classes by automatically generating 1) the overall scores, 2) specific rubric-based scores, and 3) detailed feedback on how to improve the essays. Under the guidance of English education experts, we chose the rubrics for the specific scores as content, organization, and language. The first component of the FABRIC pipeline is DREsS, a real-world Dataset for Rubric-based Essay Scoring (DREsS). The second component is CASE, a Corruption-based Augmentation Strategy for Essays, with which we can improve the accuracy of the baseline model by 45.44%. The third component is EssayCoT, the Essay Chain-of-Thought prompting strategy which uses scores predicted from the AES model to generate better feedback. We evaluate the effectiveness of the new dataset DREsS and the augmentation strategy CASE quantitatively and show significant improvements over the models trained with existing datasets. We evaluate the feedback generated by EssayCoT with English education experts to show significant improvements in the helpfulness of the feedback across all rubrics. Lastly, we evaluate the FABRIC pipeline with students in a college English writing class who rated the generated scores and feedback with an average of 6 on the Likert scale from 1 to 7.
ChEDDAR: Student-ChatGPT Dialogue in EFL Writing Education
Sep 23, 2023


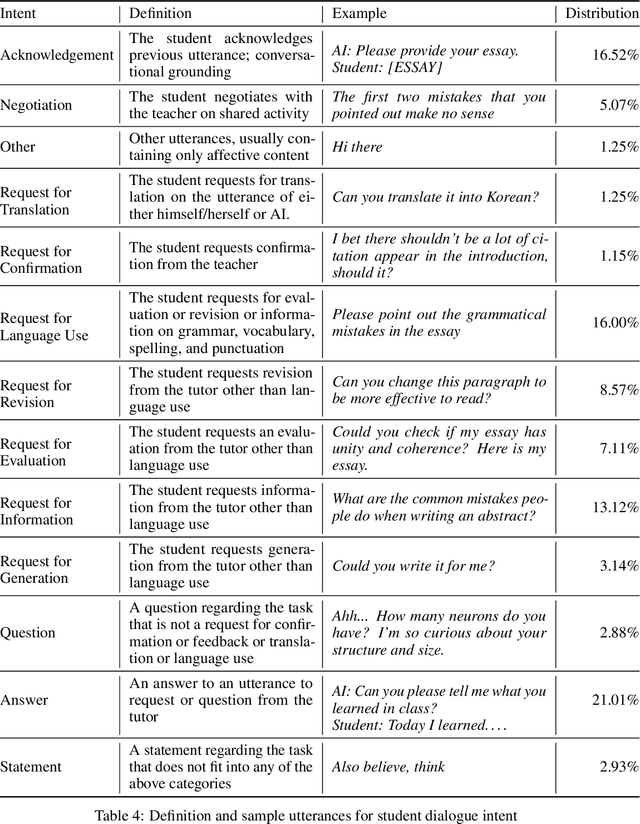
The integration of generative AI in education is expanding, yet empirical analyses of large-scale, real-world interactions between students and AI systems still remain limited. In this study, we present ChEDDAR, ChatGPT & EFL Learner's Dialogue Dataset As Revising an essay, which is collected from a semester-long longitudinal experiment involving 212 college students enrolled in English as Foreign Langauge (EFL) writing courses. The students were asked to revise their essays through dialogues with ChatGPT. ChEDDAR includes a conversation log, utterance-level essay edit history, self-rated satisfaction, and students' intent, in addition to session-level pre-and-post surveys documenting their objectives and overall experiences. We analyze students' usage patterns and perceptions regarding generative AI with respect to their intent and satisfaction. As a foundational step, we establish baseline results for two pivotal tasks in task-oriented dialogue systems within educational contexts: intent detection and satisfaction estimation. We finally suggest further research to refine the integration of generative AI into education settings, outlining potential scenarios utilizing ChEDDAR. ChEDDAR is publicly available at https://github.com/zeunie/ChEDDAR.