 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSTS: A Multimodal Safety Test Suite for Vision-Language Models
Jan 17, 2025Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.
AustroTox: A Dataset for Target-Based Austrian German Offensive Language Detection
Jun 12, 2024



Model interpretability in toxicity detection greatly profits from token-level annotations. However, currently such annotations are only available in English. We introduce a dataset annotated for offensive language detection sourced from a news forum, notable for its incorporation of the Austrian German dialect, comprising 4,562 user comments. In addition to binary offensiveness classification, we identify spans within each comment constituting vulgar language or representing targets of offensive statements. We evaluate fine-tuned language models as well as large language models in a zero- and few-shot fashion. The results indicate that while fine-tuned models excel in detecting linguistic peculiarities such as vulgar dialect, large language models demonstrate superior performance in detecting offensiveness in AustroTox. We publish the data and code.
Improving Adversarial Data Collection by Supporting Annotators: Lessons from GAHD, a German Hate Speech Dataset
Mar 28, 2024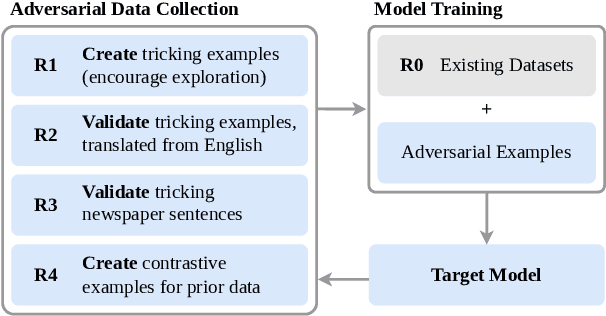



Hate speech detection models are only as good as the data they are trained on. Datasets sourced from social media suffer from systematic gaps and biases, leading to unreliable models with simplistic decision boundaries. Adversarial datasets, collected by exploiting model weaknesses, promise to fix this problem. However, adversarial data collection can be slow and costly, and individual annotators have limited creativity. In this paper, we introduce GAHD, a new German Adversarial Hate speech Dataset comprising ca.\ 11k examples. During data collection, we explore new strategies for supporting annotators, to create more diverse adversarial examples more efficiently and provide a manual analysis of annotator disagreements for each strategy. Our experiments show that the resulting dataset is challenging even for state-of-the-art hate speech detection models, and that training on GAHD clearly improves model robustness. Further, we find that mixing multiple support strategies is most advantageous. We make GAHD publicly available at https://github.com/jagol/gahd.
Evaluating the Effectiveness of Natural Language Inference for Hate Speech Detection in Languages with Limited Labeled Data
Jun 10, 2023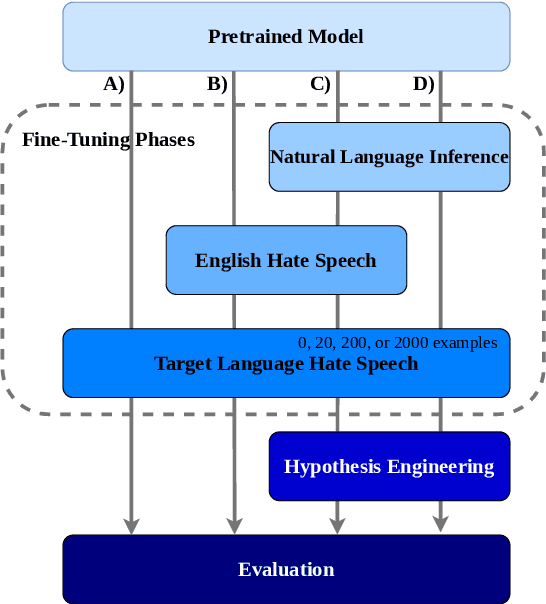
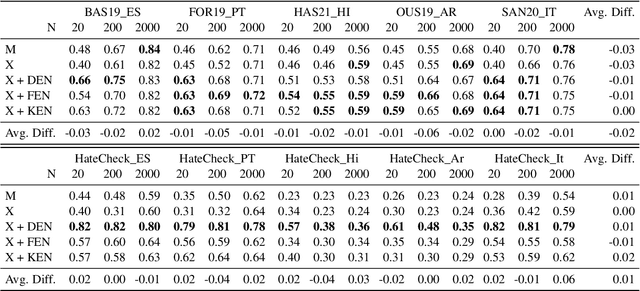
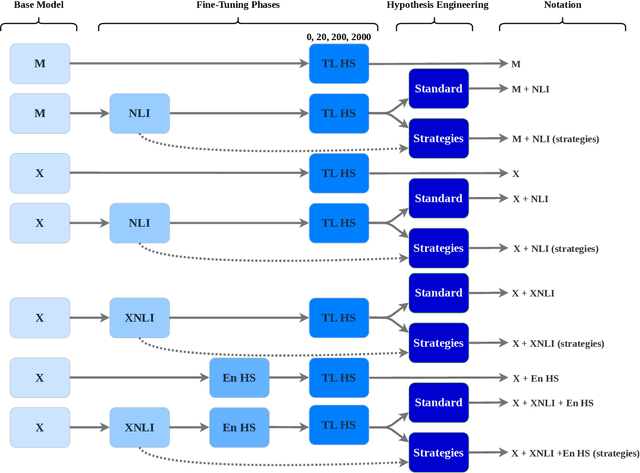

Most research on hate speech detection has focused on English where a sizeable amount of labeled training data is available. However, to expand hate speech detection into more languages, approaches that require minimal training data are needed. In this paper, we test whether natural language inference (NLI) models which perform well in zero- and few-shot settings can benefit hate speech detection performance in scenarios where only a limited amount of labeled data is available in the target language. Our evaluation on five languages demonstrates large performance improvements of NLI fine-tuning over direct fine-tuning in the target language. However, the effectiveness of previous work that proposed intermediate fine-tuning on English data is hard to match. Only in settings where the English training data does not match the test domain, can our customised NLI-formulation outperform intermediate fine-tuning on English. Based on our extensive experiments, we propose a set of recommendations for hate speech detection in languages where minimal labeled training data is available.
CL-UZH at SemEval-2023 Task 10: Sexism Detection through Incremental Fine-Tuning and Multi-Task Learning with Label Descriptions
Jun 06, 2023
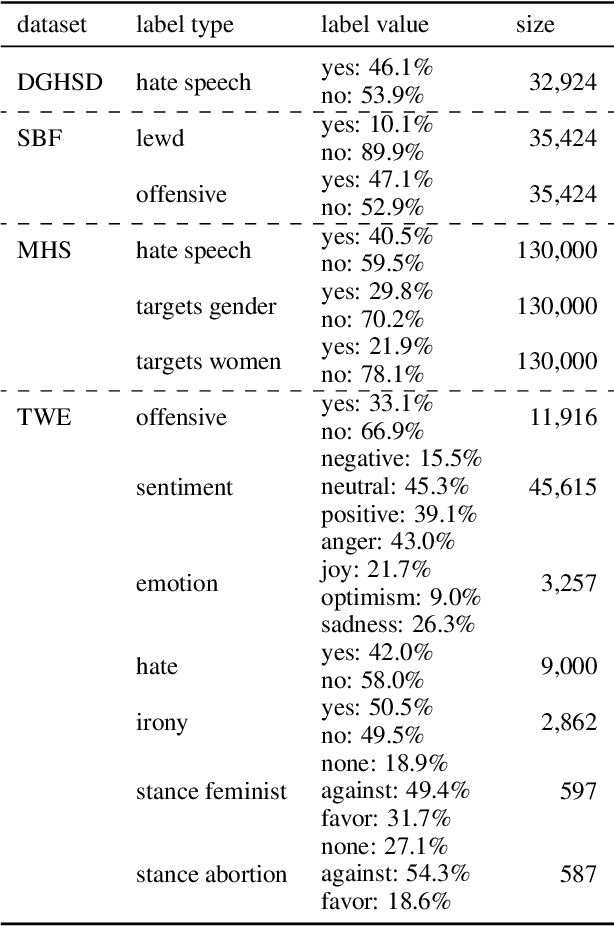


The widespread popularity of social media has led to an increase in hateful, abusive, and sexist language, motivating methods for the automatic detection of such phenomena. The goal of the SemEval shared task \textit{Towards Explainable Detection of Online Sexism} (EDOS 2023) is to detect sexism in English social media posts (subtask A), and to categorize such posts into four coarse-grained sexism categories (subtask B), and eleven fine-grained subcategories (subtask C). In this paper, we present our submitted systems for all three subtasks, based on a multi-task model that has been fine-tuned on a range of related tasks and datasets before being fine-tuned on the specific EDOS subtasks. We implement multi-task learning by formulating each task as binary pairwise text classification, where the dataset and label descriptions are given along with the input text. The results show clear improvements over a fine-tuned DeBERTa-V3 serving as a baseline leading to $F_1$-scores of 85.9\% in subtask A (rank 13/84), 64.8\% in subtask B (rank 19/69), and 44.9\% in subtask C (26/63).
Hypothesis Engineering for Zero-Shot Hate Speech Detection
Oct 03, 2022
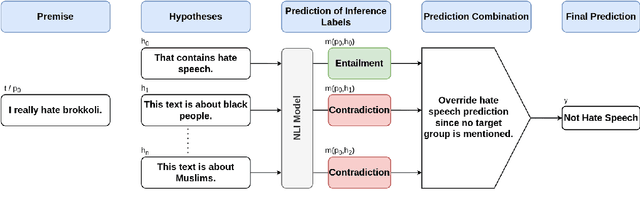


Standard approaches to hate speech detection rely on sufficient available hate speech annotations. Extending previous work that repurposes natural language inference (NLI) models for zero-shot text classification, we propose a simple approach that combines multiple hypotheses to improve English NLI-based zero-shot hate speech detection. We first conduct an error analysis for vanilla NLI-based zero-shot hate speech detection and then develop four strategies based on this analysis. The strategies use multiple hypotheses to predict various aspects of an input text and combine these predictions into a final verdict. We find that the zero-shot baseline used for the initial error analysis already outperforms commercial systems and fine-tuned BERT-based hate speech detection models on HateCheck. The combination of the proposed strategies further increases the zero-shot accuracy of 79.4% on HateCheck by 7.9 percentage points (pp), and the accuracy of 69.6% on ETHOS by 10.0pp.