 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic Features Extracted by GPT-4 Improve Alzheimer's Disease Detection based on Spontaneous Speech
Dec 20, 2024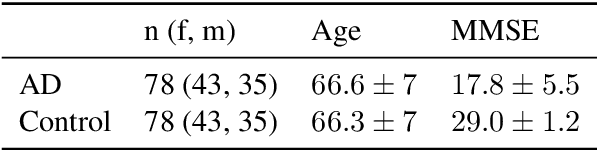

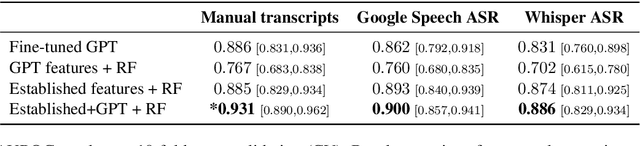
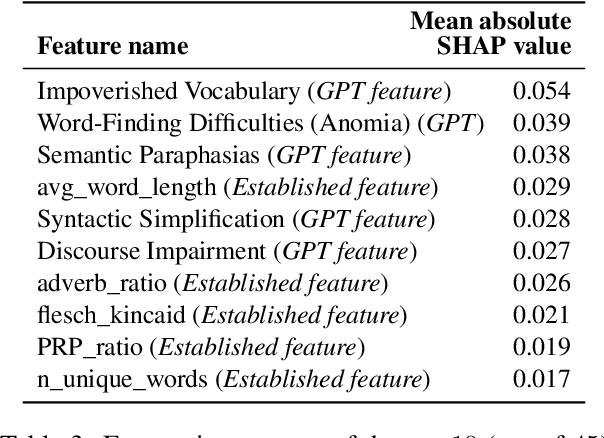
Alzheimer's Disease (AD) is a significant and growing public health concern. Investigating alterations in speech and language patterns offers a promising path towards cost-effective and non-invasive early detection of AD on a large scale. Large language models (LLMs), such as GPT, have enabled powerful new possibilities for semantic text analysis. In this study, we leverage GPT-4 to extract five semantic features from transcripts of spontaneous patient speech. The features capture known symptoms of AD, but they are difficult to quantify effectively using traditional methods of computational linguistics. We demonstrate the clinical significance of these features and further validate one of them ("Word-Finding Difficulties") against a proxy measure and human raters. When combined with established linguistic features and a Random Forest classifier, the GPT-derived features significantly improve the detection of AD. Our approach proves effective for both manually transcribed and automatically generated transcripts, representing a novel and impactful use of recent advancements in LLMs for AD speech analysis.
Improving Adversarial Data Collection by Supporting Annotators: Lessons from GAHD, a German Hate Speech Dataset
Mar 28, 2024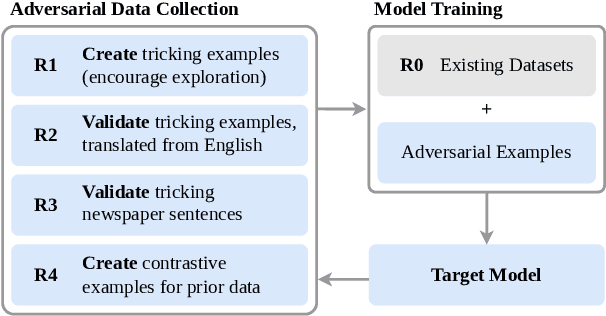



Hate speech detection models are only as good as the data they are trained on. Datasets sourced from social media suffer from systematic gaps and biases, leading to unreliable models with simplistic decision boundaries. Adversarial datasets, collected by exploiting model weaknesses, promise to fix this problem. However, adversarial data collection can be slow and costly, and individual annotators have limited creativity. In this paper, we introduce GAHD, a new German Adversarial Hate speech Dataset comprising ca.\ 11k examples. During data collection, we explore new strategies for supporting annotators, to create more diverse adversarial examples more efficiently and provide a manual analysis of annotator disagreements for each strategy. Our experiments show that the resulting dataset is challenging even for state-of-the-art hate speech detection models, and that training on GAHD clearly improves model robustness. Further, we find that mixing multiple support strategies is most advantageous. We make GAHD publicly available at https://github.com/jagol/gahd.
Can Chat GPT solve a Linguistics Exam?
Nov 04, 2023The present study asks if ChatGPT4, the version of ChatGPT which uses the language model GPT4, can successfully solve introductory linguistic exams. Previous exam questions of an Introduction to Linguistics course at a German university are used to test this. The exam questions were fed into ChatGPT4 with only minimal preprocessing. The results show that the language model is very successful in the interpretation even of complex and nested tasks. It proved surprisingly successful in the task of broad phonetic transcription, but performed less well in the analysis of morphemes and phrases. In simple cases it performs sufficiently well, but rarer cases, particularly with missing one-to-one correspondence, are currently treated with mixed results. The model is not yet able to deal with visualisations, such as the analysis or generation of syntax trees. More extensive preprocessing, which translates these tasks into text data, allow the model to also solve these tasks successfully.
Turkish Native Language Identification
Aug 04, 2023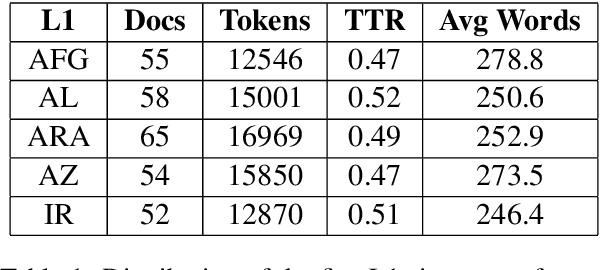
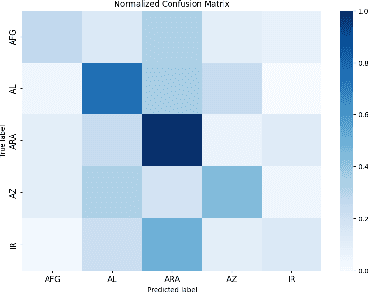
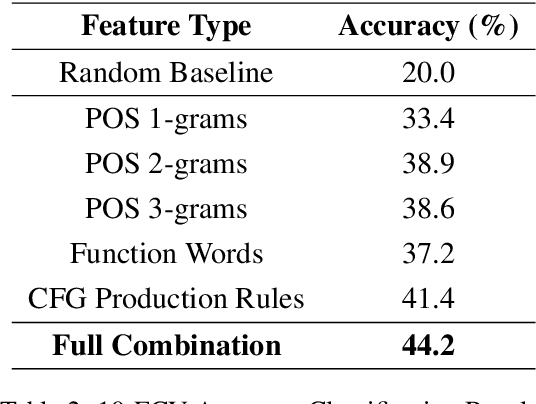
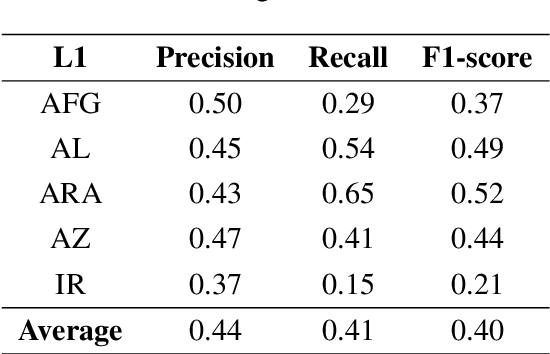
In this paper, we present the first application of Native Language Identification (NLI) for the Turkish language. NLI involves predicting the writer's first language by analysing their writing in different languages. While most NLI research has focused on English, our study extends its scope to Turkish. We used the recently constructed Turkish Learner Corpus and employed a combination of three syntactic features (CFG production rules, part-of-speech n-grams, and function words) with L2 texts to demonstrate their effectiveness in this task.
Exploring Hybrid Linguistic Features for Turkish Text Readability
Jun 25, 2023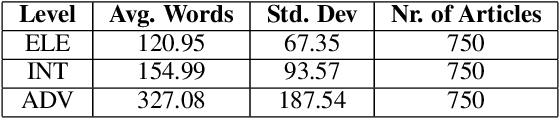
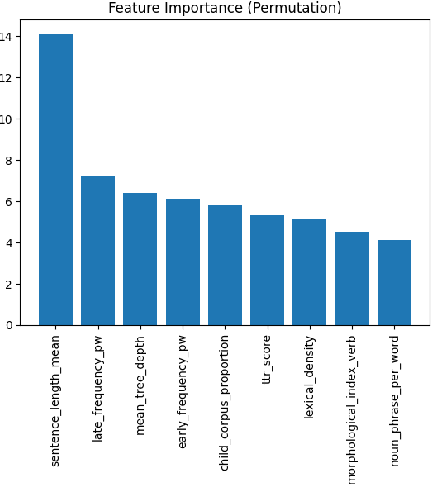
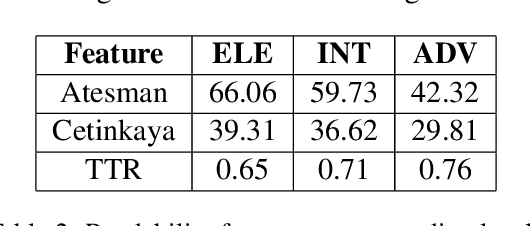
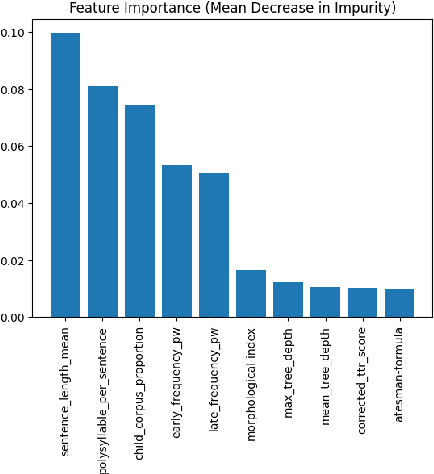
This paper presents the first comprehensive study on automatic readability assessment of Turkish texts. We combine state-of-the-art neural network models with linguistic features at lexical, morphosyntactic, syntactic and discourse levels to develop an advanced readability tool. We evaluate the effectiveness of traditional readability formulas compared to modern automated methods and identify key linguistic features that determine the readability of Turkish texts.
Evaluating the Effectiveness of Natural Language Inference for Hate Speech Detection in Languages with Limited Labeled Data
Jun 10, 2023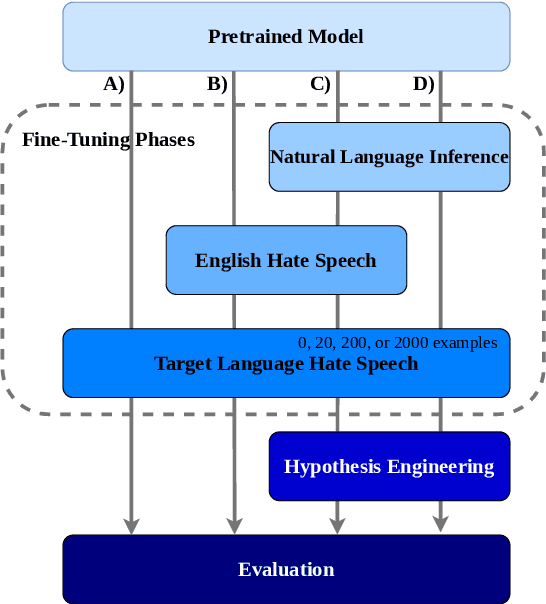
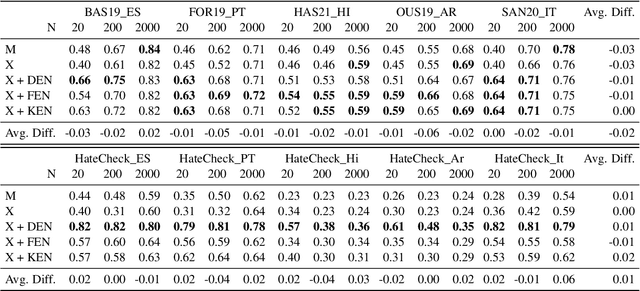
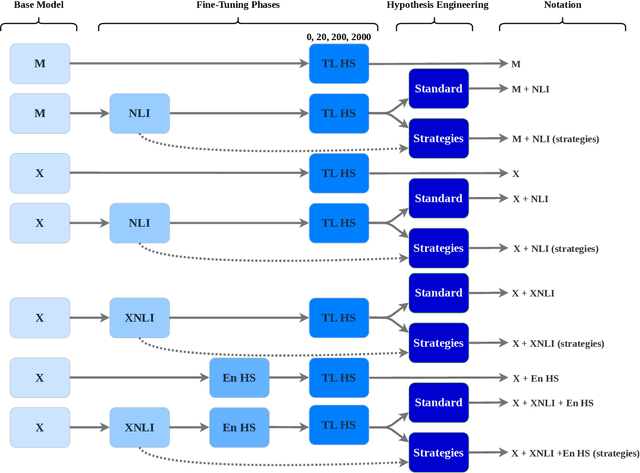

Most research on hate speech detection has focused on English where a sizeable amount of labeled training data is available. However, to expand hate speech detection into more languages, approaches that require minimal training data are needed. In this paper, we test whether natural language inference (NLI) models which perform well in zero- and few-shot settings can benefit hate speech detection performance in scenarios where only a limited amount of labeled data is available in the target language. Our evaluation on five languages demonstrates large performance improvements of NLI fine-tuning over direct fine-tuning in the target language. However, the effectiveness of previous work that proposed intermediate fine-tuning on English data is hard to match. Only in settings where the English training data does not match the test domain, can our customised NLI-formulation outperform intermediate fine-tuning on English. Based on our extensive experiments, we propose a set of recommendations for hate speech detection in languages where minimal labeled training data is available.
Scaling Native Language Identification with Transformer Adapters
Nov 18, 2022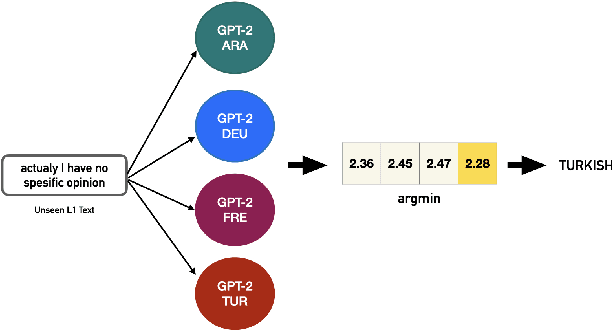
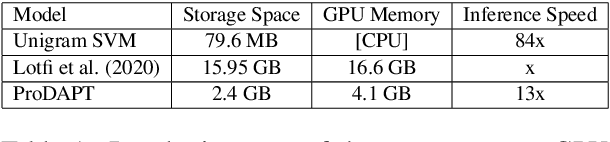
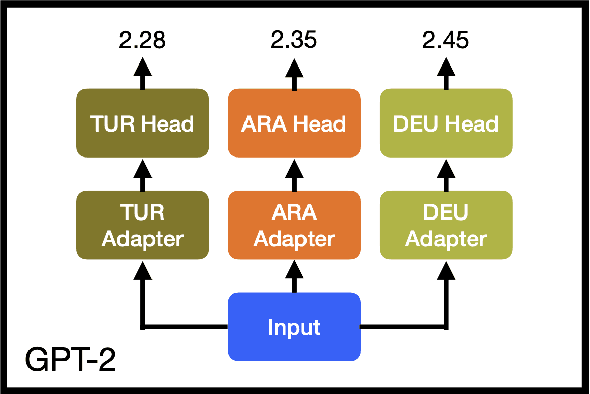
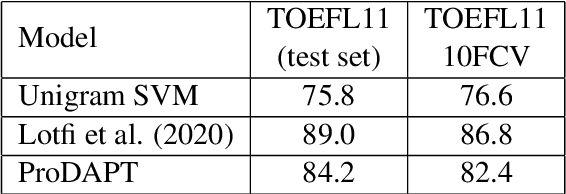
Native language identification (NLI) is the task of automatically identifying the native language (L1) of an individual based on their language production in a learned language. It is useful for a variety of purposes including marketing, security and educational applications. NLI is usually framed as a multi-label classification task, where numerous designed features are combined to achieve state-of-the-art results. Recently deep generative approach based on transformer decoders (GPT-2) outperformed its counterparts and achieved the best results on the NLI benchmark datasets. We investigate this approach to determine the practical implications compared to traditional state-of-the-art NLI systems. We introduce transformer adapters to address memory limitations and improve training/inference speed to scale NLI applications for production.
Hypothesis Engineering for Zero-Shot Hate Speech Detection
Oct 03, 2022
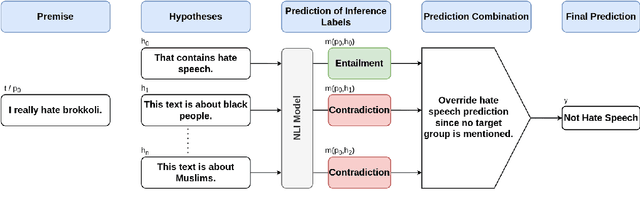


Standard approaches to hate speech detection rely on sufficient available hate speech annotations. Extending previous work that repurposes natural language inference (NLI) models for zero-shot text classification, we propose a simple approach that combines multiple hypotheses to improve English NLI-based zero-shot hate speech detection. We first conduct an error analysis for vanilla NLI-based zero-shot hate speech detection and then develop four strategies based on this analysis. The strategies use multiple hypotheses to predict various aspects of an input text and combine these predictions into a final verdict. We find that the zero-shot baseline used for the initial error analysis already outperforms commercial systems and fine-tuned BERT-based hate speech detection models on HateCheck. The combination of the proposed strategies further increases the zero-shot accuracy of 79.4% on HateCheck by 7.9 percentage points (pp), and the accuracy of 69.6% on ETHOS by 10.0pp.
Comparing a statistical and a rule-based tagger for German
Nov 11, 1998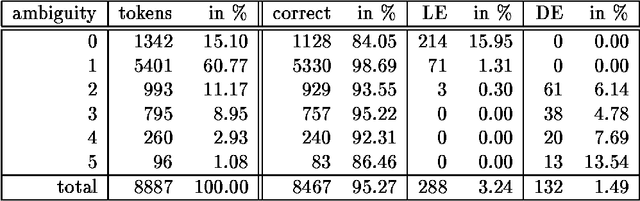
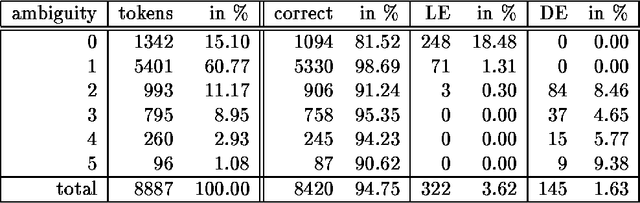

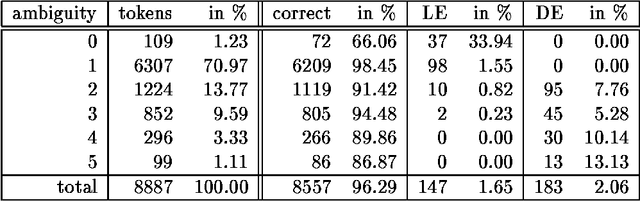
In this paper we present the results of comparing a statistical tagger for German based on decision trees and a rule-based Brill-Tagger for German. We used the same training corpus (and therefore the same tag-set) to train both taggers. We then applied the taggers to the same test corpus and compared their respective behavior and in particular their error rates. Both taggers perform similarly with an error rate of around 5%. From the detailed error analysis it can be seen that the rule-based tagger has more problems with unknown words than the statistical tagger. But the results are opposite for tokens that are many-ways ambiguous. If the unknown words are fed into the taggers with the help of an external lexicon (such as the Gertwol system) the error rate of the rule-based tagger drops to 4.7%, and the respective rate of the statistical taggers drops to around 3.7%. Combining the taggers by using the output of one tagger to help the other did not lead to any further improvement.