 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based HTR for Historical Documents
Mar 21, 2022
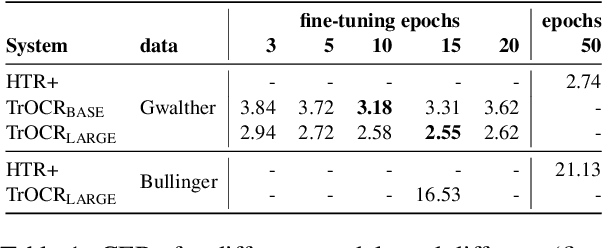
We apply the TrOCR framework to real-world, historical manuscripts and show that TrOCR per se is a strong model, ideal for transfer learning. TrOCR has been trained on English only, but it can adapt to other languages that use the Latin alphabet fairly easily and with little training material. We compare TrOCR against a SOTA HTR framework (Transkribus) and show that it can beat such systems. This finding is essential since Transkribus performs best when it has access to baseline information, which is not needed at all to fine-tune TrOCR.
Evaluation of HTR models without Ground Truth Material
Jan 17, 2022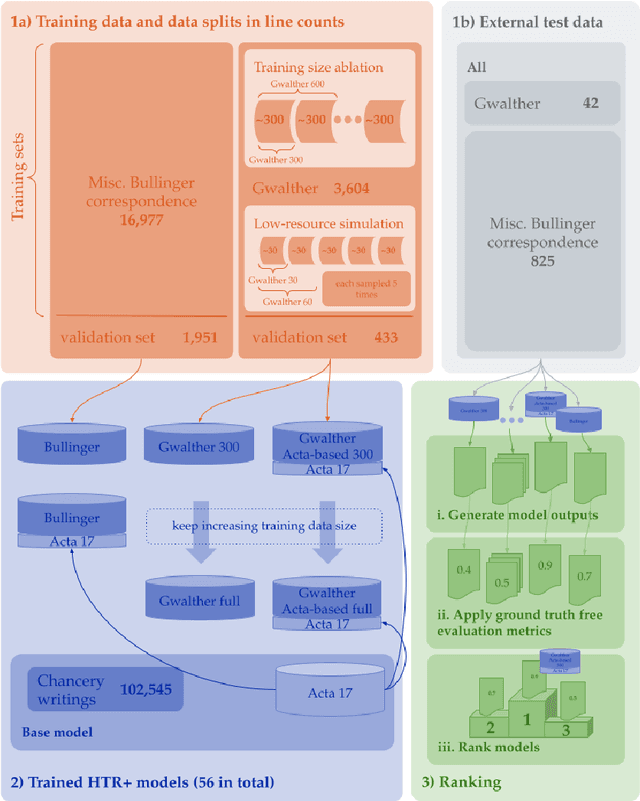
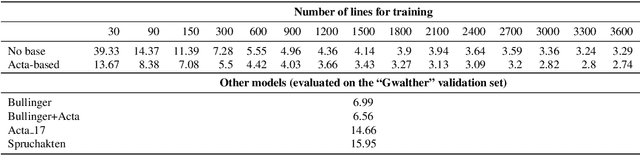
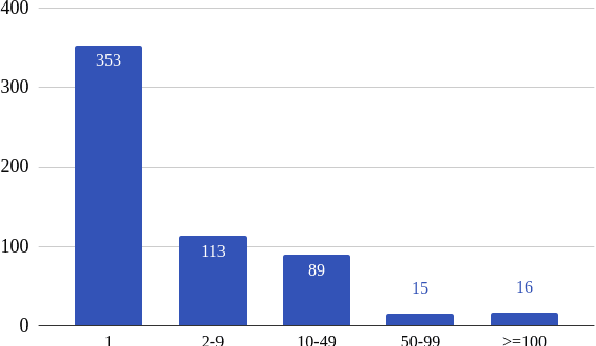
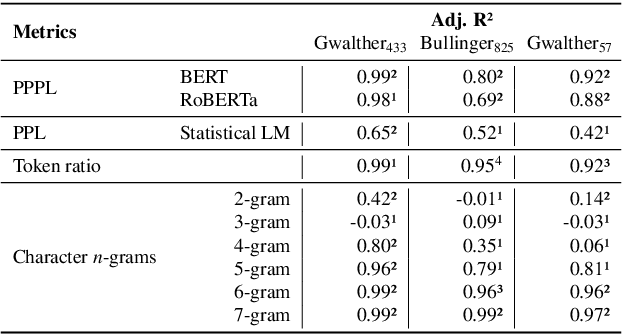
The evaluation of Handwritten Text Recognition (HTR) models during their development is straightforward: because HTR is a supervised problem, the usual data split into training, validation, and test data sets allows the evaluation of models in terms of accuracy or error rates. However, the evaluation process becomes tricky as soon as we switch from development to application. A compilation of a new (and forcibly smaller) ground truth (GT) from a sample of the data that we want to apply the model on and the subsequent evaluation of models thereon only provides hints about the quality of the recognised text, as do confidence scores (if available) the models return. Moreover, if we have several models at hand, we face a model selection problem since we want to obtain the best possible result during the application phase. This calls for GT-free metrics to select the best model, which is why we (re-)introduce and compare different metrics, from simple, lexicon-based to more elaborate ones using standard language models and masked language models (MLM). We show that MLM-based evaluation can compete with lexicon-based methods, with the advantage that large and multilingual transformers are readily available, thus making compiling lexical resources for other metrics superfluous.
Post-editing Productivity with Neural Machine Translation: An Empirical Assessment of Speed and Quality in the Banking and Finance Domain
Jun 04, 2019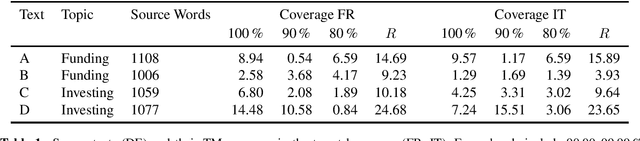
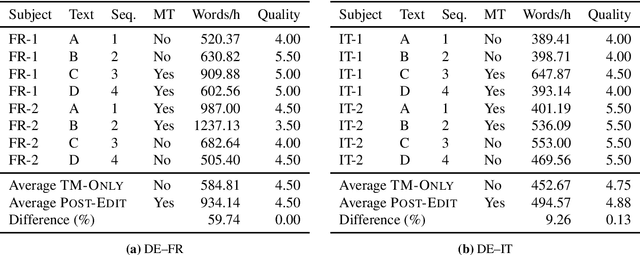
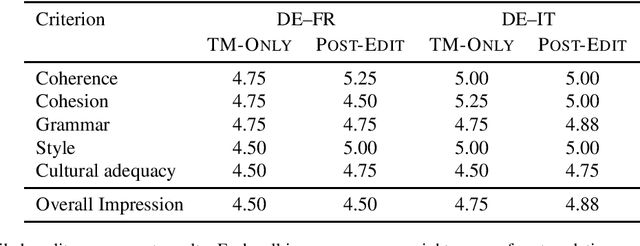
Neural machine translation (NMT) has set new quality standards in automatic translation, yet its effect on post-editing productivity is still pending thorough investigation. We empirically test how the inclusion of NMT, in addition to domain-specific translation memories and termbases, impacts speed and quality in professional translation of financial texts. We find that even with language pairs that have received little attention in research settings and small amounts of in-domain data for system adaptation, NMT post-editing allows for substantial time savings and leads to equal or slightly better quality.
Has Machine Translation Achieved Human Parity? A Case for Document-level Evaluation
Aug 21, 2018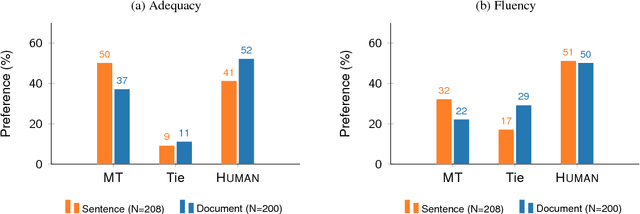
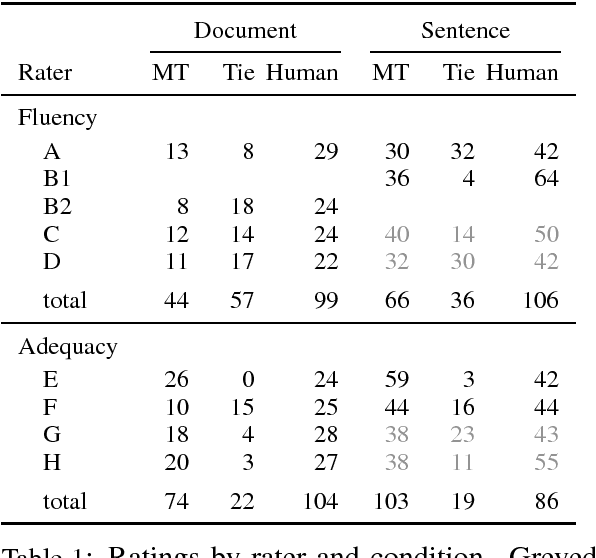
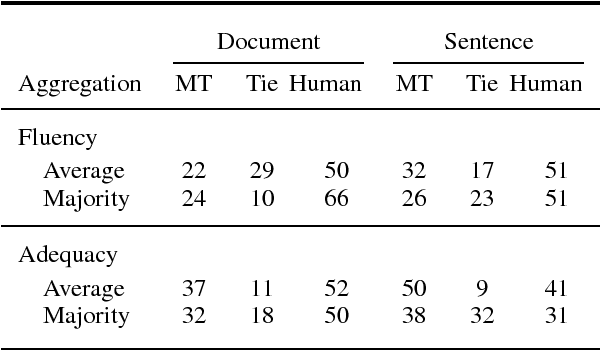
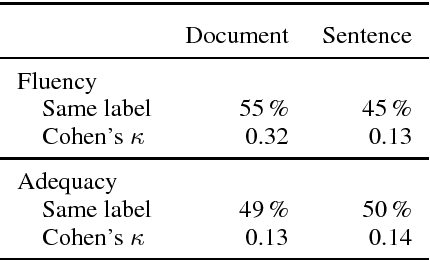
Recent research suggests that neural machine translation achieves parity with professional human translation on the WMT Chinese--English news translation task. We empirically test this claim with alternative evaluation protocols, contrasting the evaluation of single sentences and entire documents. In a pairwise ranking experiment, human raters assessing adequacy and fluency show a stronger preference for human over machine translation when evaluating documents as compared to isolated sentences. Our findings emphasise the need to shift towards document-level evaluation as machine translation improves to the degree that errors which are hard or impossible to spot at the sentence-level become decisive in discriminating quality of different translation outputs.
Evaluating the fully automatic multi-language translation of the Swiss avalanche bulletin
May 23, 2014
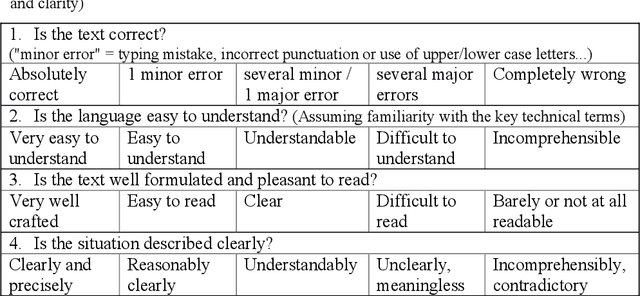
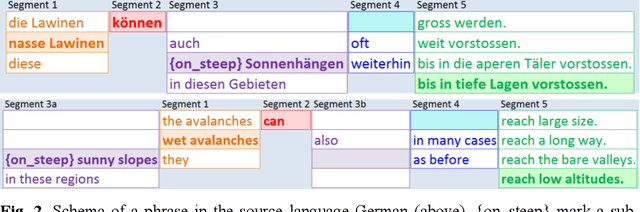

The Swiss avalanche bulletin is produced twice a day in four languages. Due to the lack of time available for manual translation, a fully automated translation system is employed, based on a catalogue of predefined phrases and predetermined rules of how these phrases can be combined to produce sentences. The system is able to automatically translate such sentences from German into the target languages French, Italian and English without subsequent proofreading or correction. Our catalogue of phrases is limited to a small sublanguage. The reduction of daily translation costs is expected to offset the initial development costs within a few years. After being operational for two winter seasons, we assess here the quality of the produced texts based on an evaluation where participants rate real danger descriptions from both origins, the catalogue of phrases versus the manually written and translated texts. With a mean recognition rate of 55%, users can hardly distinguish between the two types of texts, and give similar ratings with respect to their language quality. Overall, the output from the catalogue system can be considered virtually equivalent to a text written by avalanche forecasters and then manually translated by professional translators. Furthermore, forecasters declared that all relevant situations were captured by the system with sufficient accuracy and within the limited time available.
Comparing a statistical and a rule-based tagger for German
Nov 11, 1998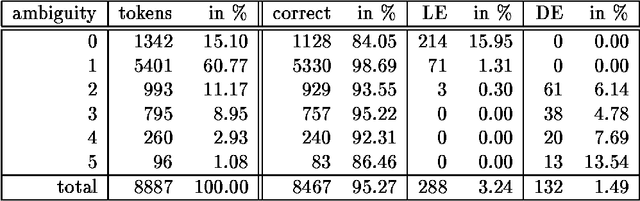
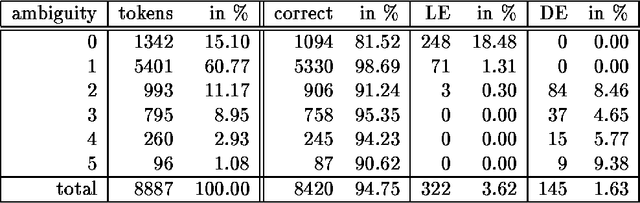

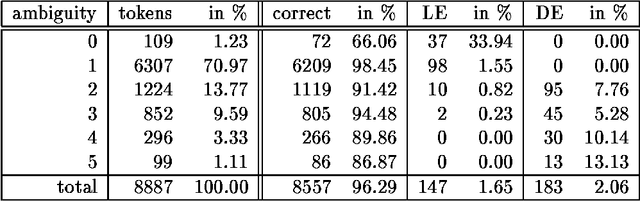
In this paper we present the results of comparing a statistical tagger for German based on decision trees and a rule-based Brill-Tagger for German. We used the same training corpus (and therefore the same tag-set) to train both taggers. We then applied the taggers to the same test corpus and compared their respective behavior and in particular their error rates. Both taggers perform similarly with an error rate of around 5%. From the detailed error analysis it can be seen that the rule-based tagger has more problems with unknown words than the statistical tagger. But the results are opposite for tokens that are many-ways ambiguous. If the unknown words are fed into the taggers with the help of an external lexicon (such as the Gertwol system) the error rate of the rule-based tagger drops to 4.7%, and the respective rate of the statistical taggers drops to around 3.7%. Combining the taggers by using the output of one tagger to help the other did not lead to any further improvement.
Experiences with the GTU grammar development environment
Jul 21, 1997In this paper we describe our experiences with a tool for the development and testing of natural language grammars called GTU (German: Grammatik-Testumgebumg; grammar test environment). GTU supports four grammar formalisms under a window-oriented user interface. Additionally, it contains a set of German test sentences covering various syntactic phenomena as well as three types of German lexicons that can be attached to a grammar via an integrated lexicon interface. What follows is a description of the experiences we gained when we used GTU as a tutoring tool for students and as an experimental tool for CL researchers. From these we will derive the features necessary for a future grammar workbench.
* 7 pages, uses aclap.sty