Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based HTR for Historical Documents
Paper and Code
Mar 21, 2022
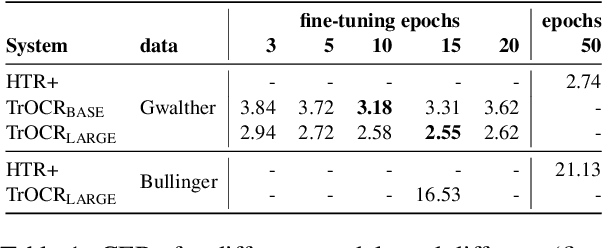
We apply the TrOCR framework to real-world, historical manuscripts and show that TrOCR per se is a strong model, ideal for transfer learning. TrOCR has been trained on English only, but it can adapt to other languages that use the Latin alphabet fairly easily and with little training material. We compare TrOCR against a SOTA HTR framework (Transkribus) and show that it can beat such systems. This finding is essential since Transkribus performs best when it has access to baseline information, which is not needed at all to fine-tune TrOCR.
* This is an abstract submitted and accepted at ComHum 2022 in
Lausanne. We will be elaborating on these initial findings in the paper that
we will submit after the conference
View paper on