 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based HTR for Historical Documents
Mar 21, 2022
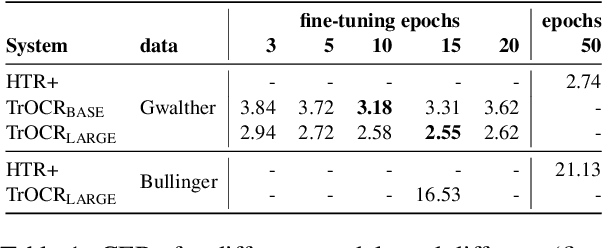
We apply the TrOCR framework to real-world, historical manuscripts and show that TrOCR per se is a strong model, ideal for transfer learning. TrOCR has been trained on English only, but it can adapt to other languages that use the Latin alphabet fairly easily and with little training material. We compare TrOCR against a SOTA HTR framework (Transkribus) and show that it can beat such systems. This finding is essential since Transkribus performs best when it has access to baseline information, which is not needed at all to fine-tune TrOCR.
Evaluation of HTR models without Ground Truth Material
Jan 17, 2022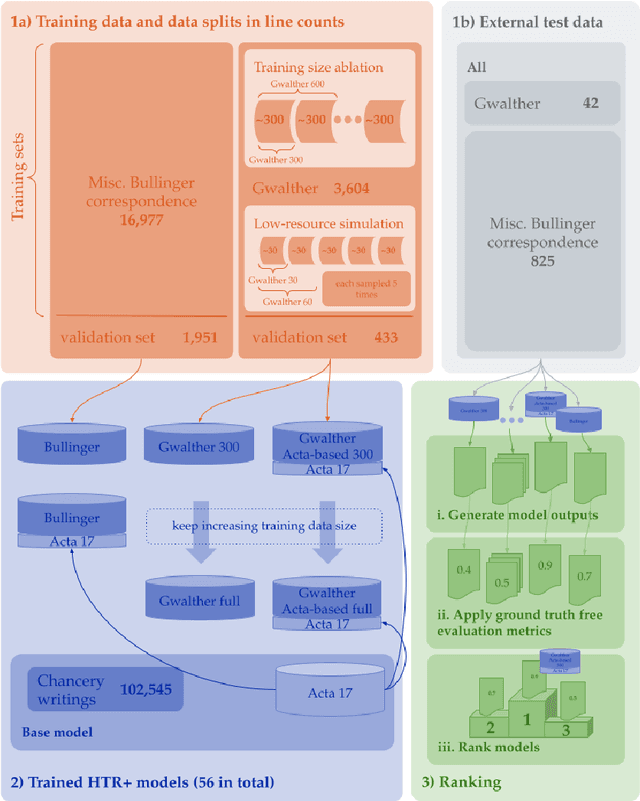
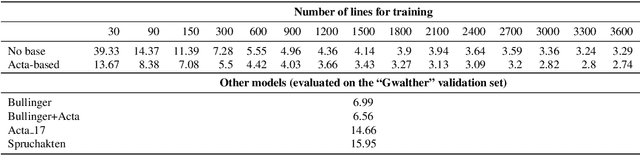
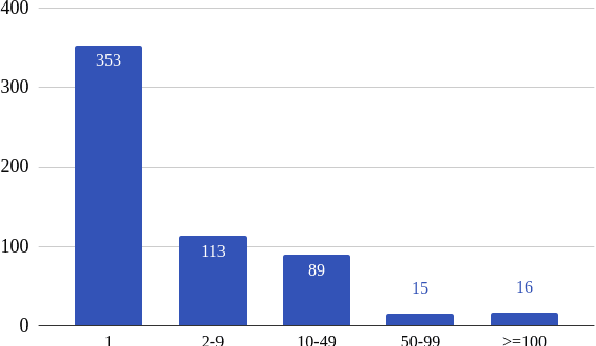
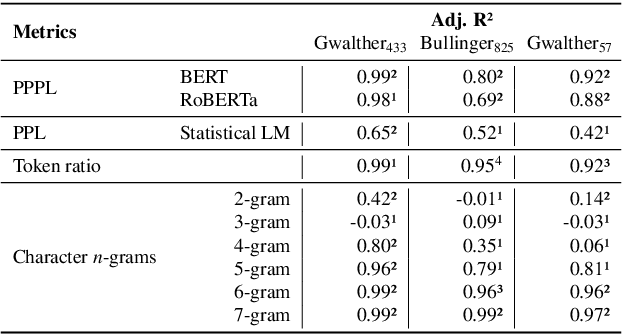
The evaluation of Handwritten Text Recognition (HTR) models during their development is straightforward: because HTR is a supervised problem, the usual data split into training, validation, and test data sets allows the evaluation of models in terms of accuracy or error rates. However, the evaluation process becomes tricky as soon as we switch from development to application. A compilation of a new (and forcibly smaller) ground truth (GT) from a sample of the data that we want to apply the model on and the subsequent evaluation of models thereon only provides hints about the quality of the recognised text, as do confidence scores (if available) the models return. Moreover, if we have several models at hand, we face a model selection problem since we want to obtain the best possible result during the application phase. This calls for GT-free metrics to select the best model, which is why we (re-)introduce and compare different metrics, from simple, lexicon-based to more elaborate ones using standard language models and masked language models (MLM). We show that MLM-based evaluation can compete with lexicon-based methods, with the advantage that large and multilingual transformers are readily available, thus making compiling lexical resources for other metrics superfluous.