 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText classification of column headers with a controlled vocabulary: leveraging LLMs for metadata enrichment
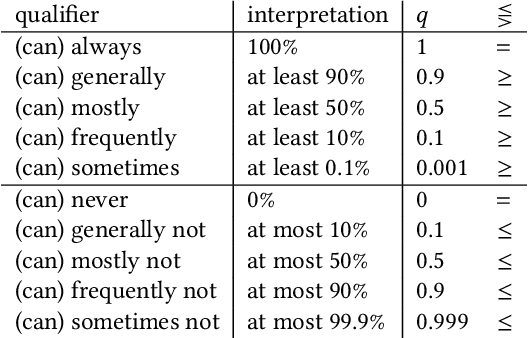
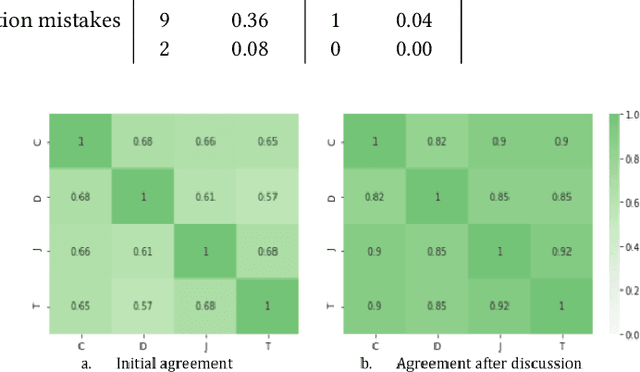
Mar 05, 2024Traditional dataset retrieval systems index on metadata information rather than on the data values. Thus relying primarily on manual annotations and high-quality metadata, processes known to be labour-intensive and challenging to automate. We propose a method to support metadata enrichment with topic annotations of column headers using three Large Language Models (LLMs): ChatGPT-3.5, GoogleBard and GoogleGemini. We investigate the LLMs ability to classify column headers based on domain-specific topics from a controlled vocabulary. We evaluate our approach by assessing the internal consistency of the LLMs, the inter-machine alignment, and the human-machine agreement for the topic classification task. Additionally, we investigate the impact of contextual information (i.e. dataset description) on the classification outcomes. Our results suggest that ChatGPT and GoogleGemini outperform GoogleBard for internal consistency as well as LLM-human-alignment. Interestingly, we found that context had no impact on the LLMs performances. This work proposes a novel approach that leverages LLMs for text classification using a controlled topic vocabulary, which has the potential to facilitate automated metadata enrichment, thereby enhancing dataset retrieval and the Findability, Accessibility, Interoperability and Reusability (FAIR) of research data on the Web.
Nanopublication-Based Semantic Publishing and Reviewing: A Field Study with Formalization Papers
Mar 03, 2022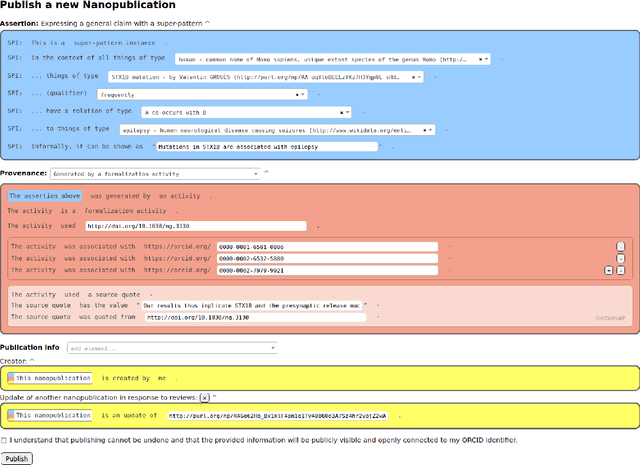
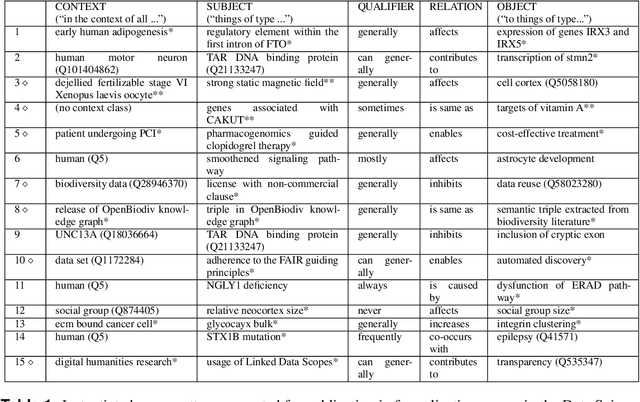
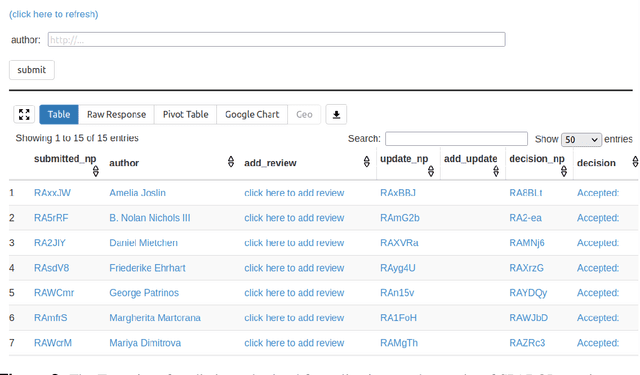
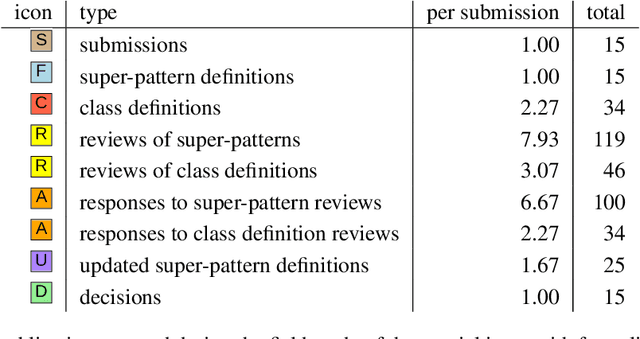
With the rapidly increasing amount of scientific literature,it is getting continuously more difficult for researchers in different disciplines to be updated with the recent findings in their field of study.Processing scientific articles in an automated fashion has been proposed as a solution to this problem,but the accuracy of such processing remains very poor for extraction tasks beyond the basic ones.Few approaches have tried to change how we publish scientific results in the first place,by making articles machine-interpretable by expressing them with formal semantics from the start.In the work presented here,we set out to demonstrate that we can formally publish high-level scientific claims in formal logic,and publish the results in a special issue of an existing journal.We use the concept and technology of nanopublications for this endeavor,and represent not just the submissions and final papers in this RDF-based format,but also the whole process in between,including reviews,responses,and decisions.We do this by performing a field study with what we call formalization papers,which contribute a novel formalization of a previously published claim.We received 15 submissions from 18 authors,who then went through the whole publication process leading to the publication of their contributions in the special issue.Our evaluation shows the technical and practical feasibility of our approach.The participating authors mostly showed high levels of interest and confidence,and mostly experienced the process as not very difficult,despite the technical nature of the current user interfaces.We believe that these results indicate that it is possible to publish scientific results from different fields with machine-interpretable semantics from the start,which in turn opens countless possibilities to radically improve in the future the effectiveness and efficiency of the scientific endeavor as a whole.
Expressing High-Level Scientific Claims with Formal Semantics
Sep 27, 2021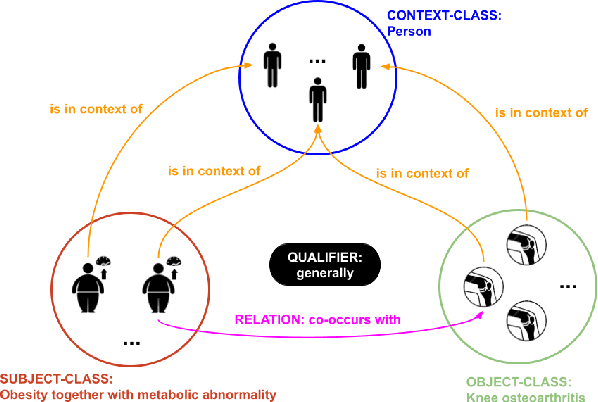
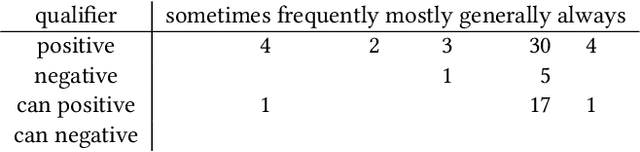
The use of semantic technologies is gaining significant traction in science communication with a wide array of applications in disciplines including the Life Sciences, Computer Science, and the Social Sciences. Languages like RDF, OWL, and other formalisms based on formal logic are applied to make scientific knowledge accessible not only to human readers but also to automated systems. These approaches have mostly focused on the structure of scientific publications themselves, on the used scientific methods and equipment, or on the structure of the used datasets. The core claims or hypotheses of scientific work have only been covered in a shallow manner, such as by linking mentioned entities to established identifiers. In this research, we therefore want to find out whether we can use existing semantic formalisms to fully express the content of high-level scientific claims using formal semantics in a systematic way. Analyzing the main claims from a sample of scientific articles from all disciplines, we find that their semantics are more complex than what a straight-forward application of formalisms like RDF or OWL account for, but we managed to elicit a clear semantic pattern which we call the 'super-pattern'. We show here how the instantiation of the five slots of this super-pattern leads to a strictly defined statement in higher-order logic. We successfully applied this super-pattern to an enlarged sample of scientific claims. We show that knowledge representation experts, when instructed to independently instantiate the super-pattern with given scientific claims, show a high degree of consistency and convergence given the complexity of the task and the subject. These results therefore open the door for expressing high-level scientific findings in a manner they can be automatically interpreted, which on the longer run can allow us to do automated consistency checking, and much more.
Provenance for Linguistic Corpora Through Nanopublications
Jun 11, 2020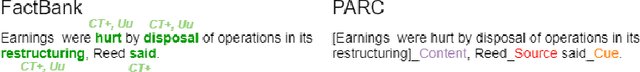
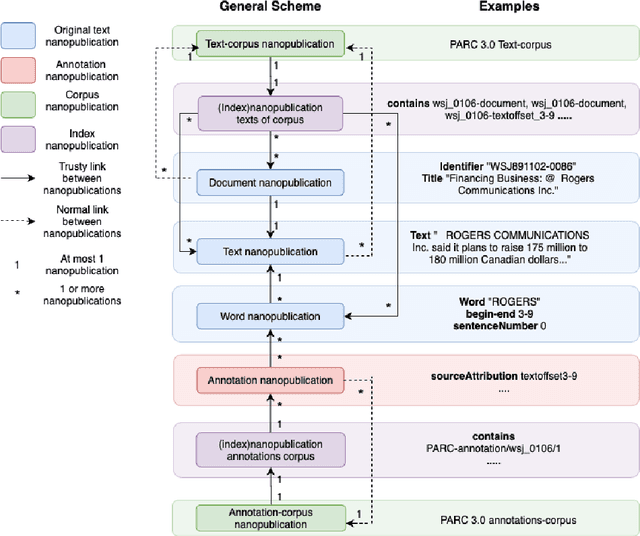
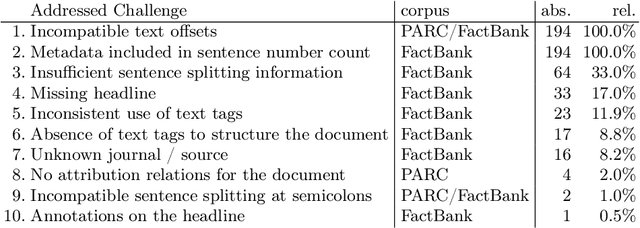
Research in Computational Linguistics is dependent on text corpora for training and testing new tools and methodologies. While there exists a plethora of annotated linguistic information, these corpora are often not interoperable without significant manual work. Moreover, these annotations might have adapted and might have evolved into different versions, making it challenging for researchers to know the data's provenance and merge it with other annotated corpora. In other words, these variations affect the interoperability between existing corpora. This paper addresses this issue with a case study on event annotated corpora and by creating a new, more interoperable representation of this data in the form of nanopublications. We demonstrate how linguistic annotations from separate corpora can be merged through a similar format to thereby make annotation content simultaneously accessible. The process for developing the nanopublications is described, and SPARQL queries are performed to extract interesting content from the new representations. The queries show that information of multiple corpora can now be retrieved more easily and effectively with the automated interoperability of the information of different corpora in a uniform data format.
Towards FAIR protocols and workflows: The OpenPREDICT case study
Nov 20, 2019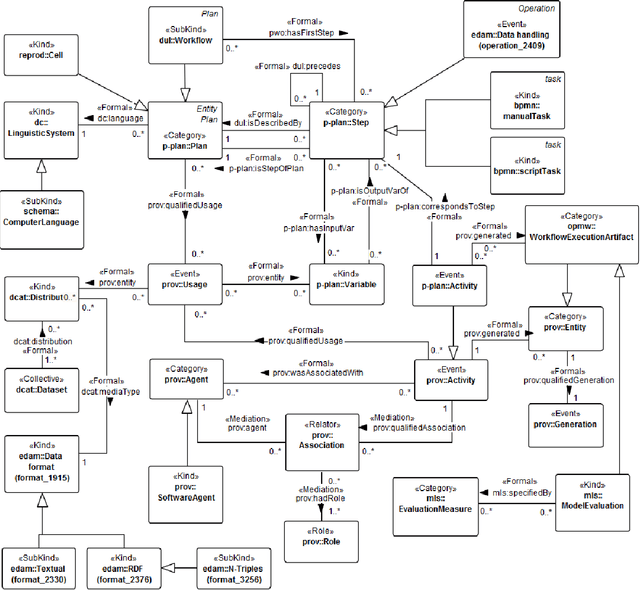
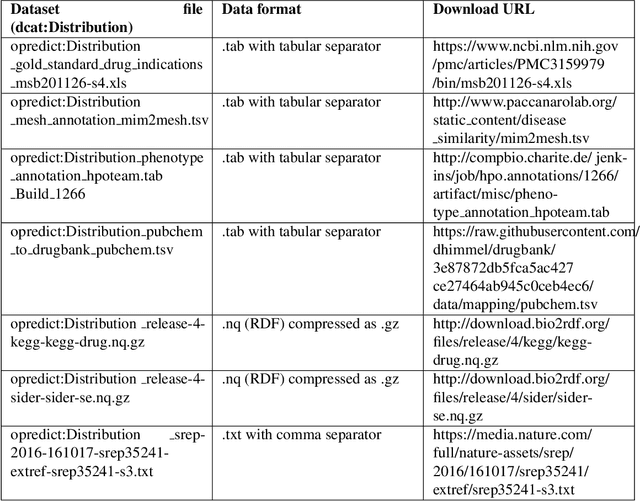
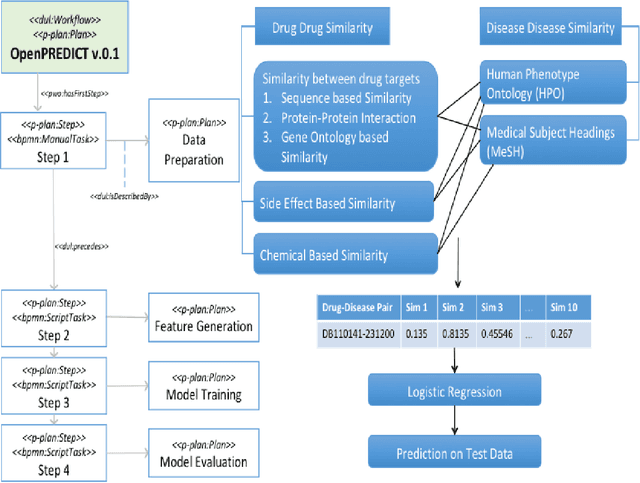
It is essential for the advancement of science that scientists and researchers share, reuse and reproduce workflows and protocols used by others. The FAIR principles are a set of guidelines that aim to maximize the value and usefulness of research data, and emphasize a number of important points regarding the means by which digital objects are found and reused by others. The question of how to apply these principles not just to the static input and output data but also to the dynamic workflows and protocols that consume and produce them is still under debate and poses a number of challenges. In this paper we describe our inclusive and overarching approach to apply the FAIR principles to workflows and protocols and demonstrate its benefits. We apply and evaluate our approach on a case study that consists of making the PREDICT workflow, a highly cited drug repurposing workflow, open and FAIR. This includes FAIRification of the involved datasets, as well as applying semantic technologies to represent and store data about the detailed versions of the general protocol, of the concrete workflow instructions, and of their execution traces. A semantic model was proposed to better address these specific requirements and were evaluated by answering competency questions. This semantic model consists of classes and relations from a number of existing ontologies, including Workflow4ever, PROV, EDAM, and BPMN. This allowed us then to formulate and answer new kinds of competency questions. Our evaluation shows the high degree to which our FAIRified OpenPREDICT workflow now adheres to the FAIR principles and the practicality and usefulness of being able to answer our new competency questions.
Supporting stylists by recommending fashion style
Aug 26, 2019
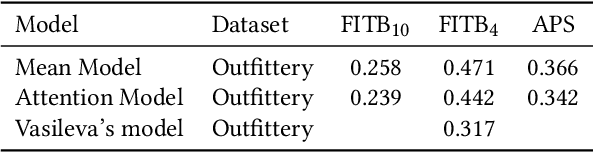

Outfittery is an online personalized styling service targeted at men. We have hundreds of stylists who create thousands of bespoke outfits for our customers every day. A critical challenge faced by our stylists when creating these outfits is selecting an appropriate item of clothing that makes sense in the context of the outfit being created, otherwise known as style fit. Another significant challenge is knowing if the item is relevant to the customer based on their tastes, physical attributes and price sensitivity. At Outfittery we leverage machine learning extensively and combine it with human domain expertise to tackle these challenges. We do this by surfacing relevant items of clothing during the outfit building process based on what our stylist is doing and what the preferences of our customer are. In this paper we describe one way in which we help our stylists to tackle style fit for a particular item of clothing and its relevance to an outfit. A thorough qualitative and quantitative evaluation highlights the method's ability to recommend fashion items by style fit.
Extracting Core Claims from Scientific Articles
Jul 24, 2017

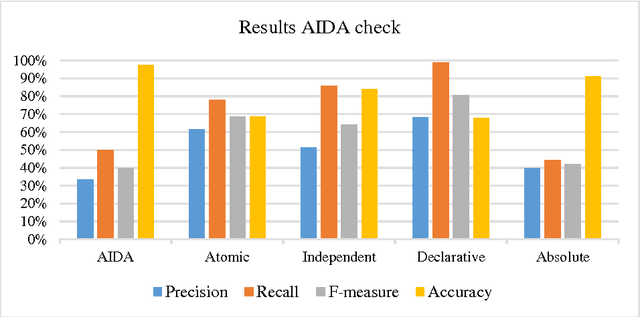
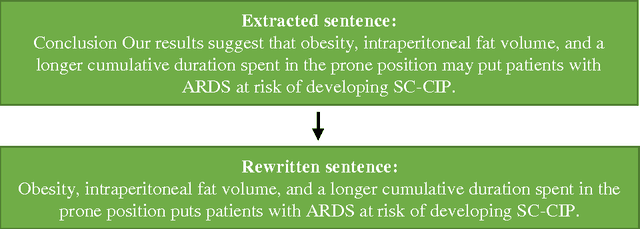
The number of scientific articles has grown rapidly over the years and there are no signs that this growth will slow down in the near future. Because of this, it becomes increasingly difficult to keep up with the latest developments in a scientific field. To address this problem, we present here an approach to help researchers learn about the latest developments and findings by extracting in a normalized form core claims from scientific articles. This normalized representation is a controlled natural language of English sentences called AIDA, which has been proposed in previous work as a method to formally structure and organize scientific findings and discourse. We show how such AIDA sentences can be automatically extracted by detecting the core claim of an article, checking for AIDA compliance, and - if necessary - transforming it into a compliant sentence. While our algorithm is still far from perfect, our results indicate that the different steps are feasible and they support the claim that AIDA sentences might be a promising approach to improve scientific communication in the future.
The Controlled Natural Language of Randall Munroe's Thing Explainer
May 09, 2016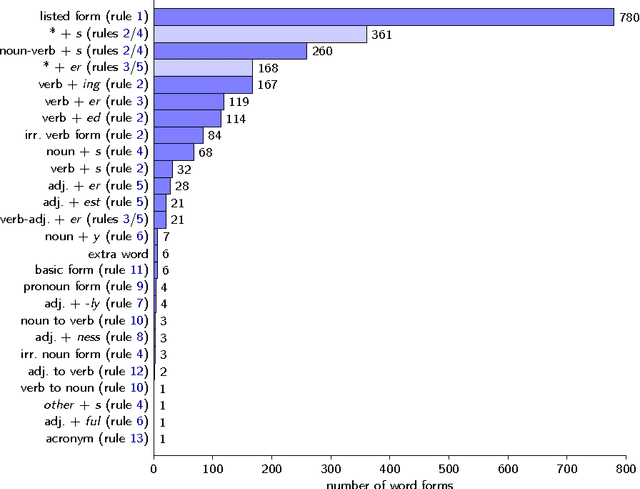
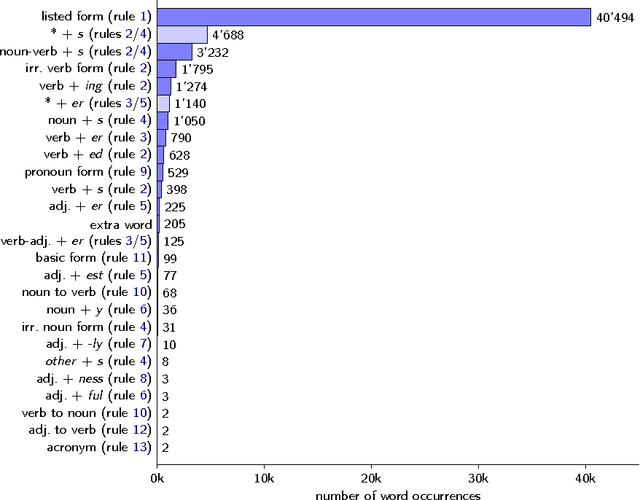
It is rare that texts or entire books written in a Controlled Natural Language (CNL) become very popular, but exactly this has happened with a book that has been published last year. Randall Munroe's Thing Explainer uses only the 1'000 most often used words of the English language together with drawn pictures to explain complicated things such as nuclear reactors, jet engines, the solar system, and dishwashers. This restricted language is a very interesting new case for the CNL community. I describe here its place in the context of existing approaches on Controlled Natural Languages, and I provide a first analysis from a scientific perspective, covering the word production rules and word distributions.
Fully automatic multi-language translation with a catalogue of phrases - successful employment for the Swiss avalanche bulletin
Sep 23, 2015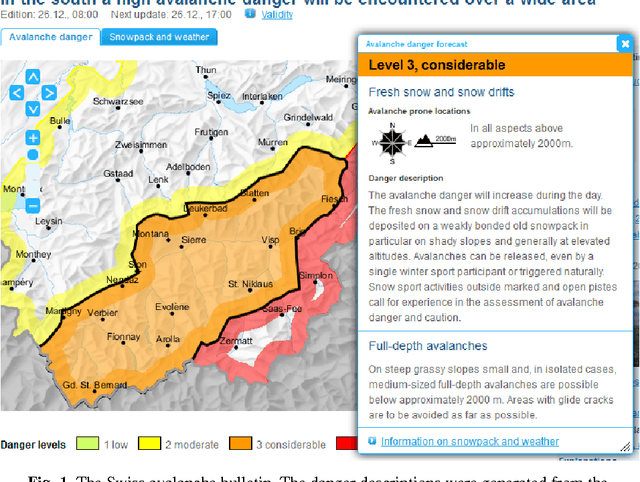


The Swiss avalanche bulletin is produced twice a day in four languages. Due to the lack of time available for manual translation, a fully automated translation system is employed, based on a catalogue of predefined phrases and predetermined rules of how these phrases can be combined to produce sentences. Because this catalogue of phrases is limited to a small sublanguage, the system is able to automatically translate such sentences from German into the target languages French, Italian and English without subsequent proofreading or correction. Having been operational for two winter seasons, we assess here the quality of the produced texts based on two different surveys where participants rated texts from real avalanche bulletins from both origins, the catalogue of phrases versus manually written and translated texts. With a mean recognition rate of 55%, users can hardly distinguish between thetwo types of texts, and give very similar ratings with respect to their language quality. Overall, the output from the catalogue system can be considered virtually equivalent to a text written by avalanche forecasters and then manually translated by professional translators. Furthermore, forecasters declared that all relevant situations were captured by the system with sufficient accuracy. Forecaster's working load did not change with the introduction of the catalogue: the extra time to find matching sentences is compensated by the fact that they no longer need to double-check manually translated texts. The reduction of daily translation costs is expected to offset the initial development costs within a few years.
A Survey and Classification of Controlled Natural Languages
Jul 07, 2015What is here called controlled natural language (CNL) has traditionally been given many different names. Especially during the last four decades, a wide variety of such languages have been designed. They are applied to improve communication among humans, to improve translation, or to provide natural and intuitive representations for formal notations. Despite the apparent differences, it seems sensible to put all these languages under the same umbrella. To bring order to the variety of languages, a general classification scheme is presented here. A comprehensive survey of existing English-based CNLs is given, listing and describing 100 languages from 1930 until today. Classification of these languages reveals that they form a single scattered cloud filling the conceptual space between natural languages such as English on the one end and formal languages such as propositional logic on the other. The goal of this article is to provide a common terminology and a common model for CNL, to contribute to the understanding of their general nature, to provide a starting point for researchers interested in the area, and to help developers to make design decisions.