 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Guided Monte Carlo Tree Search over Knowledge Graphs: Composing Mechanistic Explanations for Drug-Disease Pairs
May 10, 2026Extracting multi-step explanations from knowledge graphs poses a combinatorial challenge requiring both heuristic guidance (as candidates proliferate with depth) and credit assignment (as path quality emerges over extended sequences). Frontier LLMs, strong on knowledge/reasoning benchmarks, offer a compelling source of such heuristics, yet their knowledge comes sans guarantees and compositional performance degrades as chains lengthen. We thus present TESSERA, a 3-part neuro-symbolic framework that uses LLMs in a circumscribed role: for local discriminative judgement rather than autonomous multi-step generation; the knowledge graph then defines the hypothesis space enforcing hard structural constraints, and MCTS coordinates the long-horizon search with principled credit assignment via backpropagation. LLMs perform dual roles as a prior policy biasing exploration and a comparative state evaluator supplying reward signals. Evaluation on drug mechanism elucidation across two complementary knowledge graphs demonstrates fidelity to curated biology while surfacing coherent alternative mechanisms, with ablations confirming discriminative contribution from both LLM components. Beyond its current application, our framework offers a general paradigm for compositional reasoning over structured knowledge.
CompDiff: Hierarchical Compositional Diffusion for Fair and Zero-Shot Intersectional Medical Image Generation
Mar 17, 2026Generative models are increasingly used to augment medical imaging datasets for fairer AI. Yet a key assumption often goes unexamined: that generators themselves produce equally high-quality images across demographic groups. Models trained on imbalanced data can inherit these imbalances, yielding degraded synthesis quality for rare subgroups and struggling with demographic intersections absent from training. We refer to this as the imbalanced generator problem. Existing remedies such as loss reweighting operate at the optimization level and provide limited benefit when training signal is scarce or absent for certain combinations. We propose CompDiff, a hierarchical compositional diffusion framework that addresses this problem at the representation level. A dedicated Hierarchical Conditioner Network (HCN) decomposes demographic conditioning, producing a demographic token concatenated with CLIP embeddings as cross-attention context. This structured factorization encourages parameter sharing across subgroups and supports compositional generalization to rare or unseen demographic intersections. Experiments on chest X-rays (MIMIC-CXR) and fundus images (FairGenMed) show that CompDiff compares favorably against both standard fine-tuning and FairDiffusion across image quality (FID: 64.3 vs. 75.1), subgroup equity (ES-FID), and zero-shot intersectional generalization (up to 21% FID improvement on held-out intersections). Downstream classifiers trained on CompDiff-generated data also show improved AUROC and reduced demographic bias, suggesting that architectural design of demographic conditioning is an important and underexplored factor in fair medical image generation. Code is available at https://anonymous.4open.science/r/CompDiff-6FE6.
Data-Balanced Curriculum Learning for Audio Question Answering
Jul 09, 2025Audio question answering (AQA) requires models to understand acoustic content and perform complex reasoning. Current models struggle with dataset imbalances and unstable training dynamics. This work combines curriculum learning with statistical data balancing to address these challenges. The method labels question difficulty using language models, then trains progressively from easy to hard examples. Statistical filtering removes overrepresented audio categories, and guided decoding constrains outputs to valid multiple-choice formats. Experiments on the DCASE 2025 training set and five additional public datasets show that data curation improves accuracy by 11.7% over baseline models, achieving 64.2% on the DCASE 2025 benchmark.
Adapting Lightweight Vision Language Models for Radiological Visual Question Answering
Jun 17, 2025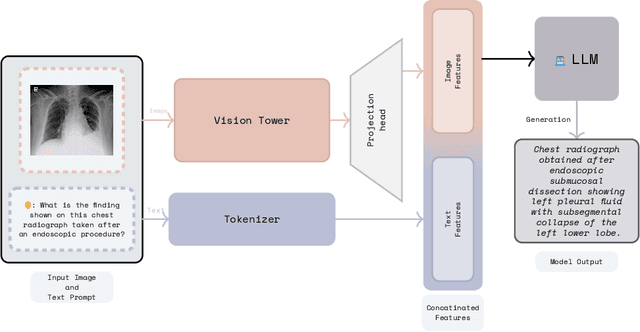

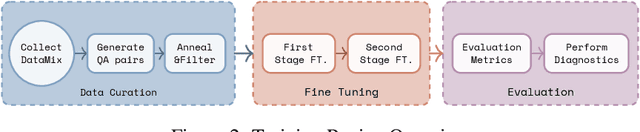
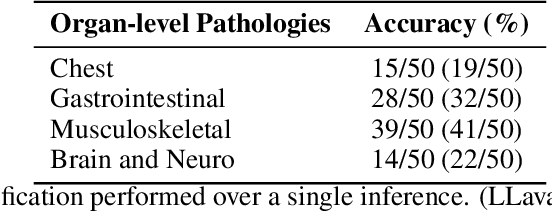
Recent advancements in vision-language systems have improved the accuracy of Radiological Visual Question Answering (VQA) Models. However, some challenges remain across each stage of model development: limited expert-labeled images hinders data procurement at scale; the intricate and nuanced patterns of radiological images make modeling inherently difficult; and the lack of evaluation evaluation efforts makes it difficult to identify cases where the model might be ill-conditioned. In this study, we fine-tune a lightweight 3B parameter vision-language model for Radiological VQA, demonstrating that small models, when appropriately tuned with curated data, can achieve robust performance across both open- and closed-ended questions. We propose a cost-effective training pipeline from synthetic question-answer pair generation to multi-stage fine-tuning on specialised radiological domain-targeted datasets (e.g., ROCO v2.0, MedPix v2.0). Our results show that despite operating at a fraction of the scale of state-of-the-art models such as LLaVA-Med, our model achieves promising performance given its small parameter size and the limited scale of training data. We introduce a lightweight saliency-based diagnostic tool that enables domain experts to inspect VQA model performance and identify ill-conditioned failure modes through saliency analysis.
AudSemThinker: Enhancing Audio-Language Models through Reasoning over Semantics of Sound
May 20, 2025Audio-language models have shown promising results in various sound understanding tasks, yet they remain limited in their ability to reason over the fine-grained semantics of sound. In this paper, we present AudSemThinker, a model whose reasoning is structured around a framework of auditory semantics inspired by human cognition. To support this, we introduce AudSem, a novel dataset specifically curated for semantic descriptor reasoning in audio-language models. AudSem addresses the persistent challenge of data contamination in zero-shot evaluations by providing a carefully filtered collection of audio samples paired with captions generated through a robust multi-stage pipeline. Our experiments demonstrate that AudSemThinker outperforms state-of-the-art models across multiple training settings, highlighting its strength in semantic audio reasoning. Both AudSemThinker and the AudSem dataset are released publicly.
CDE-Mapper: Using Retrieval-Augmented Language Models for Linking Clinical Data Elements to Controlled Vocabularies
May 07, 2025The standardization of clinical data elements (CDEs) aims to ensure consistent and comprehensive patient information across various healthcare systems. Existing methods often falter when standardizing CDEs of varying representation and complex structure, impeding data integration and interoperability in clinical research. We introduce CDE-Mapper, an innovative framework that leverages Retrieval-Augmented Generation approach combined with Large Language Models to automate the linking of CDEs to controlled vocabularies. Our modular approach features query decomposition to manage varying levels of CDEs complexity, integrates expert-defined rules within prompt engineering, and employs in-context learning alongside multiple retriever components to resolve terminological ambiguities. In addition, we propose a knowledge reservoir validated by a human-in-loop approach, achieving accurate concept linking for future applications while minimizing computational costs. For four diverse datasets, CDE-Mapper achieved an average of 7.2\% higher accuracy improvement compared to baseline methods. This work highlights the potential of advanced language models in improving data harmonization and significantly advancing capabilities in clinical decision support systems and research.
Semantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
Audio-Language Datasets of Scenes and Events: A Survey
Jul 09, 2024
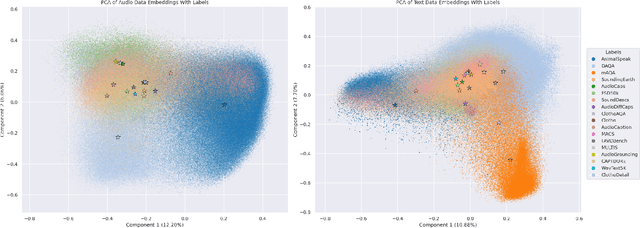
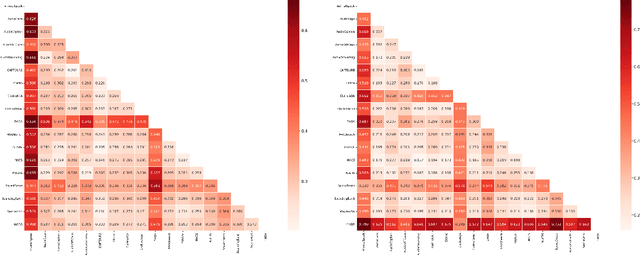
Audio-language models (ALMs) process sounds to provide a linguistic description of sound-producing events and scenes. Recent advances in computing power and dataset creation have led to significant progress in this domain. This paper surveys existing datasets used for training audio-language models, emphasizing the recent trend towards using large, diverse datasets to enhance model performance. Key sources of these datasets include the Freesound platform and AudioSet that have contributed to the field's rapid growth. Although prior surveys primarily address techniques and training details, this survey categorizes and evaluates a wide array of datasets, addressing their origins, characteristics, and use cases. It also performs a data leak analysis to ensure dataset integrity and mitigate bias between datasets. This survey was conducted by analyzing research papers up to and including December 2023, and does not contain any papers after that period.
Generative AI for Synthetic Data Across Multiple Medical Modalities: A Systematic Review of Recent Developments and Challenges
Jul 02, 2024
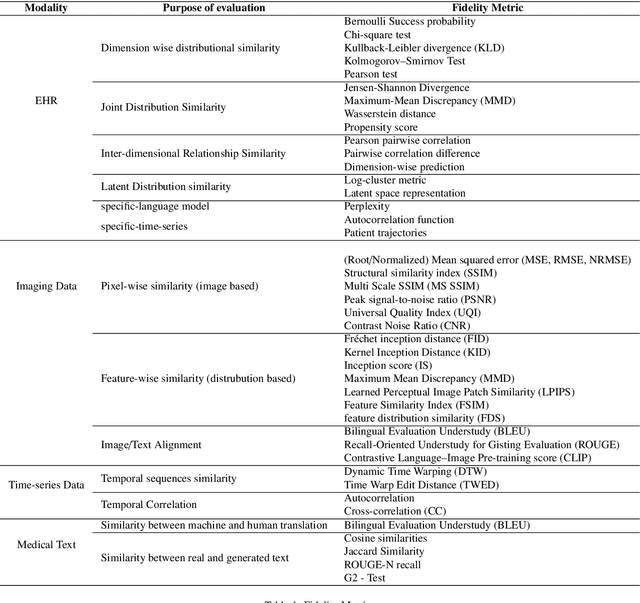

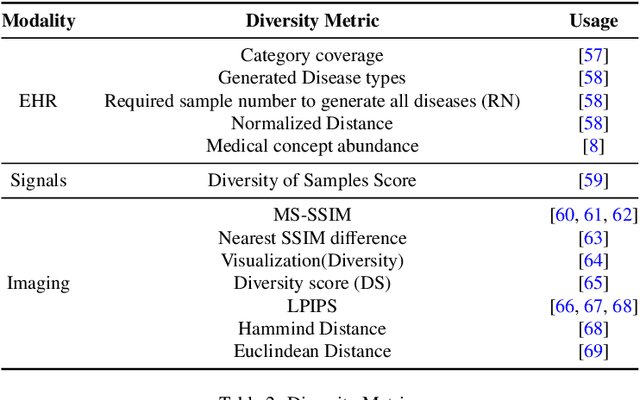
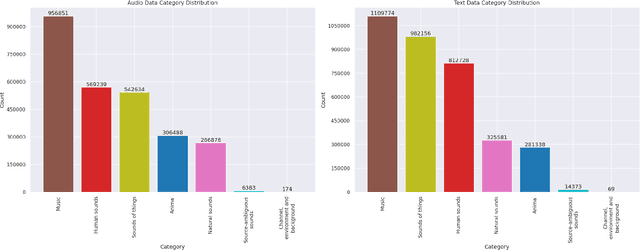
This paper presents a comprehensive systematic review of generative models (GANs, VAEs, DMs, and LLMs) used to synthesize various medical data types, including imaging (dermoscopic, mammographic, ultrasound, CT, MRI, and X-ray), text, time-series, and tabular data (EHR). Unlike previous narrowly focused reviews, our study encompasses a broad array of medical data modalities and explores various generative models. Our search strategy queries databases such as Scopus, PubMed, and ArXiv, focusing on recent works from January 2021 to November 2023, excluding reviews and perspectives. This period emphasizes recent advancements beyond GANs, which have been extensively covered previously. The survey reveals insights from three key aspects: (1) Synthesis applications and purpose of synthesis, (2) generation techniques, and (3) evaluation methods. It highlights clinically valid synthesis applications, demonstrating the potential of synthetic data to tackle diverse clinical requirements. While conditional models incorporating class labels, segmentation masks and image translations are prevalent, there is a gap in utilizing prior clinical knowledge and patient-specific context, suggesting a need for more personalized synthesis approaches and emphasizing the importance of tailoring generative approaches to the unique characteristics of medical data. Additionally, there is a significant gap in using synthetic data beyond augmentation, such as for validation and evaluation of downstream medical AI models. The survey uncovers that the lack of standardized evaluation methodologies tailored to medical images is a barrier to clinical application, underscoring the need for in-depth evaluation approaches, benchmarking, and comparative studies to promote openness and collaboration.
Improving rule mining via embedding-based link prediction
Jun 14, 2024


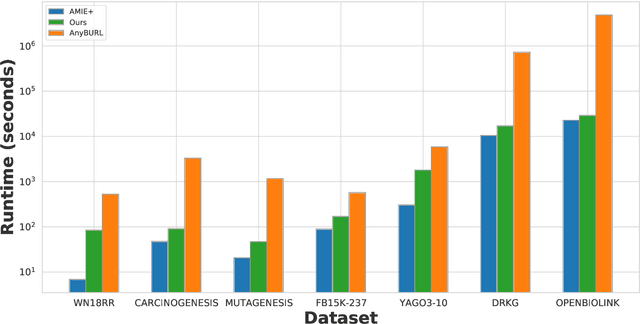
Rule mining on knowledge graphs allows for explainable link prediction. Contrarily, embedding-based methods for link prediction are well known for their generalization capabilities, but their predictions are not interpretable. Several approaches combining the two families have been proposed in recent years. The majority of the resulting hybrid approaches are usually trained within a unified learning framework, which often leads to convergence issues due to the complexity of the learning task. In this work, we propose a new way to combine the two families of approaches. Specifically, we enrich a given knowledge graph by means of its pre-trained entity and relation embeddings before applying rule mining systems on the enriched knowledge graph. To validate our approach, we conduct extensive experiments on seven benchmark datasets. An analysis of the results generated by our approach suggests that we discover new valuable rules on the enriched graphs. We provide an open source implementation of our approach as well as pretrained models and datasets at https://github.com/Jean-KOUAGOU/EnhancedRuleLearning