 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Balanced Curriculum Learning for Audio Question Answering
Jul 09, 2025Audio question answering (AQA) requires models to understand acoustic content and perform complex reasoning. Current models struggle with dataset imbalances and unstable training dynamics. This work combines curriculum learning with statistical data balancing to address these challenges. The method labels question difficulty using language models, then trains progressively from easy to hard examples. Statistical filtering removes overrepresented audio categories, and guided decoding constrains outputs to valid multiple-choice formats. Experiments on the DCASE 2025 training set and five additional public datasets show that data curation improves accuracy by 11.7% over baseline models, achieving 64.2% on the DCASE 2025 benchmark.
AudSemThinker: Enhancing Audio-Language Models through Reasoning over Semantics of Sound
May 20, 2025Audio-language models have shown promising results in various sound understanding tasks, yet they remain limited in their ability to reason over the fine-grained semantics of sound. In this paper, we present AudSemThinker, a model whose reasoning is structured around a framework of auditory semantics inspired by human cognition. To support this, we introduce AudSem, a novel dataset specifically curated for semantic descriptor reasoning in audio-language models. AudSem addresses the persistent challenge of data contamination in zero-shot evaluations by providing a carefully filtered collection of audio samples paired with captions generated through a robust multi-stage pipeline. Our experiments demonstrate that AudSemThinker outperforms state-of-the-art models across multiple training settings, highlighting its strength in semantic audio reasoning. Both AudSemThinker and the AudSem dataset are released publicly.
Audio-Language Datasets of Scenes and Events: A Survey
Jul 09, 2024
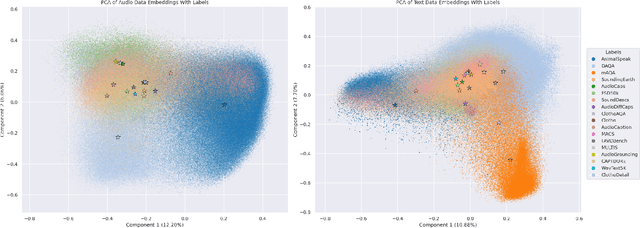
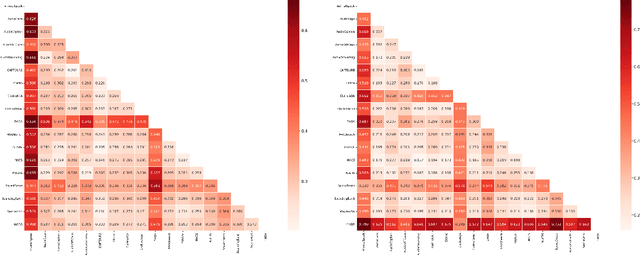
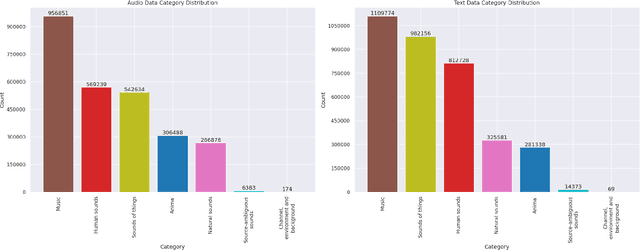
Audio-language models (ALMs) process sounds to provide a linguistic description of sound-producing events and scenes. Recent advances in computing power and dataset creation have led to significant progress in this domain. This paper surveys existing datasets used for training audio-language models, emphasizing the recent trend towards using large, diverse datasets to enhance model performance. Key sources of these datasets include the Freesound platform and AudioSet that have contributed to the field's rapid growth. Although prior surveys primarily address techniques and training details, this survey categorizes and evaluates a wide array of datasets, addressing their origins, characteristics, and use cases. It also performs a data leak analysis to ensure dataset integrity and mitigate bias between datasets. This survey was conducted by analyzing research papers up to and including December 2023, and does not contain any papers after that period.
ACES: Evaluating Automated Audio Captioning Models on the Semantics of Sounds
Mar 27, 2024



Automated Audio Captioning is a multimodal task that aims to convert audio content into natural language. The assessment of audio captioning systems is typically based on quantitative metrics applied to text data. Previous studies have employed metrics derived from machine translation and image captioning to evaluate the quality of generated audio captions. Drawing inspiration from auditory cognitive neuroscience research, we introduce a novel metric approach -- Audio Captioning Evaluation on Semantics of Sound (ACES). ACES takes into account how human listeners parse semantic information from sounds, providing a novel and comprehensive evaluation perspective for automated audio captioning systems. ACES combines semantic similarities and semantic entity labeling. ACES outperforms similar automated audio captioning metrics on the Clotho-Eval FENSE benchmark in two evaluation categories.