 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Language Datasets of Scenes and Events: A Survey
Paper and Code

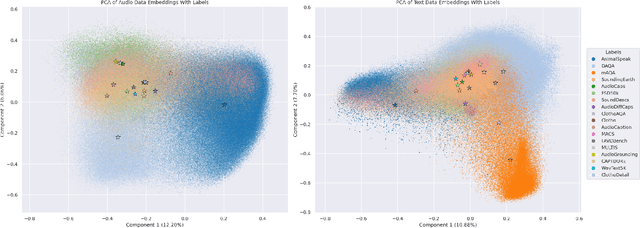
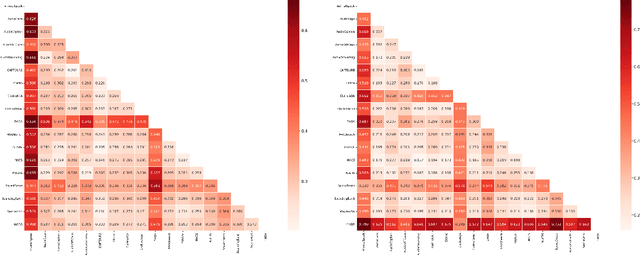
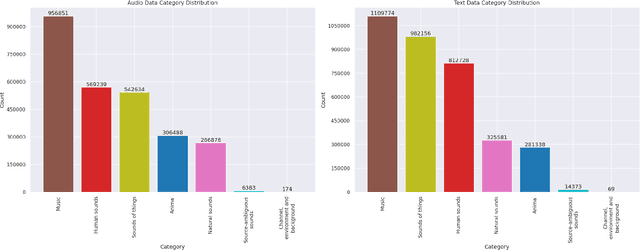
Audio-language models (ALMs) process sounds to provide a linguistic description of sound-producing events and scenes. Recent advances in computing power and dataset creation have led to significant progress in this domain. This paper surveys existing datasets used for training audio-language models, emphasizing the recent trend towards using large, diverse datasets to enhance model performance. Key sources of these datasets include the Freesound platform and AudioSet that have contributed to the field's rapid growth. Although prior surveys primarily address techniques and training details, this survey categorizes and evaluates a wide array of datasets, addressing their origins, characteristics, and use cases. It also performs a data leak analysis to ensure dataset integrity and mitigate bias between datasets. This survey was conducted by analyzing research papers up to and including December 2023, and does not contain any papers after that period.