 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDE-Mapper: Using Retrieval-Augmented Language Models for Linking Clinical Data Elements to Controlled Vocabularies
May 07, 2025The standardization of clinical data elements (CDEs) aims to ensure consistent and comprehensive patient information across various healthcare systems. Existing methods often falter when standardizing CDEs of varying representation and complex structure, impeding data integration and interoperability in clinical research. We introduce CDE-Mapper, an innovative framework that leverages Retrieval-Augmented Generation approach combined with Large Language Models to automate the linking of CDEs to controlled vocabularies. Our modular approach features query decomposition to manage varying levels of CDEs complexity, integrates expert-defined rules within prompt engineering, and employs in-context learning alongside multiple retriever components to resolve terminological ambiguities. In addition, we propose a knowledge reservoir validated by a human-in-loop approach, achieving accurate concept linking for future applications while minimizing computational costs. For four diverse datasets, CDE-Mapper achieved an average of 7.2\% higher accuracy improvement compared to baseline methods. This work highlights the potential of advanced language models in improving data harmonization and significantly advancing capabilities in clinical decision support systems and research.
Optimising MFCC parameters for the automatic detection of respiratory diseases
Aug 14, 2024Voice signals originating from the respiratory tract are utilized as valuable acoustic biomarkers for the diagnosis and assessment of respiratory diseases. Among the employed acoustic features, Mel Frequency Cepstral Coefficients (MFCC) is widely used for automatic analysis, with MFCC extraction commonly relying on default parameters. However, no comprehensive study has systematically investigated the impact of MFCC extraction parameters on respiratory disease diagnosis. In this study, we address this gap by examining the effects of key parameters, namely the number of coefficients, frame length, and hop length between frames, on respiratory condition examination. Our investigation uses four datasets: the Cambridge COVID-19 Sound database, the Coswara dataset, the Saarbrucken Voice Disorders (SVD) database, and a TACTICAS dataset. The Support Vector Machine (SVM) is employed as the classifier, given its widespread adoption and efficacy. Our findings indicate that the accuracy of MFCC decreases as hop length increases, and the optimal number of coefficients is observed to be approximately 30. The performance of MFCC varies with frame length across the datasets: for the COVID-19 datasets (Cambridge COVID-19 Sound database and Coswara dataset), performance declines with longer frame lengths, while for the SVD dataset, performance improves with increasing frame length (from 50 ms to 500 ms). Furthermore, we investigate the optimized combination of these parameters and observe substantial enhancements in accuracy. Compared to the worst combination, the SVM model achieves an accuracy of 81.1%, 80.6%, and 71.7%, with improvements of 19.6%, 16.10%, and 14.90% for the Cambridge COVID-19 Sound database, the Coswara dataset, and the SVD dataset respectively.
Developing a Multi-variate Prediction Model For COVID-19 From Crowd-sourced Respiratory Voice Data
Feb 12, 2024



COVID-19 has affected more than 223 countries worldwide and in the Post-COVID Era, there is a pressing need for non-invasive, low-cost, and highly scalable solutions to detect COVID-19. We develop a deep learning model to identify COVID-19 from voice recording data. The novelty of this work is in the development of deep learning models for COVID-19 identification from only voice recordings. We use the Cambridge COVID-19 Sound database which contains 893 speech samples, crowd-sourced from 4352 participants via a COVID-19 Sounds app. Voice features including Mel-spectrograms and Mel-frequency cepstral coefficients (MFCC) and CNN Encoder features are extracted. Based on the voice data, we develop deep learning classification models to detect COVID-19 cases. These models include Long Short-Term Memory (LSTM) and Convolutional Neural Network (CNN) and Hidden-Unit BERT (HuBERT). We compare their predictive power to baseline machine learning models. HuBERT achieves the highest accuracy of 86\% and the highest AUC of 0.93. The results achieved with the proposed models suggest promising results in COVID-19 diagnosis from voice recordings when compared to the results obtained from the state-of-the-art.
TAPS Responsibility Matrix: A tool for responsible data science by design
Feb 02, 2023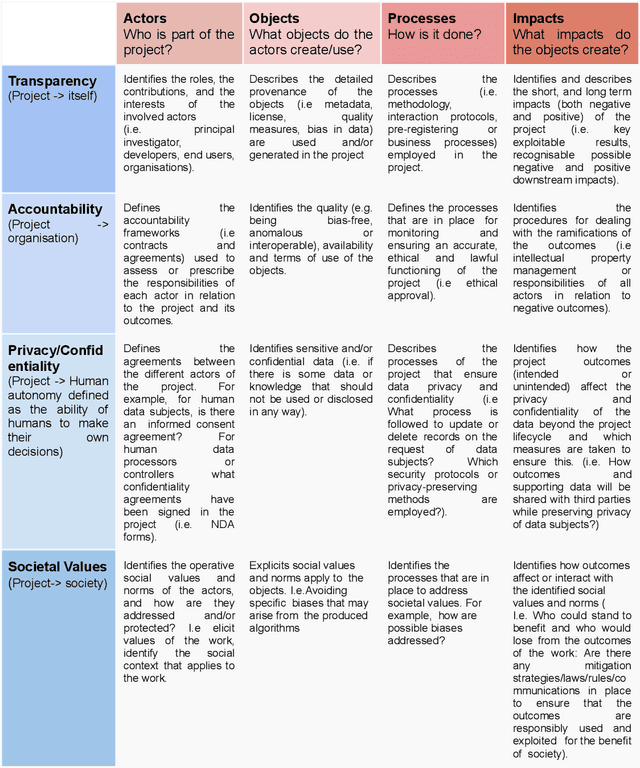

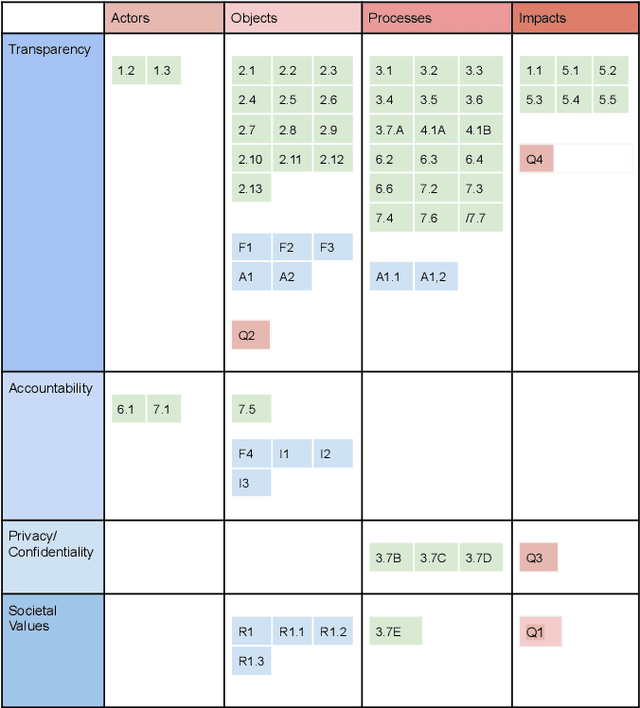
Data science is an interdisciplinary research area where scientists are typically working with data coming from different fields. When using and analyzing data, the scientists implicitly agree to follow standards, procedures, and rules set in these fields. However, guidance on the responsibilities of the data scientists and the other involved actors in a data science project is typically missing. While literature shows that novel frameworks and tools are being proposed in support of open-science, data reuse, and research data management, there are currently no frameworks that can fully express responsibilities of a data science project. In this paper, we describe the Transparency, Accountability, Privacy, and Societal Responsibility Matrix (TAPS-RM) as framework to explore social, legal, and ethical aspects of data science projects. TAPS-RM acts as a tool to provide users with a holistic view of their project beyond key outcomes and clarifies the responsibilities of actors. We map the developed model of TAPS-RM with well-known initiatives for open data (such as FACT, FAIR and Datasheets for datasets). We conclude that TAPS-RM is a tool to reflect on responsibilities at a data science project level and can be used to advance responsible data science by design.
Developing a multi-variate prediction model for the detection of COVID-19 from Crowd-sourced Respiratory Voice Data
Sep 08, 2022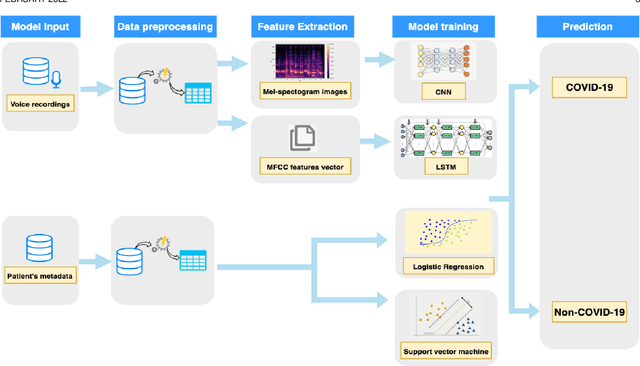
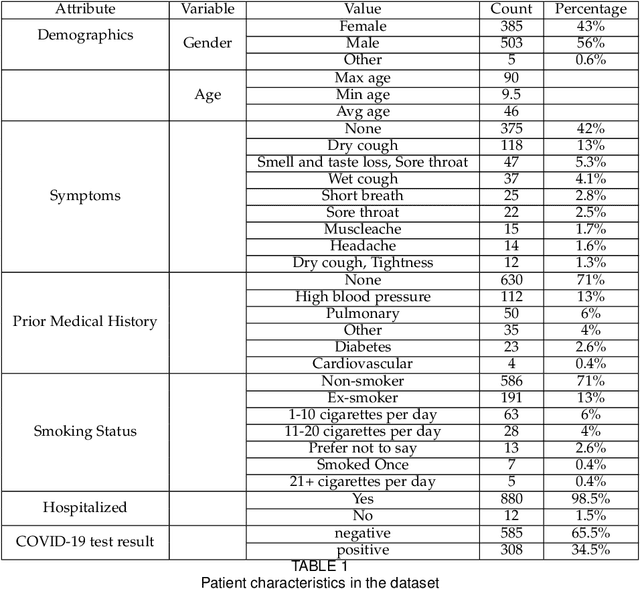
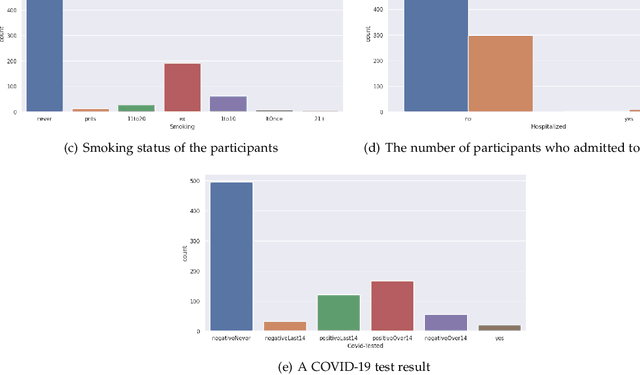
COVID-19 has affected more than 223 countries worldwide. There is a pressing need for non invasive, low costs and highly scalable solutions to detect COVID-19, especially in low-resource countries where PCR testing is not ubiquitously available. Our aim is to develop a deep learning model identifying COVID-19 using voice data recordings spontaneously provided by the general population (voice recordings and a short questionnaire) via their personal devices. The novelty of this work is in the development of a deep learning model for the identification of COVID-19 patients from voice recordings. Methods: We used the Cambridge University dataset consisting of 893 audio samples, crowd-sourced from 4352 participants that used a COVID-19 Sounds app. Voice features were extracted using a Mel-spectrogram analysis. Based on the voice data, we developed deep learning classification models to detect positive COVID-19 cases. These models included Long-Short Term Memory (LSTM) and Convolutional Neural Network (CNN). We compared their predictive power to baseline classification models, namely Logistic Regression and Support Vector Machine. Results: LSTM based on a Mel-frequency cepstral coefficients (MFCC) features achieved the highest accuracy (89%,) with a sensitivity and specificity of respectively 89% and 89%, The results achieved with the proposed model suggest a significant improvement in the prediction accuracy of COVID-19 diagnosis compared to the results obtained in the state of the art. Conclusion: Deep learning can detect subtle changes in the voice of COVID-19 patients with promising results. As an addition to the current testing techniques this model may aid health professionals in fast diagnosis and tracing of COVID-19 cases using simple voice analysis