 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding the Vocabulary of BERT for Knowledge Base Construction
Oct 12, 2023



Knowledge base construction entails acquiring structured information to create a knowledge base of factual and relational data, facilitating question answering, information retrieval, and semantic understanding. The challenge called "Knowledge Base Construction from Pretrained Language Models" at International Semantic Web Conference 2023 defines tasks focused on constructing knowledge base using language model. Our focus was on Track 1 of the challenge, where the parameters are constrained to a maximum of 1 billion, and the inclusion of entity descriptions within the prompt is prohibited. Although the masked language model offers sufficient flexibility to extend its vocabulary, it is not inherently designed for multi-token prediction. To address this, we present Vocabulary Expandable BERT for knowledge base construction, which expand the language model's vocabulary while preserving semantic embeddings for newly added words. We adopt task-specific re-pre-training on masked language model to further enhance the language model. Through experimentation, the results show the effectiveness of our approaches. Our framework achieves F1 score of 0.323 on the hidden test set and 0.362 on the validation set, both data set is provided by the challenge. Notably, our framework adopts a lightweight language model (BERT-base, 0.13 billion parameters) and surpasses the model using prompts directly on large language model (Chatgpt-3, 175 billion parameters). Besides, Token-Recode achieves comparable performances as Re-pretrain. This research advances language understanding models by enabling the direct embedding of multi-token entities, signifying a substantial step forward in link prediction task in knowledge graph and metadata completion in data management.
TAPS Responsibility Matrix: A tool for responsible data science by design
Feb 02, 2023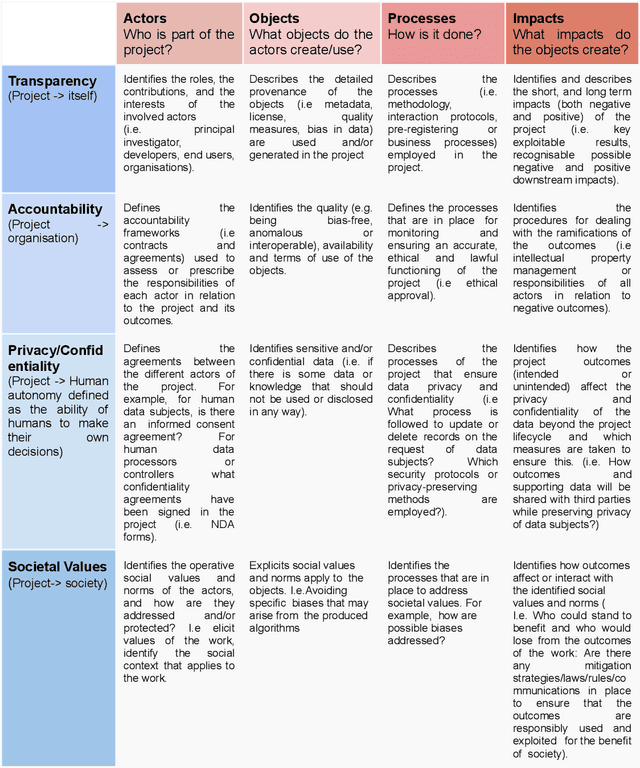

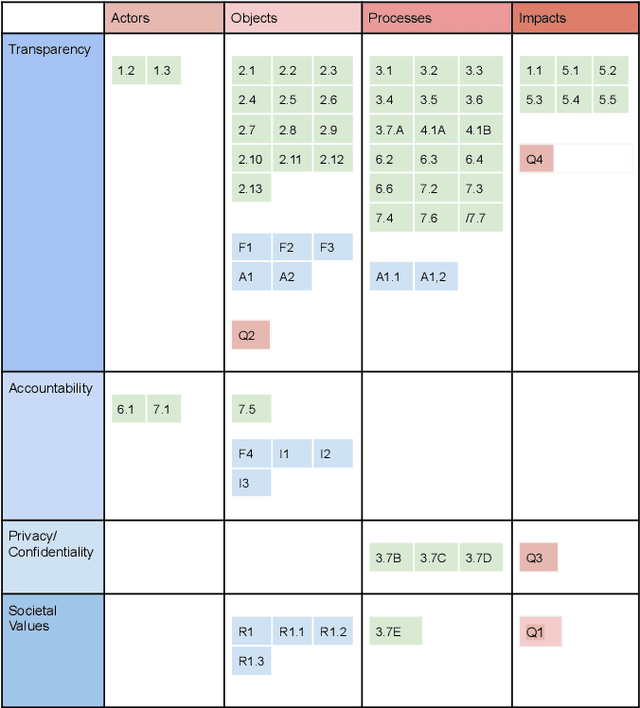
Data science is an interdisciplinary research area where scientists are typically working with data coming from different fields. When using and analyzing data, the scientists implicitly agree to follow standards, procedures, and rules set in these fields. However, guidance on the responsibilities of the data scientists and the other involved actors in a data science project is typically missing. While literature shows that novel frameworks and tools are being proposed in support of open-science, data reuse, and research data management, there are currently no frameworks that can fully express responsibilities of a data science project. In this paper, we describe the Transparency, Accountability, Privacy, and Societal Responsibility Matrix (TAPS-RM) as framework to explore social, legal, and ethical aspects of data science projects. TAPS-RM acts as a tool to provide users with a holistic view of their project beyond key outcomes and clarifies the responsibilities of actors. We map the developed model of TAPS-RM with well-known initiatives for open data (such as FACT, FAIR and Datasheets for datasets). We conclude that TAPS-RM is a tool to reflect on responsibilities at a data science project level and can be used to advance responsible data science by design.
Towards FAIR protocols and workflows: The OpenPREDICT case study
Nov 20, 2019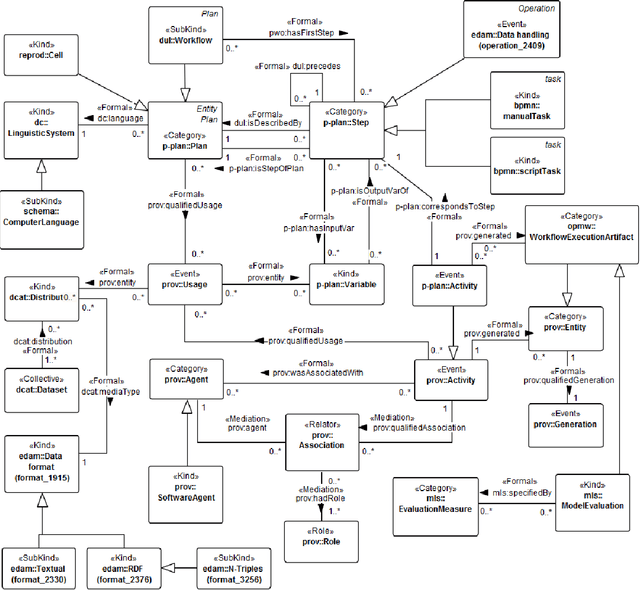
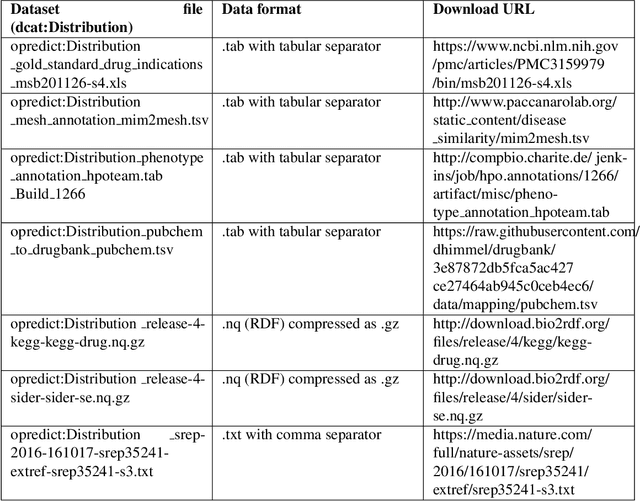
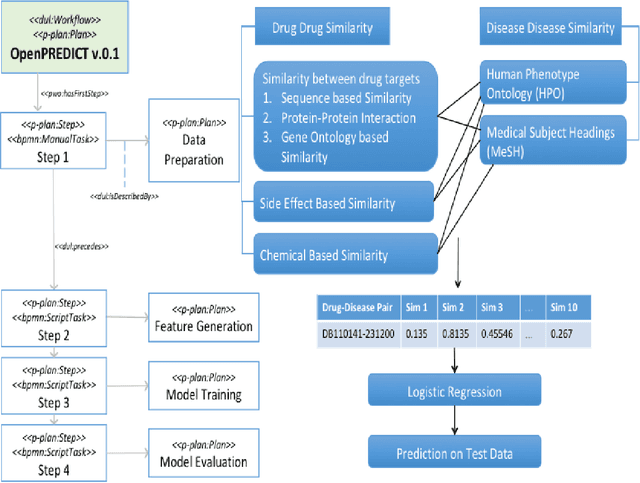
It is essential for the advancement of science that scientists and researchers share, reuse and reproduce workflows and protocols used by others. The FAIR principles are a set of guidelines that aim to maximize the value and usefulness of research data, and emphasize a number of important points regarding the means by which digital objects are found and reused by others. The question of how to apply these principles not just to the static input and output data but also to the dynamic workflows and protocols that consume and produce them is still under debate and poses a number of challenges. In this paper we describe our inclusive and overarching approach to apply the FAIR principles to workflows and protocols and demonstrate its benefits. We apply and evaluate our approach on a case study that consists of making the PREDICT workflow, a highly cited drug repurposing workflow, open and FAIR. This includes FAIRification of the involved datasets, as well as applying semantic technologies to represent and store data about the detailed versions of the general protocol, of the concrete workflow instructions, and of their execution traces. A semantic model was proposed to better address these specific requirements and were evaluated by answering competency questions. This semantic model consists of classes and relations from a number of existing ontologies, including Workflow4ever, PROV, EDAM, and BPMN. This allowed us then to formulate and answer new kinds of competency questions. Our evaluation shows the high degree to which our FAIRified OpenPREDICT workflow now adheres to the FAIR principles and the practicality and usefulness of being able to answer our new competency questions.