 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a multi-variate prediction model for the detection of COVID-19 from Crowd-sourced Respiratory Voice Data
Sep 08, 2022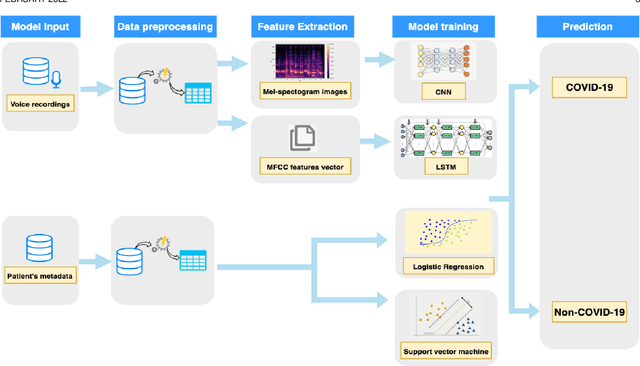
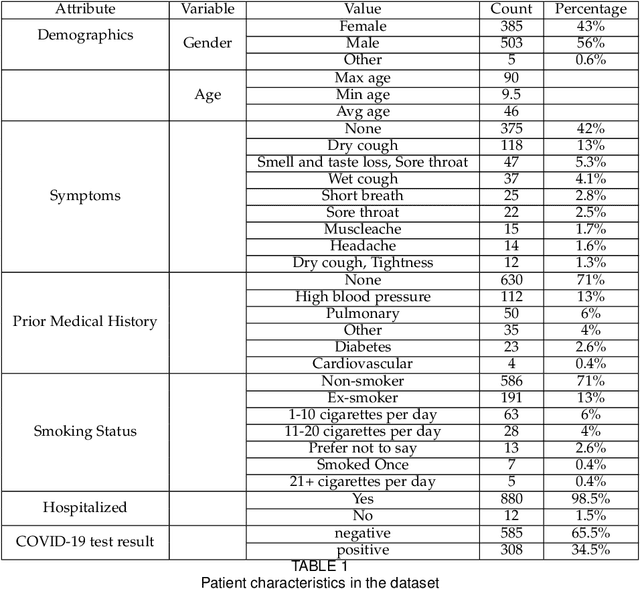
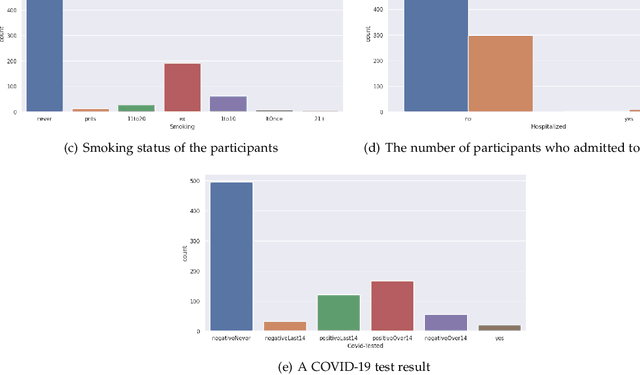
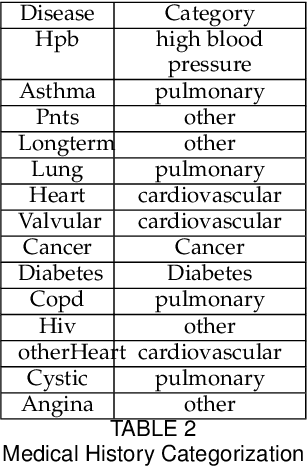
COVID-19 has affected more than 223 countries worldwide. There is a pressing need for non invasive, low costs and highly scalable solutions to detect COVID-19, especially in low-resource countries where PCR testing is not ubiquitously available. Our aim is to develop a deep learning model identifying COVID-19 using voice data recordings spontaneously provided by the general population (voice recordings and a short questionnaire) via their personal devices. The novelty of this work is in the development of a deep learning model for the identification of COVID-19 patients from voice recordings. Methods: We used the Cambridge University dataset consisting of 893 audio samples, crowd-sourced from 4352 participants that used a COVID-19 Sounds app. Voice features were extracted using a Mel-spectrogram analysis. Based on the voice data, we developed deep learning classification models to detect positive COVID-19 cases. These models included Long-Short Term Memory (LSTM) and Convolutional Neural Network (CNN). We compared their predictive power to baseline classification models, namely Logistic Regression and Support Vector Machine. Results: LSTM based on a Mel-frequency cepstral coefficients (MFCC) features achieved the highest accuracy (89%,) with a sensitivity and specificity of respectively 89% and 89%, The results achieved with the proposed model suggest a significant improvement in the prediction accuracy of COVID-19 diagnosis compared to the results obtained in the state of the art. Conclusion: Deep learning can detect subtle changes in the voice of COVID-19 patients with promising results. As an addition to the current testing techniques this model may aid health professionals in fast diagnosis and tracing of COVID-19 cases using simple voice analysis