 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
Apr 13, 2026Clinical deployment of automated brain MRI analysis faces a fundamental challenge: clinical data is heterogeneous and noisy, and high-quality labels are prohibitively costly to obtain. Self-supervised learning (SSL) can address this by leveraging the vast amounts of unlabeled data produced in clinical workflows to train robust \textit{foundation models} that adapt out-of-domain with minimal supervision. However, the development of foundation models for brain MRI has been limited by small pretraining datasets and in-domain benchmarking focused on high-quality, research-grade data. To address this gap, we organized the FOMO25 challenge as a satellite event at MICCAI 2025. FOMO25 provided participants with a large pretraining dataset, FOMO60K, and evaluated models on data sourced directly from clinical workflows in few-shot and out-of-domain settings. Tasks covered infarct classification, meningioma segmentation, and brain age regression, and considered both models trained on FOMO60K (method track) and any data (open track). Nineteen foundation models from sixteen teams were evaluated using a standardized containerized pipeline. Results show that (a) self-supervised pretraining improves generalization on clinical data under domain shift, with the strongest models trained \textit{out-of-domain} surpassing supervised baselines trained \textit{in-domain}. (b) No single pretraining objective benefits all tasks: MAE favors segmentation, hybrid reconstruction-contrastive objectives favor classification, and (c) strong performance was achieved by small pretrained models, and improvements from scaling model size and training duration did not yield reliable benefits.
Comparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
Scaling up self-supervised learning for improved surgical foundation models
Jan 16, 2025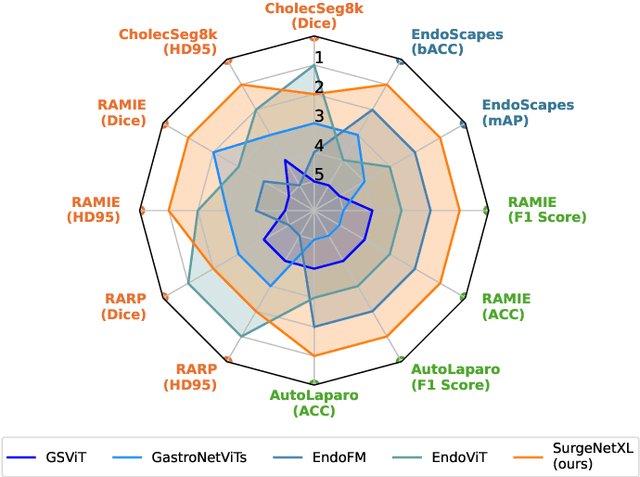
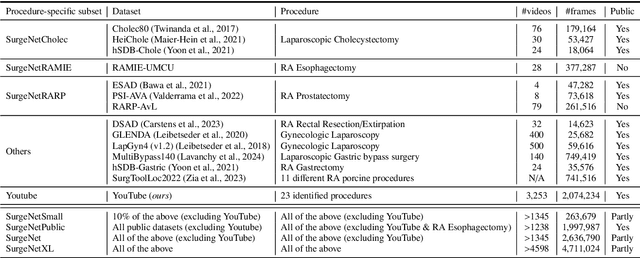
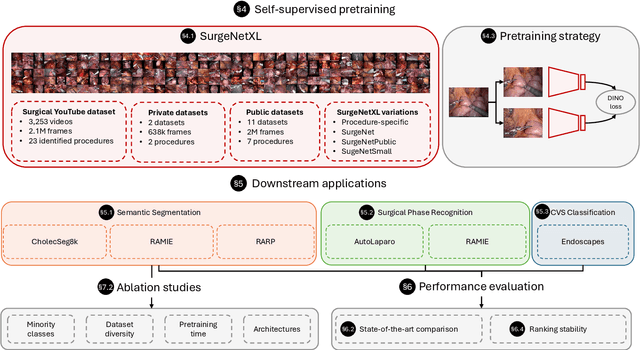
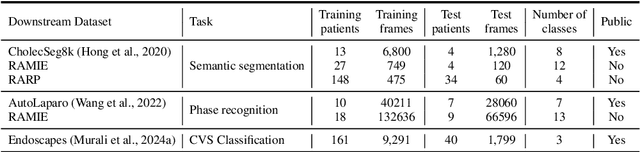
Foundation models have revolutionized computer vision by achieving vastly superior performance across diverse tasks through large-scale pretraining on extensive datasets. However, their application in surgical computer vision has been limited. This study addresses this gap by introducing SurgeNetXL, a novel surgical foundation model that sets a new benchmark in surgical computer vision. Trained on the largest reported surgical dataset to date, comprising over 4.7 million video frames, SurgeNetXL achieves consistent top-tier performance across six datasets spanning four surgical procedures and three tasks, including semantic segmentation, phase recognition, and critical view of safety (CVS) classification. Compared with the best-performing surgical foundation models, SurgeNetXL shows mean improvements of 2.4, 9.0, and 12.6 percent for semantic segmentation, phase recognition, and CVS classification, respectively. Additionally, SurgeNetXL outperforms the best-performing ImageNet-based variants by 14.4, 4.0, and 1.6 percent in the respective tasks. In addition to advancing model performance, this study provides key insights into scaling pretraining datasets, extending training durations, and optimizing model architectures specifically for surgical computer vision. These findings pave the way for improved generalizability and robustness in data-scarce scenarios, offering a comprehensive framework for future research in this domain. All models and a subset of the SurgeNetXL dataset, including over 2 million video frames, are publicly available at: https://github.com/TimJaspers0801/SurgeNet.
Benchmarking and Enhancing Surgical Phase Recognition Models for Robotic-Assisted Esophagectomy
Dec 05, 2024



Robotic-assisted minimally invasive esophagectomy (RAMIE) is a recognized treatment for esophageal cancer, offering better patient outcomes compared to open surgery and traditional minimally invasive surgery. RAMIE is highly complex, spanning multiple anatomical areas and involving repetitive phases and non-sequential phase transitions. Our goal is to leverage deep learning for surgical phase recognition in RAMIE to provide intraoperative support to surgeons. To achieve this, we have developed a new surgical phase recognition dataset comprising 27 videos. Using this dataset, we conducted a comparative analysis of state-of-the-art surgical phase recognition models. To more effectively capture the temporal dynamics of this complex procedure, we developed a novel deep learning model featuring an encoder-decoder structure with causal hierarchical attention, which demonstrates superior performance compared to existing models.
Exploring the Effect of Dataset Diversity in Self-Supervised Learning for Surgical Computer Vision
Jul 26, 2024Over the past decade, computer vision applications in minimally invasive surgery have rapidly increased. Despite this growth, the impact of surgical computer vision remains limited compared to other medical fields like pathology and radiology, primarily due to the scarcity of representative annotated data. Whereas transfer learning from large annotated datasets such as ImageNet has been conventionally the norm to achieve high-performing models, recent advancements in self-supervised learning (SSL) have demonstrated superior performance. In medical image analysis, in-domain SSL pretraining has already been shown to outperform ImageNet-based initialization. Although unlabeled data in the field of surgical computer vision is abundant, the diversity within this data is limited. This study investigates the role of dataset diversity in SSL for surgical computer vision, comparing procedure-specific datasets against a more heterogeneous general surgical dataset across three different downstream surgical applications. The obtained results show that using solely procedure-specific data can lead to substantial improvements of 13.8%, 9.5%, and 36.8% compared to ImageNet pretraining. However, extending this data with more heterogeneous surgical data further increases performance by an additional 5.0%, 5.2%, and 2.5%, suggesting that increasing diversity within SSL data is beneficial for model performance. The code and pretrained model weights are made publicly available at https://github.com/TimJaspers0801/SurgeNet.
Generative AI for Synthetic Data Across Multiple Medical Modalities: A Systematic Review of Recent Developments and Challenges
Jul 02, 2024
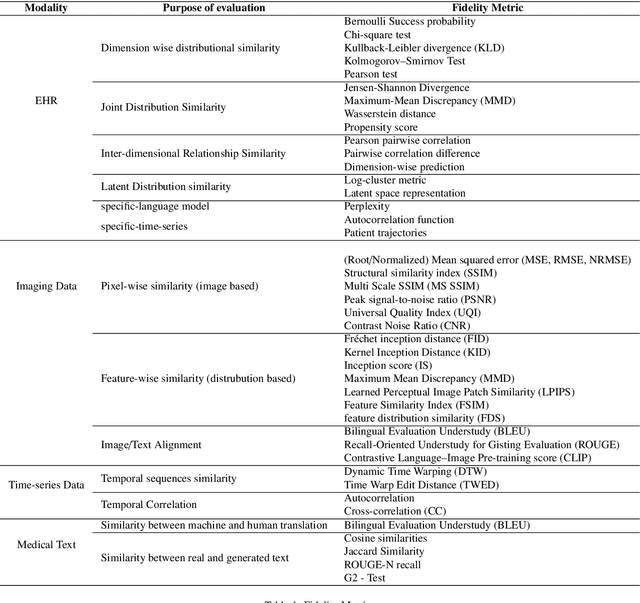

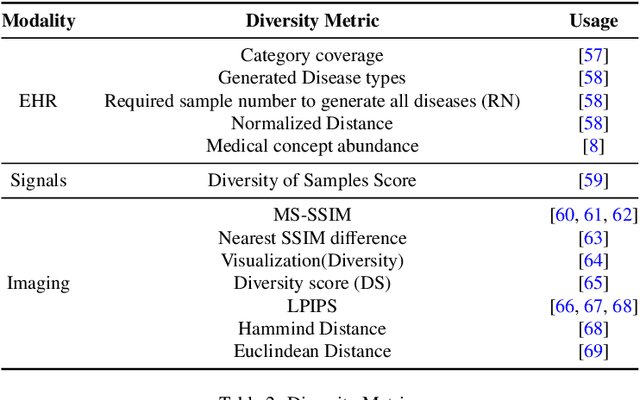
This paper presents a comprehensive systematic review of generative models (GANs, VAEs, DMs, and LLMs) used to synthesize various medical data types, including imaging (dermoscopic, mammographic, ultrasound, CT, MRI, and X-ray), text, time-series, and tabular data (EHR). Unlike previous narrowly focused reviews, our study encompasses a broad array of medical data modalities and explores various generative models. Our search strategy queries databases such as Scopus, PubMed, and ArXiv, focusing on recent works from January 2021 to November 2023, excluding reviews and perspectives. This period emphasizes recent advancements beyond GANs, which have been extensively covered previously. The survey reveals insights from three key aspects: (1) Synthesis applications and purpose of synthesis, (2) generation techniques, and (3) evaluation methods. It highlights clinically valid synthesis applications, demonstrating the potential of synthetic data to tackle diverse clinical requirements. While conditional models incorporating class labels, segmentation masks and image translations are prevalent, there is a gap in utilizing prior clinical knowledge and patient-specific context, suggesting a need for more personalized synthesis approaches and emphasizing the importance of tailoring generative approaches to the unique characteristics of medical data. Additionally, there is a significant gap in using synthetic data beyond augmentation, such as for validation and evaluation of downstream medical AI models. The survey uncovers that the lack of standardized evaluation methodologies tailored to medical images is a barrier to clinical application, underscoring the need for in-depth evaluation approaches, benchmarking, and comparative studies to promote openness and collaboration.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
sim2real: Cardiac MR Image Simulation-to-Real Translation via Unsupervised GANs
Aug 09, 2022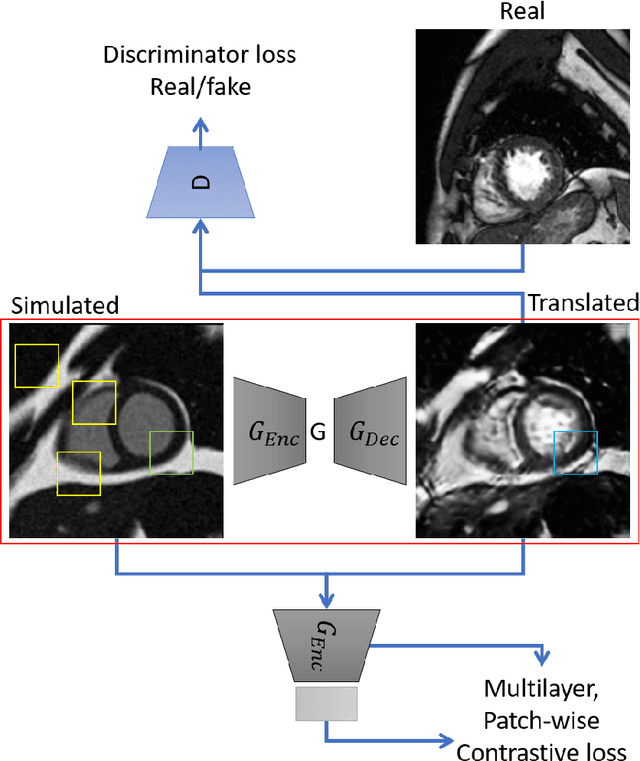
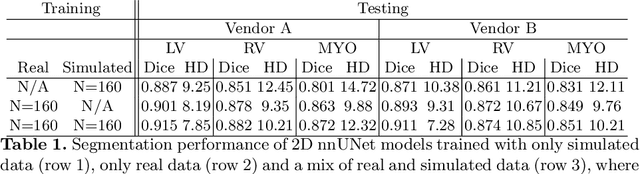
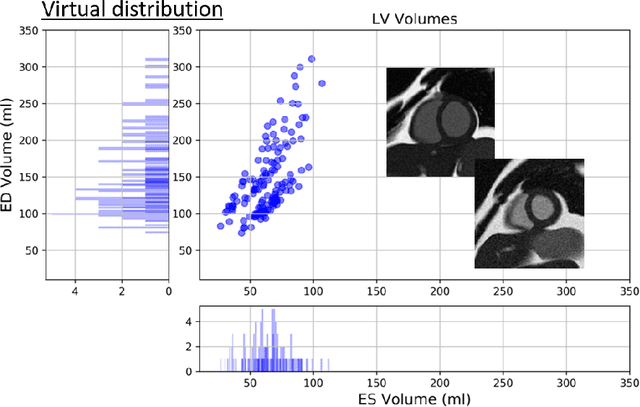
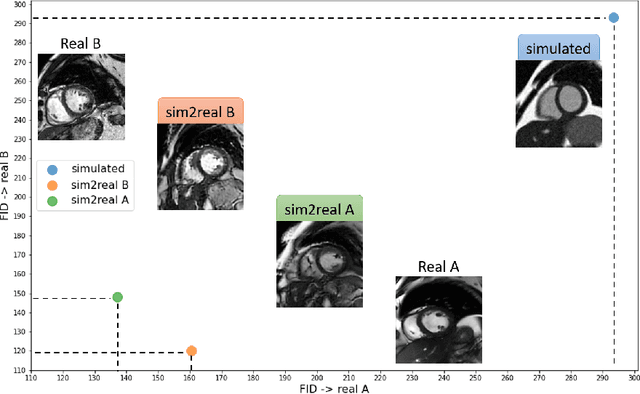
There has been considerable interest in the MR physics-based simulation of a database of virtual cardiac MR images for the development of deep-learning analysis networks. However, the employment of such a database is limited or shows suboptimal performance due to the realism gap, missing textures, and the simplified appearance of simulated images. In this work we 1) provide image simulation on virtual XCAT subjects with varying anatomies, and 2) propose sim2real translation network to improve image realism. Our usability experiments suggest that sim2real data exhibits a good potential to augment training data and boost the performance of a segmentation algorithm.
XCAT-GAN for Synthesizing 3D Consistent Labeled Cardiac MR Images on Anatomically Variable XCAT Phantoms
Jul 31, 2020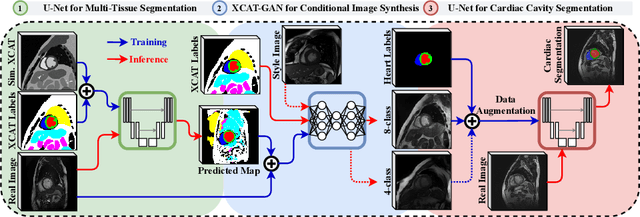
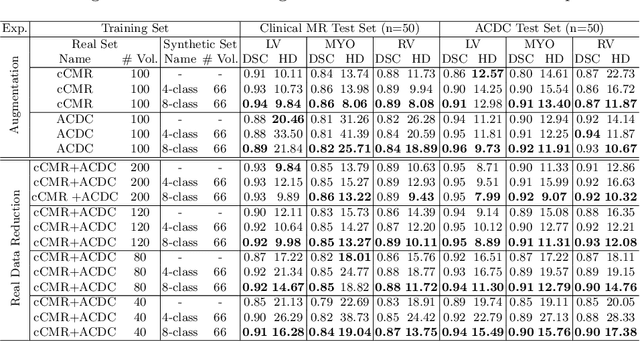
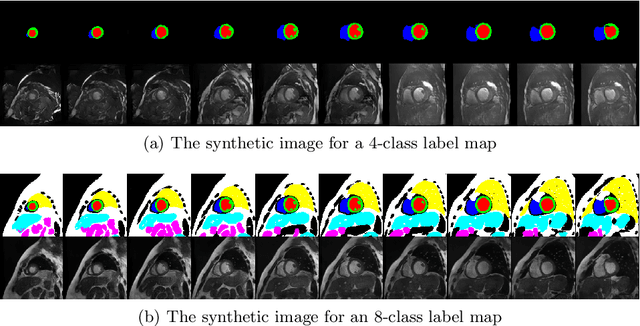
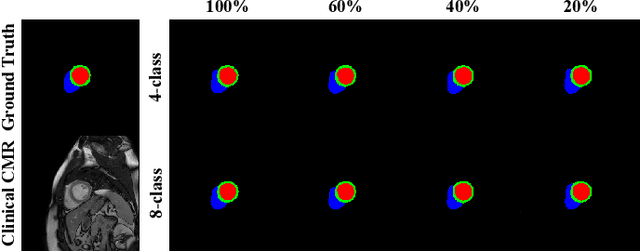
Generative adversarial networks (GANs) have provided promising data enrichment solutions by synthesizing high-fidelity images. However, generating large sets of labeled images with new anatomical variations remains unexplored. We propose a novel method for synthesizing cardiac magnetic resonance (CMR) images on a population of virtual subjects with a large anatomical variation, introduced using the 4D eXtended Cardiac and Torso (XCAT) computerized human phantom. We investigate two conditional image synthesis approaches grounded on a semantically-consistent mask-guided image generation technique: 4-class and 8-class XCAT-GANs. The 4-class technique relies on only the annotations of the heart; while the 8-class technique employs a predicted multi-tissue label map of the heart-surrounding organs and provides better guidance for our conditional image synthesis. For both techniques, we train our conditional XCAT-GAN with real images paired with corresponding labels and subsequently at the inference time, we substitute the labels with the XCAT derived ones. Therefore, the trained network accurately transfers the tissue-specific textures to the new label maps. By creating 33 virtual subjects of synthetic CMR images at the end-diastolic and end-systolic phases, we evaluate the usefulness of such data in the downstream cardiac cavity segmentation task under different augmentation strategies. Results demonstrate that even with only 20% of real images (40 volumes) seen during training, segmentation performance is retained with the addition of synthetic CMR images. Moreover, the improvement in utilizing synthetic images for augmenting the real data is evident through the reduction of Hausdorff distance up to 28% and an increase in the Dice score up to 5%, indicating a higher similarity to the ground truth in all dimensions.