 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up self-supervised learning for improved surgical foundation models
Jan 16, 2025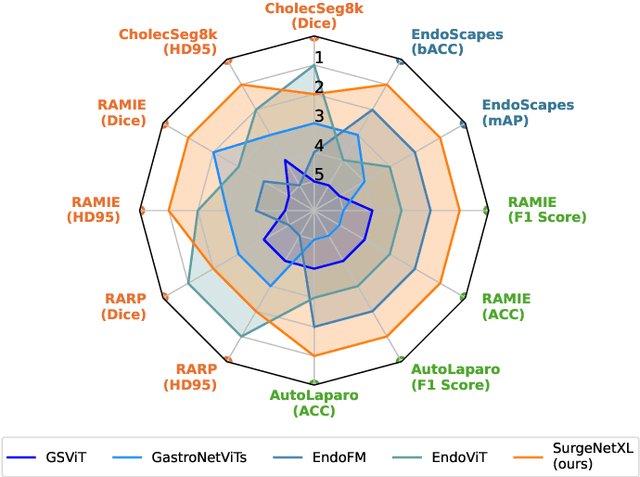
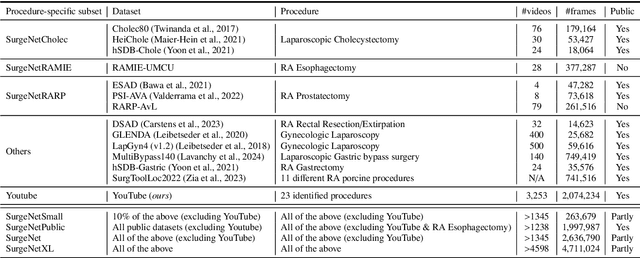
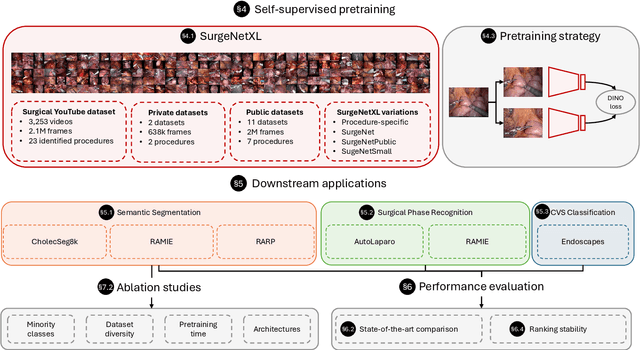
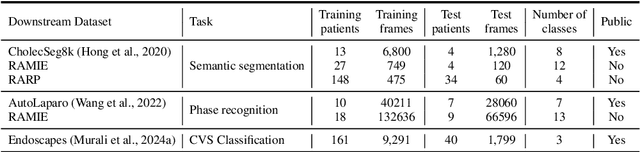
Foundation models have revolutionized computer vision by achieving vastly superior performance across diverse tasks through large-scale pretraining on extensive datasets. However, their application in surgical computer vision has been limited. This study addresses this gap by introducing SurgeNetXL, a novel surgical foundation model that sets a new benchmark in surgical computer vision. Trained on the largest reported surgical dataset to date, comprising over 4.7 million video frames, SurgeNetXL achieves consistent top-tier performance across six datasets spanning four surgical procedures and three tasks, including semantic segmentation, phase recognition, and critical view of safety (CVS) classification. Compared with the best-performing surgical foundation models, SurgeNetXL shows mean improvements of 2.4, 9.0, and 12.6 percent for semantic segmentation, phase recognition, and CVS classification, respectively. Additionally, SurgeNetXL outperforms the best-performing ImageNet-based variants by 14.4, 4.0, and 1.6 percent in the respective tasks. In addition to advancing model performance, this study provides key insights into scaling pretraining datasets, extending training durations, and optimizing model architectures specifically for surgical computer vision. These findings pave the way for improved generalizability and robustness in data-scarce scenarios, offering a comprehensive framework for future research in this domain. All models and a subset of the SurgeNetXL dataset, including over 2 million video frames, are publicly available at: https://github.com/TimJaspers0801/SurgeNet.
Benchmarking Pretrained Attention-based Models for Real-Time Recognition in Robot-Assisted Esophagectomy
Dec 04, 2024Esophageal cancer is among the most common types of cancer worldwide. It is traditionally treated using open esophagectomy, but in recent years, robot-assisted minimally invasive esophagectomy (RAMIE) has emerged as a promising alternative. However, robot-assisted surgery can be challenging for novice surgeons, as they often suffer from a loss of spatial orientation. Computer-aided anatomy recognition holds promise for improving surgical navigation, but research in this area remains limited. In this study, we developed a comprehensive dataset for semantic segmentation in RAMIE, featuring the largest collection of vital anatomical structures and surgical instruments to date. Handling this diverse set of classes presents challenges, including class imbalance and the recognition of complex structures such as nerves. This study aims to understand the challenges and limitations of current state-of-the-art algorithms on this novel dataset and problem. Therefore, we benchmarked eight real-time deep learning models using two pretraining datasets. We assessed both traditional and attention-based networks, hypothesizing that attention-based networks better capture global patterns and address challenges such as occlusion caused by blood or other tissues. The benchmark includes our RAMIE dataset and the publicly available CholecSeg8k dataset, enabling a thorough assessment of surgical segmentation tasks. Our findings indicate that pretraining on ADE20k, a dataset for semantic segmentation, is more effective than pretraining on ImageNet. Furthermore, attention-based models outperform traditional convolutional neural networks, with SegNeXt and Mask2Former achieving higher Dice scores, and Mask2Former additionally excelling in average symmetric surface distance.
Exploring the Effect of Dataset Diversity in Self-Supervised Learning for Surgical Computer Vision
Jul 26, 2024Over the past decade, computer vision applications in minimally invasive surgery have rapidly increased. Despite this growth, the impact of surgical computer vision remains limited compared to other medical fields like pathology and radiology, primarily due to the scarcity of representative annotated data. Whereas transfer learning from large annotated datasets such as ImageNet has been conventionally the norm to achieve high-performing models, recent advancements in self-supervised learning (SSL) have demonstrated superior performance. In medical image analysis, in-domain SSL pretraining has already been shown to outperform ImageNet-based initialization. Although unlabeled data in the field of surgical computer vision is abundant, the diversity within this data is limited. This study investigates the role of dataset diversity in SSL for surgical computer vision, comparing procedure-specific datasets against a more heterogeneous general surgical dataset across three different downstream surgical applications. The obtained results show that using solely procedure-specific data can lead to substantial improvements of 13.8%, 9.5%, and 36.8% compared to ImageNet pretraining. However, extending this data with more heterogeneous surgical data further increases performance by an additional 5.0%, 5.2%, and 2.5%, suggesting that increasing diversity within SSL data is beneficial for model performance. The code and pretrained model weights are made publicly available at https://github.com/TimJaspers0801/SurgeNet.