 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment and evaluation of CADe systems in low-prevalence setting: The RARE25 challenge for early detection of Barrett's neoplasia
Apr 13, 2026Computer-aided detection (CADe) of early neoplasia in Barrett's esophagus is a low-prevalence surveillance problem in which clinically relevant findings are rare. Although many CADe systems report strong performance on balanced or enriched datasets, their behavior under realistic prevalence remains insufficiently characterized. The RARE25 challenge addresses this gap by introducing a large-scale, prevalence-aware benchmark for neoplasia detection. It includes a public training set and a hidden test set reflecting real-world incidence. Methods were evaluated using operating-point-specific metrics emphasizing high sensitivity and accounting for prevalence. Eleven teams from seven countries submitted approaches using diverse architectures, pretraining, ensembling, and calibration strategies. While several methods achieved strong discriminative performance, positive predictive values remained low, highlighting the difficulty of low-prevalence detection and the risk of overestimating clinical utility when prevalence is ignored. All methods relied on fully supervised classification despite the dominance of normal findings, indicating a lack of prevalence-agnostic approaches such as anomaly detection or one-class learning. By releasing a public dataset and a reproducible evaluation framework, RARE25 aims to support the development of CADe systems robust to prevalence shift and suitable for clinical surveillance workflows.
Learning to Recognize Correctly Completed Procedure Steps in Egocentric Assembly Videos through Spatio-Temporal Modeling
Oct 14, 2025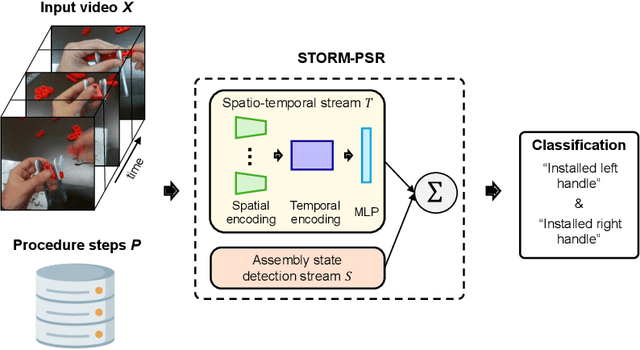
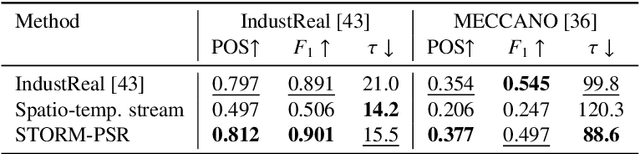
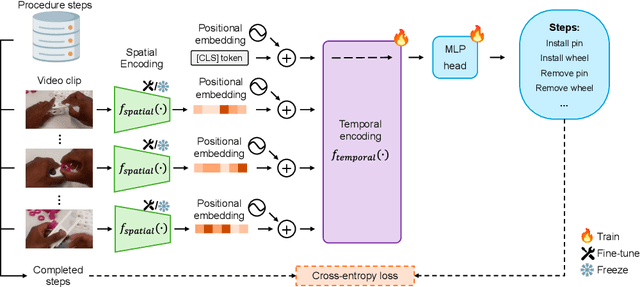
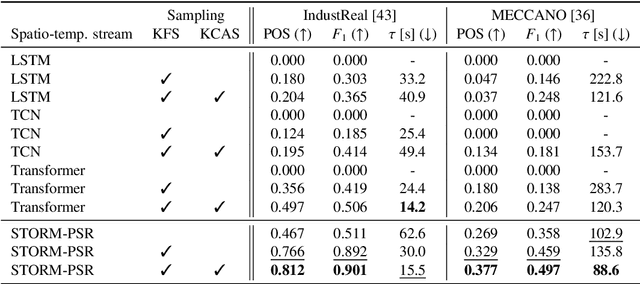
Procedure step recognition (PSR) aims to identify all correctly completed steps and their sequential order in videos of procedural tasks. The existing state-of-the-art models rely solely on detecting assembly object states in individual video frames. By neglecting temporal features, model robustness and accuracy are limited, especially when objects are partially occluded. To overcome these limitations, we propose Spatio-Temporal Occlusion-Resilient Modeling for Procedure Step Recognition (STORM-PSR), a dual-stream framework for PSR that leverages both spatial and temporal features. The assembly state detection stream operates effectively with unobstructed views of the object, while the spatio-temporal stream captures both spatial and temporal features to recognize step completions even under partial occlusion. This stream includes a spatial encoder, pre-trained using a novel weakly supervised approach to capture meaningful spatial representations, and a transformer-based temporal encoder that learns how these spatial features relate over time. STORM-PSR is evaluated on the MECCANO and IndustReal datasets, reducing the average delay between actual and predicted assembly step completions by 11.2% and 26.1%, respectively, compared to prior methods. We demonstrate that this reduction in delay is driven by the spatio-temporal stream, which does not rely on unobstructed views of the object to infer completed steps. The code for STORM-PSR, along with the newly annotated MECCANO labels, is made publicly available at https://timschoonbeek.github.io/stormpsr .
Zero-Shot Image Anomaly Detection Using Generative Foundation Models
Jul 30, 2025Detecting out-of-distribution (OOD) inputs is pivotal for deploying safe vision systems in open-world environments. We revisit diffusion models, not as generators, but as universal perceptual templates for OOD detection. This research explores the use of score-based generative models as foundational tools for semantic anomaly detection across unseen datasets. Specifically, we leverage the denoising trajectories of Denoising Diffusion Models (DDMs) as a rich source of texture and semantic information. By analyzing Stein score errors, amplified through the Structural Similarity Index Metric (SSIM), we introduce a novel method for identifying anomalous samples without requiring re-training on each target dataset. Our approach improves over state-of-the-art and relies on training a single model on one dataset -- CelebA -- which we find to be an effective base distribution, even outperforming more commonly used datasets like ImageNet in several settings. Experimental results show near-perfect performance on some benchmarks, with notable headroom on others, highlighting both the strength and future potential of generative foundation models in anomaly detection.
Symmetrical Flow Matching: Unified Image Generation, Segmentation, and Classification with Score-Based Generative Models
Jun 12, 2025Flow Matching has emerged as a powerful framework for learning continuous transformations between distributions, enabling high-fidelity generative modeling. This work introduces Symmetrical Flow Matching (SymmFlow), a new formulation that unifies semantic segmentation, classification, and image generation within a single model. Using a symmetric learning objective, SymmFlow models forward and reverse transformations jointly, ensuring bi-directional consistency, while preserving sufficient entropy for generative diversity. A new training objective is introduced to explicitly retain semantic information across flows, featuring efficient sampling while preserving semantic structure, allowing for one-step segmentation and classification without iterative refinement. Unlike previous approaches that impose strict one-to-one mapping between masks and images, SymmFlow generalizes to flexible conditioning, supporting both pixel-level and image-level class labels. Experimental results on various benchmarks demonstrate that SymmFlow achieves state-of-the-art performance on semantic image synthesis, obtaining FID scores of 11.9 on CelebAMask-HQ and 7.0 on COCO-Stuff with only 25 inference steps. Additionally, it delivers competitive results on semantic segmentation and shows promising capabilities in classification tasks. The code will be publicly available.
AdverX-Ray: Ensuring X-Ray Integrity Through Frequency-Sensitive Adversarial VAEs
Feb 23, 2025Ensuring the quality and integrity of medical images is crucial for maintaining diagnostic accuracy in deep learning-based Computer-Aided Diagnosis and Computer-Aided Detection (CAD) systems. Covariate shifts are subtle variations in the data distribution caused by different imaging devices or settings and can severely degrade model performance, similar to the effects of adversarial attacks. Therefore, it is vital to have a lightweight and fast method to assess the quality of these images prior to using CAD models. AdverX-Ray addresses this need by serving as an image-quality assessment layer, designed to detect covariate shifts effectively. This Adversarial Variational Autoencoder prioritizes the discriminator's role, using the suboptimal outputs of the generator as negative samples to fine-tune the discriminator's ability to identify high-frequency artifacts. Images generated by adversarial networks often exhibit severe high-frequency artifacts, guiding the discriminator to focus excessively on these components. This makes the discriminator ideal for this approach. Trained on patches from X-ray images of specific machine models, AdverX-Ray can evaluate whether a scan matches the training distribution, or if a scan from the same machine is captured under different settings. Extensive comparisons with various OOD detection methods show that AdverX-Ray significantly outperforms existing techniques, achieving a 96.2% average AUROC using only 64 random patches from an X-ray. Its lightweight and fast architecture makes it suitable for real-time applications, enhancing the reliability of medical imaging systems. The code and pretrained models are publicly available.
Scaling up self-supervised learning for improved surgical foundation models
Jan 16, 2025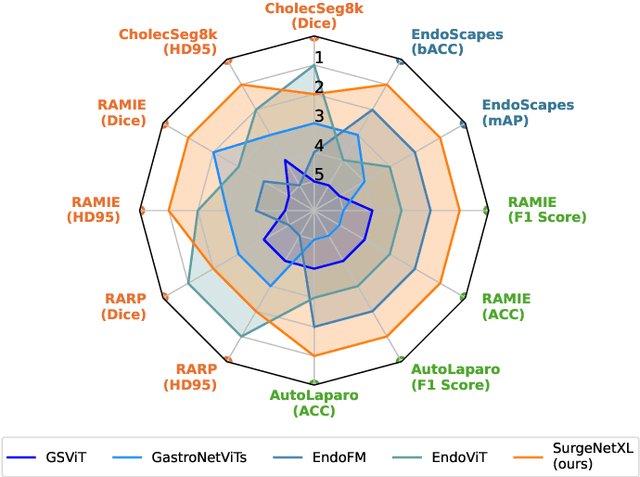
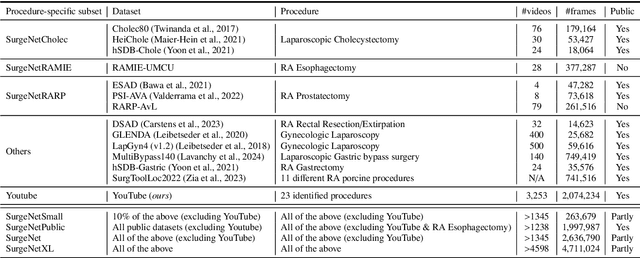
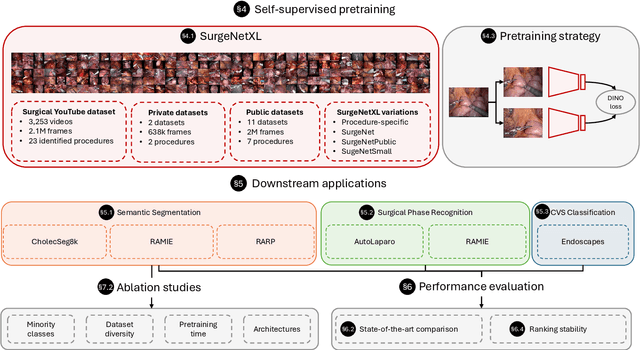
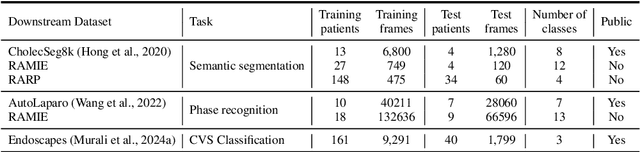
Foundation models have revolutionized computer vision by achieving vastly superior performance across diverse tasks through large-scale pretraining on extensive datasets. However, their application in surgical computer vision has been limited. This study addresses this gap by introducing SurgeNetXL, a novel surgical foundation model that sets a new benchmark in surgical computer vision. Trained on the largest reported surgical dataset to date, comprising over 4.7 million video frames, SurgeNetXL achieves consistent top-tier performance across six datasets spanning four surgical procedures and three tasks, including semantic segmentation, phase recognition, and critical view of safety (CVS) classification. Compared with the best-performing surgical foundation models, SurgeNetXL shows mean improvements of 2.4, 9.0, and 12.6 percent for semantic segmentation, phase recognition, and CVS classification, respectively. Additionally, SurgeNetXL outperforms the best-performing ImageNet-based variants by 14.4, 4.0, and 1.6 percent in the respective tasks. In addition to advancing model performance, this study provides key insights into scaling pretraining datasets, extending training durations, and optimizing model architectures specifically for surgical computer vision. These findings pave the way for improved generalizability and robustness in data-scarce scenarios, offering a comprehensive framework for future research in this domain. All models and a subset of the SurgeNetXL dataset, including over 2 million video frames, are publicly available at: https://github.com/TimJaspers0801/SurgeNet.
DisCoPatch: Batch Statistics Are All You Need For OOD Detection, But Only If You Can Trust Them
Jan 14, 2025



Out-of-distribution (OOD) detection holds significant importance across many applications. While semantic and domain-shift OOD problems are well-studied, this work focuses on covariate shifts - subtle variations in the data distribution that can degrade machine learning performance. We hypothesize that detecting these subtle shifts can improve our understanding of in-distribution boundaries, ultimately improving OOD detection. In adversarial discriminators trained with Batch Normalization (BN), real and adversarial samples form distinct domains with unique batch statistics - a property we exploit for OOD detection. We introduce DisCoPatch, an unsupervised Adversarial Variational Autoencoder (VAE) framework that harnesses this mechanism. During inference, batches consist of patches from the same image, ensuring a consistent data distribution that allows the model to rely on batch statistics. DisCoPatch uses the VAE's suboptimal outputs (generated and reconstructed) as negative samples to train the discriminator, thereby improving its ability to delineate the boundary between in-distribution samples and covariate shifts. By tightening this boundary, DisCoPatch achieves state-of-the-art results in public OOD detection benchmarks. The proposed model not only excels in detecting covariate shifts, achieving 95.5% AUROC on ImageNet-1K(-C) but also outperforms all prior methods on public Near-OOD (95.0%) benchmarks. With a compact model size of 25MB, it achieves high OOD detection performance at notably lower latency than existing methods, making it an efficient and practical solution for real-world OOD detection applications. The code will be made publicly available
Benchmarking Pretrained Attention-based Models for Real-Time Recognition in Robot-Assisted Esophagectomy
Dec 04, 2024Esophageal cancer is among the most common types of cancer worldwide. It is traditionally treated using open esophagectomy, but in recent years, robot-assisted minimally invasive esophagectomy (RAMIE) has emerged as a promising alternative. However, robot-assisted surgery can be challenging for novice surgeons, as they often suffer from a loss of spatial orientation. Computer-aided anatomy recognition holds promise for improving surgical navigation, but research in this area remains limited. In this study, we developed a comprehensive dataset for semantic segmentation in RAMIE, featuring the largest collection of vital anatomical structures and surgical instruments to date. Handling this diverse set of classes presents challenges, including class imbalance and the recognition of complex structures such as nerves. This study aims to understand the challenges and limitations of current state-of-the-art algorithms on this novel dataset and problem. Therefore, we benchmarked eight real-time deep learning models using two pretraining datasets. We assessed both traditional and attention-based networks, hypothesizing that attention-based networks better capture global patterns and address challenges such as occlusion caused by blood or other tissues. The benchmark includes our RAMIE dataset and the publicly available CholecSeg8k dataset, enabling a thorough assessment of surgical segmentation tasks. Our findings indicate that pretraining on ADE20k, a dataset for semantic segmentation, is more effective than pretraining on ImageNet. Furthermore, attention-based models outperform traditional convolutional neural networks, with SegNeXt and Mask2Former achieving higher Dice scores, and Mask2Former additionally excelling in average symmetric surface distance.
Can Your Generative Model Detect Out-of-Distribution Covariate Shift?
Sep 04, 2024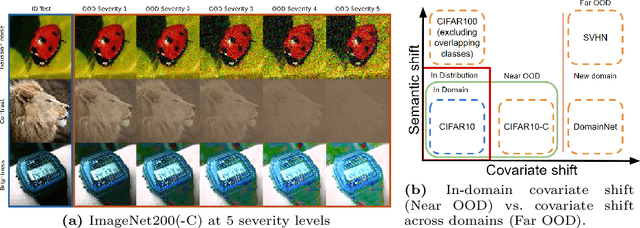



Detecting Out-of-Distribution~(OOD) sensory data and covariate distribution shift aims to identify new test examples with different high-level image statistics to the captured, normal and In-Distribution (ID) set. Existing OOD detection literature largely focuses on semantic shift with little-to-no consensus over covariate shift. Generative models capture the ID data in an unsupervised manner, enabling them to effectively identify samples that deviate significantly from this learned distribution, irrespective of the downstream task. In this work, we elucidate the ability of generative models to detect and quantify domain-specific covariate shift through extensive analyses that involves a variety of models. To this end, we conjecture that it is sufficient to detect most occurring sensory faults (anomalies and deviations in global signals statistics) by solely modeling high-frequency signal-dependent and independent details. We propose a novel method, CovariateFlow, for OOD detection, specifically tailored to covariate heteroscedastic high-frequency image-components using conditional Normalizing Flows (cNFs). Our results on CIFAR10 vs. CIFAR10-C and ImageNet200 vs. ImageNet200-C demonstrate the effectiveness of the method by accurately detecting OOD covariate shift. This work contributes to enhancing the fidelity of imaging systems and aiding machine learning models in OOD detection in the presence of covariate shift.
Find the Assembly Mistakes: Error Segmentation for Industrial Applications
Aug 23, 2024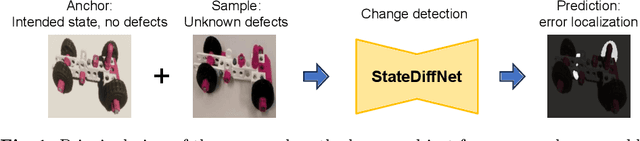
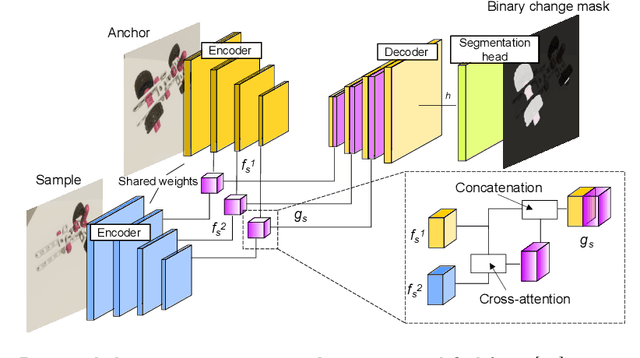
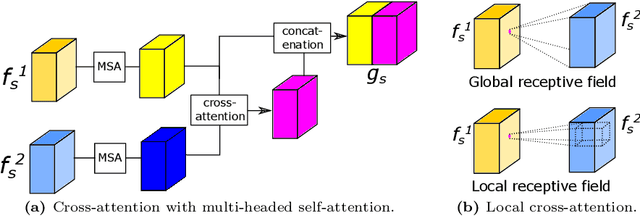
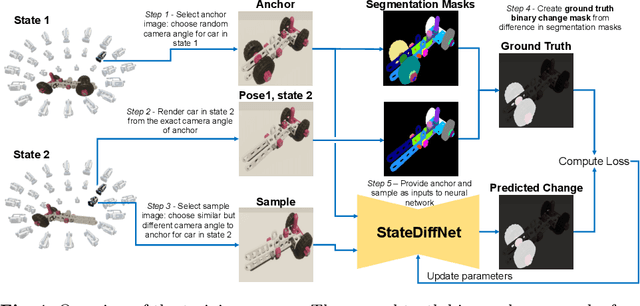
Recognizing errors in assembly and maintenance procedures is valuable for industrial applications, since it can increase worker efficiency and prevent unplanned down-time. Although assembly state recognition is gaining attention, none of the current works investigate assembly error localization. Therefore, we propose StateDiffNet, which localizes assembly errors based on detecting the differences between a (correct) intended assembly state and a test image from a similar viewpoint. StateDiffNet is trained on synthetically generated image pairs, providing full control over the type of meaningful change that should be detected. The proposed approach is the first to correctly localize assembly errors taken from real ego-centric video data for both states and error types that are never presented during training. Furthermore, the deployment of change detection to this industrial application provides valuable insights and considerations into the mechanisms of state-of-the-art change detection algorithms. The code and data generation pipeline are publicly available at: https://timschoonbeek.github.io/error_seg.