 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Recognize Correctly Completed Procedure Steps in Egocentric Assembly Videos through Spatio-Temporal Modeling
Oct 14, 2025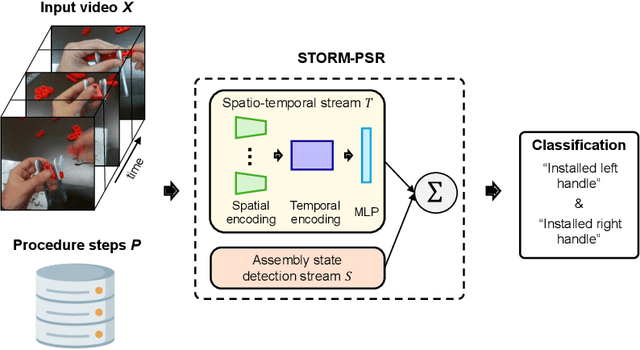
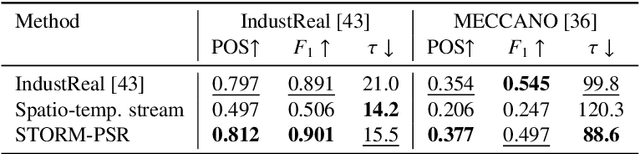
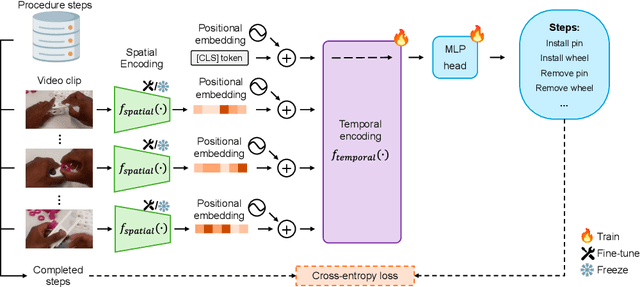
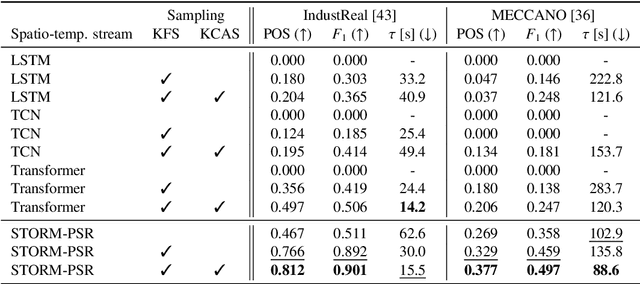
Procedure step recognition (PSR) aims to identify all correctly completed steps and their sequential order in videos of procedural tasks. The existing state-of-the-art models rely solely on detecting assembly object states in individual video frames. By neglecting temporal features, model robustness and accuracy are limited, especially when objects are partially occluded. To overcome these limitations, we propose Spatio-Temporal Occlusion-Resilient Modeling for Procedure Step Recognition (STORM-PSR), a dual-stream framework for PSR that leverages both spatial and temporal features. The assembly state detection stream operates effectively with unobstructed views of the object, while the spatio-temporal stream captures both spatial and temporal features to recognize step completions even under partial occlusion. This stream includes a spatial encoder, pre-trained using a novel weakly supervised approach to capture meaningful spatial representations, and a transformer-based temporal encoder that learns how these spatial features relate over time. STORM-PSR is evaluated on the MECCANO and IndustReal datasets, reducing the average delay between actual and predicted assembly step completions by 11.2% and 26.1%, respectively, compared to prior methods. We demonstrate that this reduction in delay is driven by the spatio-temporal stream, which does not rely on unobstructed views of the object to infer completed steps. The code for STORM-PSR, along with the newly annotated MECCANO labels, is made publicly available at https://timschoonbeek.github.io/stormpsr .
AdverX-Ray: Ensuring X-Ray Integrity Through Frequency-Sensitive Adversarial VAEs
Feb 23, 2025Ensuring the quality and integrity of medical images is crucial for maintaining diagnostic accuracy in deep learning-based Computer-Aided Diagnosis and Computer-Aided Detection (CAD) systems. Covariate shifts are subtle variations in the data distribution caused by different imaging devices or settings and can severely degrade model performance, similar to the effects of adversarial attacks. Therefore, it is vital to have a lightweight and fast method to assess the quality of these images prior to using CAD models. AdverX-Ray addresses this need by serving as an image-quality assessment layer, designed to detect covariate shifts effectively. This Adversarial Variational Autoencoder prioritizes the discriminator's role, using the suboptimal outputs of the generator as negative samples to fine-tune the discriminator's ability to identify high-frequency artifacts. Images generated by adversarial networks often exhibit severe high-frequency artifacts, guiding the discriminator to focus excessively on these components. This makes the discriminator ideal for this approach. Trained on patches from X-ray images of specific machine models, AdverX-Ray can evaluate whether a scan matches the training distribution, or if a scan from the same machine is captured under different settings. Extensive comparisons with various OOD detection methods show that AdverX-Ray significantly outperforms existing techniques, achieving a 96.2% average AUROC using only 64 random patches from an X-ray. Its lightweight and fast architecture makes it suitable for real-time applications, enhancing the reliability of medical imaging systems. The code and pretrained models are publicly available.
Scaling up self-supervised learning for improved surgical foundation models
Jan 16, 2025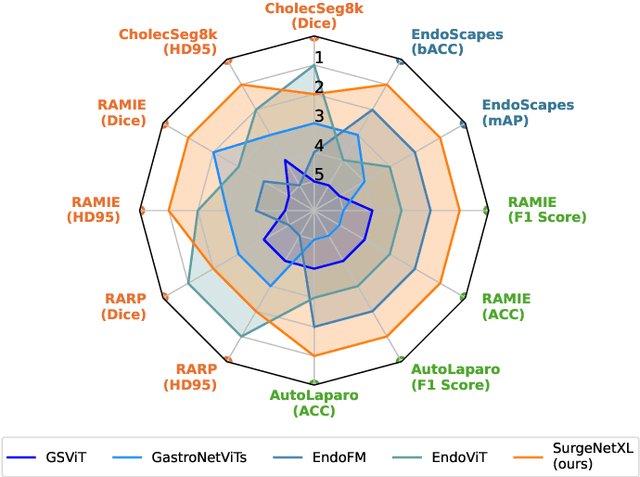
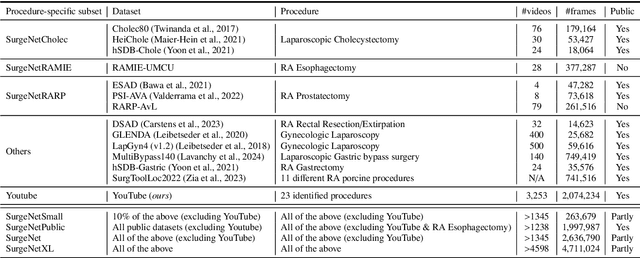
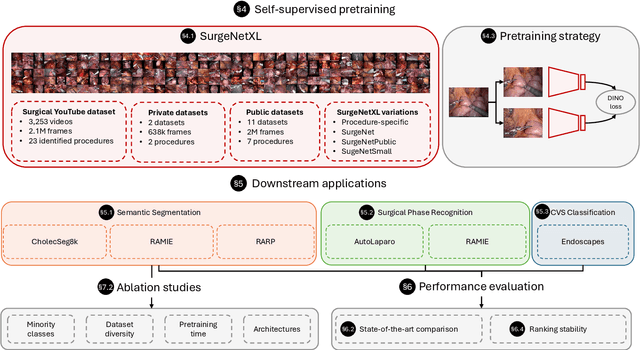
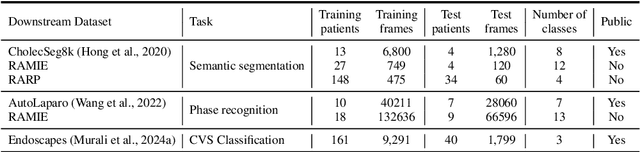
Foundation models have revolutionized computer vision by achieving vastly superior performance across diverse tasks through large-scale pretraining on extensive datasets. However, their application in surgical computer vision has been limited. This study addresses this gap by introducing SurgeNetXL, a novel surgical foundation model that sets a new benchmark in surgical computer vision. Trained on the largest reported surgical dataset to date, comprising over 4.7 million video frames, SurgeNetXL achieves consistent top-tier performance across six datasets spanning four surgical procedures and three tasks, including semantic segmentation, phase recognition, and critical view of safety (CVS) classification. Compared with the best-performing surgical foundation models, SurgeNetXL shows mean improvements of 2.4, 9.0, and 12.6 percent for semantic segmentation, phase recognition, and CVS classification, respectively. Additionally, SurgeNetXL outperforms the best-performing ImageNet-based variants by 14.4, 4.0, and 1.6 percent in the respective tasks. In addition to advancing model performance, this study provides key insights into scaling pretraining datasets, extending training durations, and optimizing model architectures specifically for surgical computer vision. These findings pave the way for improved generalizability and robustness in data-scarce scenarios, offering a comprehensive framework for future research in this domain. All models and a subset of the SurgeNetXL dataset, including over 2 million video frames, are publicly available at: https://github.com/TimJaspers0801/SurgeNet.
DisCoPatch: Batch Statistics Are All You Need For OOD Detection, But Only If You Can Trust Them
Jan 14, 2025



Out-of-distribution (OOD) detection holds significant importance across many applications. While semantic and domain-shift OOD problems are well-studied, this work focuses on covariate shifts - subtle variations in the data distribution that can degrade machine learning performance. We hypothesize that detecting these subtle shifts can improve our understanding of in-distribution boundaries, ultimately improving OOD detection. In adversarial discriminators trained with Batch Normalization (BN), real and adversarial samples form distinct domains with unique batch statistics - a property we exploit for OOD detection. We introduce DisCoPatch, an unsupervised Adversarial Variational Autoencoder (VAE) framework that harnesses this mechanism. During inference, batches consist of patches from the same image, ensuring a consistent data distribution that allows the model to rely on batch statistics. DisCoPatch uses the VAE's suboptimal outputs (generated and reconstructed) as negative samples to train the discriminator, thereby improving its ability to delineate the boundary between in-distribution samples and covariate shifts. By tightening this boundary, DisCoPatch achieves state-of-the-art results in public OOD detection benchmarks. The proposed model not only excels in detecting covariate shifts, achieving 95.5% AUROC on ImageNet-1K(-C) but also outperforms all prior methods on public Near-OOD (95.0%) benchmarks. With a compact model size of 25MB, it achieves high OOD detection performance at notably lower latency than existing methods, making it an efficient and practical solution for real-world OOD detection applications. The code will be made publicly available
Find the Assembly Mistakes: Error Segmentation for Industrial Applications
Aug 23, 2024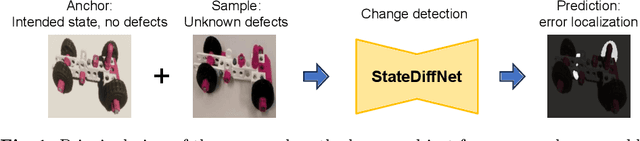
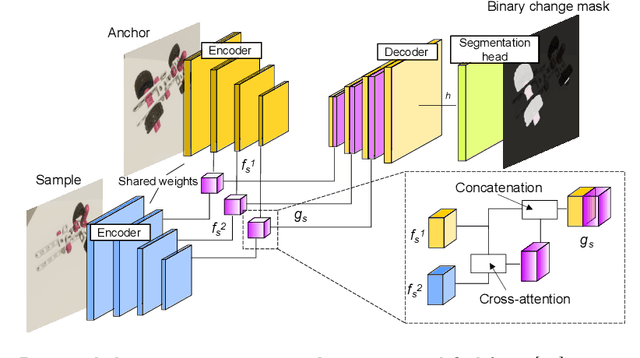
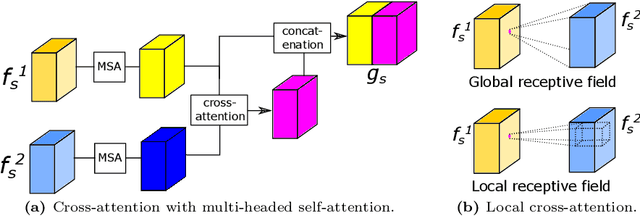
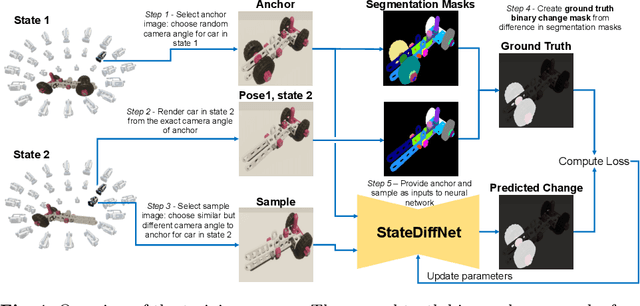
Recognizing errors in assembly and maintenance procedures is valuable for industrial applications, since it can increase worker efficiency and prevent unplanned down-time. Although assembly state recognition is gaining attention, none of the current works investigate assembly error localization. Therefore, we propose StateDiffNet, which localizes assembly errors based on detecting the differences between a (correct) intended assembly state and a test image from a similar viewpoint. StateDiffNet is trained on synthetically generated image pairs, providing full control over the type of meaningful change that should be detected. The proposed approach is the first to correctly localize assembly errors taken from real ego-centric video data for both states and error types that are never presented during training. Furthermore, the deployment of change detection to this industrial application provides valuable insights and considerations into the mechanisms of state-of-the-art change detection algorithms. The code and data generation pipeline are publicly available at: https://timschoonbeek.github.io/error_seg.
Supervised Representation Learning towards Generalizable Assembly State Recognition
Aug 21, 2024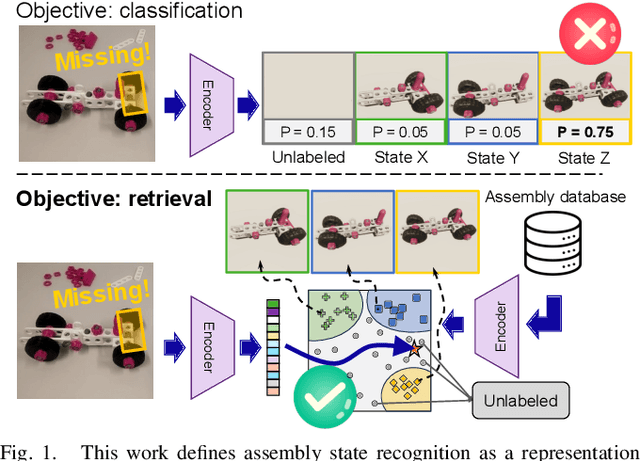
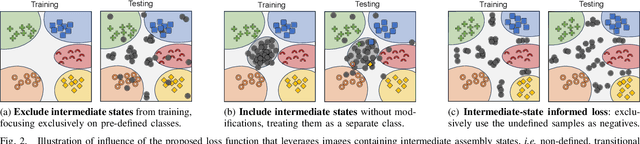
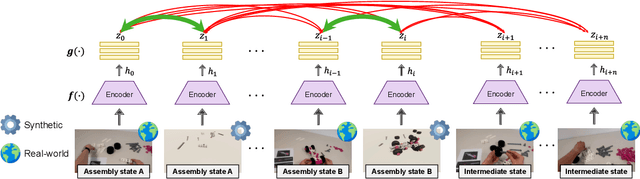
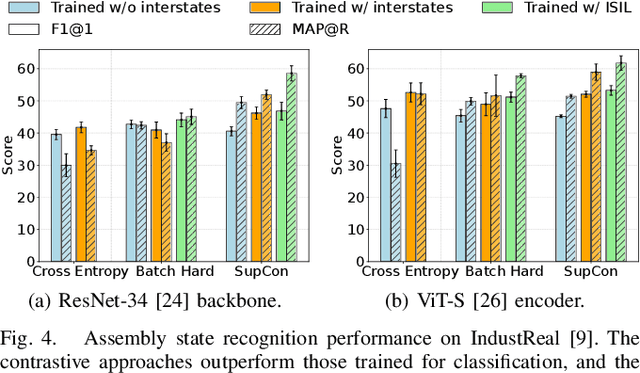
Assembly state recognition facilitates the execution of assembly procedures, offering feedback to enhance efficiency and minimize errors. However, recognizing assembly states poses challenges in scalability, since parts are frequently updated, and the robustness to execution errors remains underexplored. To address these challenges, this paper proposes an approach based on representation learning and the novel intermediate-state informed loss function modification (ISIL). ISIL leverages unlabeled transitions between states and demonstrates significant improvements in clustering and classification performance for all tested architectures and losses. Despite being trained exclusively on images without execution errors, thorough analysis on error states demonstrates that our approach accurately distinguishes between correct states and states with various types of execution errors. The integration of the proposed algorithm can offer meaningful assistance to workers and mitigate unexpected losses due to procedural mishaps in industrial settings. The code is available at: https://timschoonbeek.github.io/state_rec
Advancing 6-DoF Instrument Pose Estimation in Variable X-Ray Imaging Geometries
May 19, 2024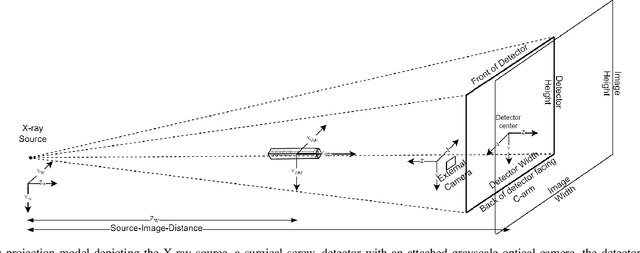

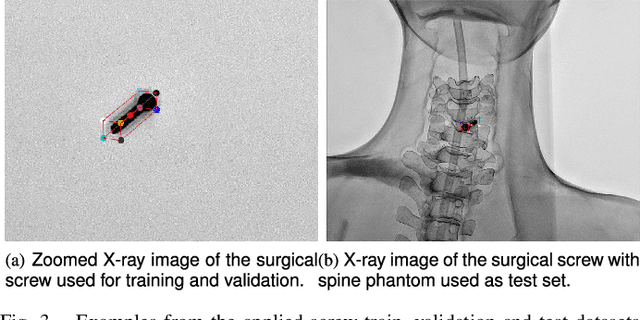
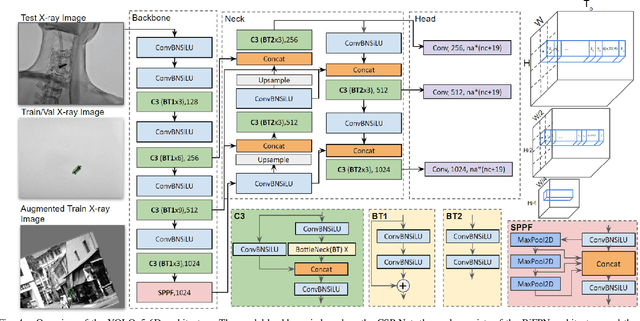
Accurate 6-DoF pose estimation of surgical instruments during minimally invasive surgeries can substantially improve treatment strategies and eventual surgical outcome. Existing deep learning methods have achieved accurate results, but they require custom approaches for each object and laborious setup and training environments often stretching to extensive simulations, whilst lacking real-time computation. We propose a general-purpose approach of data acquisition for 6-DoF pose estimation tasks in X-ray systems, a novel and general purpose YOLOv5-6D pose architecture for accurate and fast object pose estimation and a complete method for surgical screw pose estimation under acquisition geometry consideration from a monocular cone-beam X-ray image. The proposed YOLOv5-6D pose model achieves competitive results on public benchmarks whilst being considerably faster at 42 FPS on GPU. In addition, the method generalizes across varying X-ray acquisition geometry and semantic image complexity to enable accurate pose estimation over different domains. Finally, the proposed approach is tested for bone-screw pose estimation for computer-aided guidance during spine surgeries. The model achieves a 92.41% by the 0.1 ADD-S metric, demonstrating a promising approach for enhancing surgical precision and patient outcomes. The code for YOLOv5-6D is publicly available at https://github.com/cviviers/YOLOv5-6D-Pose
* Early author version of paper. Refer to the full paper at https://ieeexplore.ieee.org/document/10478293
uTRAND: Unsupervised Anomaly Detection in Traffic Trajectories
Apr 19, 2024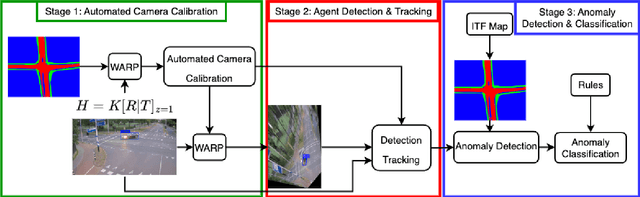


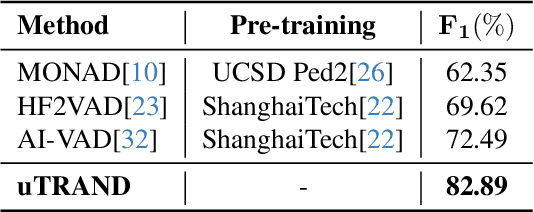
Deep learning-based approaches have achieved significant improvements on public video anomaly datasets, but often do not perform well in real-world applications. This paper addresses two issues: the lack of labeled data and the difficulty of explaining the predictions of a neural network. To this end, we present a framework called uTRAND, that shifts the problem of anomalous trajectory prediction from the pixel space to a semantic-topological domain. The framework detects and tracks all types of traffic agents in bird's-eye-view videos of traffic cameras mounted at an intersection. By conceptualizing the intersection as a patch-based graph, it is shown that the framework learns and models the normal behaviour of traffic agents without costly manual labeling. Furthermore, uTRAND allows to formulate simple rules to classify anomalous trajectories in a way suited for human interpretation. We show that uTRAND outperforms other state-of-the-art approaches on a dataset of anomalous trajectories collected in a real-world setting, while producing explainable detection results.
IndustReal: A Dataset for Procedure Step Recognition Handling Execution Errors in Egocentric Videos in an Industrial-Like Setting
Oct 26, 2023Although action recognition for procedural tasks has received notable attention, it has a fundamental flaw in that no measure of success for actions is provided. This limits the applicability of such systems especially within the industrial domain, since the outcome of procedural actions is often significantly more important than the mere execution. To address this limitation, we define the novel task of procedure step recognition (PSR), focusing on recognizing the correct completion and order of procedural steps. Alongside the new task, we also present the multi-modal IndustReal dataset. Unlike currently available datasets, IndustReal contains procedural errors (such as omissions) as well as execution errors. A significant part of these errors are exclusively present in the validation and test sets, making IndustReal suitable to evaluate robustness of algorithms to new, unseen mistakes. Additionally, to encourage reproducibility and allow for scalable approaches trained on synthetic data, the 3D models of all parts are publicly available. Annotations and benchmark performance are provided for action recognition and assembly state detection, as well as the new PSR task. IndustReal, along with the code and model weights, is available at: https://github.com/TimSchoonbeek/IndustReal .
Investigating and Improving Latent Density Segmentation Models for Aleatoric Uncertainty Quantification in Medical Imaging
Aug 15, 2023


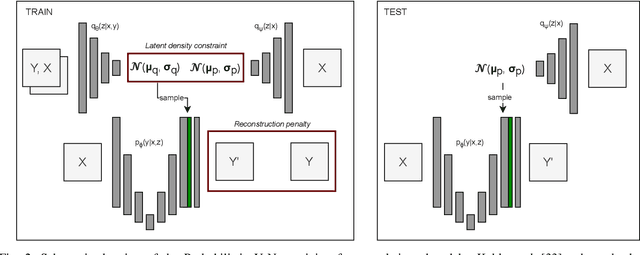
Data uncertainties, such as sensor noise or occlusions, can introduce irreducible ambiguities in images, which result in varying, yet plausible, semantic hypotheses. In Machine Learning, this ambiguity is commonly referred to as aleatoric uncertainty. Latent density models can be utilized to address this problem in image segmentation. The most popular approach is the Probabilistic U-Net (PU-Net), which uses latent Normal densities to optimize the conditional data log-likelihood Evidence Lower Bound. In this work, we demonstrate that the PU- Net latent space is severely inhomogenous. As a result, the effectiveness of gradient descent is inhibited and the model becomes extremely sensitive to the localization of the latent space samples, resulting in defective predictions. To address this, we present the Sinkhorn PU-Net (SPU-Net), which uses the Sinkhorn Divergence to promote homogeneity across all latent dimensions, effectively improving gradient-descent updates and model robustness. Our results show that by applying this on public datasets of various clinical segmentation problems, the SPU-Net receives up to 11% performance gains compared against preceding latent variable models for probabilistic segmentation on the Hungarian-Matched metric. The results indicate that by encouraging a homogeneous latent space, one can significantly improve latent density modeling for medical image segmentation.