 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA RAG Approach for Generating Competency Questions in Ontology Engineering
Sep 13, 2024



Competency question (CQ) formulation is central to several ontology development and evaluation methodologies. Traditionally, the task of crafting these competency questions heavily relies on the effort of domain experts and knowledge engineers which is often time-consuming and labor-intensive. With the emergence of Large Language Models (LLMs), there arises the possibility to automate and enhance this process. Unlike other similar works which use existing ontologies or knowledge graphs as input to LLMs, we present a retrieval-augmented generation (RAG) approach that uses LLMs for the automatic generation of CQs given a set of scientific papers considered to be a domain knowledge base. We investigate its performance and specifically, we study the impact of different number of papers to the RAG and different temperature setting of the LLM. We conduct experiments using GPT-4 on two domain ontology engineering tasks and compare results against ground-truth CQs constructed by domain experts. Empirical assessments on the results, utilizing evaluation metrics (precision and consistency), reveal that compared to zero-shot prompting, adding relevant domain knowledge to the RAG improves the performance of LLMs on generating CQs for concrete ontology engineering tasks.
On the challenges of studying bias in Recommender Systems: A UserKNN case study
Sep 12, 2024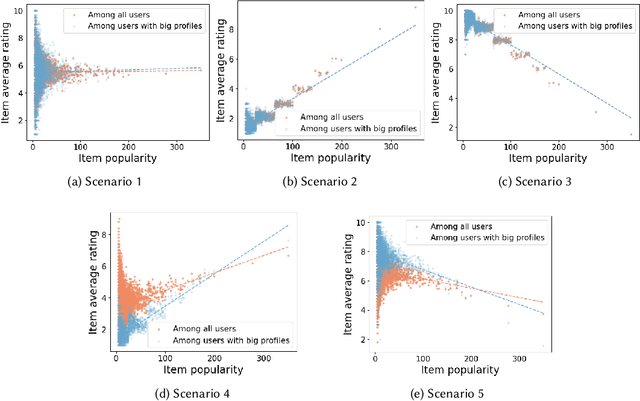

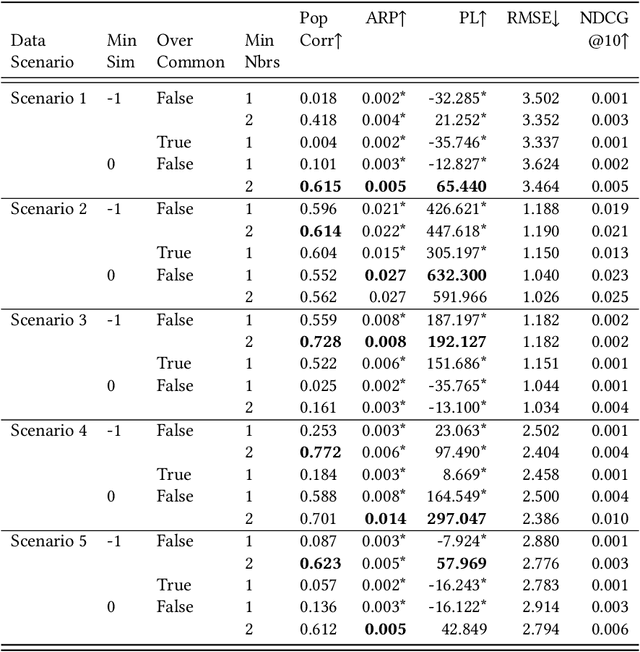
Statements on the propagation of bias by recommender systems are often hard to verify or falsify. Research on bias tends to draw from a small pool of publicly available datasets and is therefore bound by their specific properties. Additionally, implementation choices are often not explicitly described or motivated in research, while they may have an effect on bias propagation. In this paper, we explore the challenges of measuring and reporting popularity bias. We showcase the impact of data properties and algorithm configurations on popularity bias by combining synthetic data with well known recommender systems frameworks that implement UserKNN. First, we identify data characteristics that might impact popularity bias, based on the functionality of UserKNN. Accordingly, we generate various datasets that combine these characteristics. Second, we locate UserKNN configurations that vary across implementations in literature. We evaluate popularity bias for five synthetic datasets and five UserKNN configurations, and offer insights on their joint effect. We find that, depending on the data characteristics, various UserKNN configurations can lead to different conclusions regarding the propagation of popularity bias. These results motivate the need for explicitly addressing algorithmic configuration and data properties when reporting and interpreting bias in recommender systems.
Text classification of column headers with a controlled vocabulary: leveraging LLMs for metadata enrichment
Mar 05, 2024Traditional dataset retrieval systems index on metadata information rather than on the data values. Thus relying primarily on manual annotations and high-quality metadata, processes known to be labour-intensive and challenging to automate. We propose a method to support metadata enrichment with topic annotations of column headers using three Large Language Models (LLMs): ChatGPT-3.5, GoogleBard and GoogleGemini. We investigate the LLMs ability to classify column headers based on domain-specific topics from a controlled vocabulary. We evaluate our approach by assessing the internal consistency of the LLMs, the inter-machine alignment, and the human-machine agreement for the topic classification task. Additionally, we investigate the impact of contextual information (i.e. dataset description) on the classification outcomes. Our results suggest that ChatGPT and GoogleGemini outperform GoogleBard for internal consistency as well as LLM-human-alignment. Interestingly, we found that context had no impact on the LLMs performances. This work proposes a novel approach that leverages LLMs for text classification using a controlled topic vocabulary, which has the potential to facilitate automated metadata enrichment, thereby enhancing dataset retrieval and the Findability, Accessibility, Interoperability and Reusability (FAIR) of research data on the Web.
How Contentious Terms About People and Cultures are Used in Linked Open Data
Nov 13, 2023Web resources in linked open data (LOD) are comprehensible to humans through literal textual values attached to them, such as labels, notes, or comments. Word choices in literals may not always be neutral. When outdated and culturally stereotyping terminology is used in literals, they may appear as offensive to users in interfaces and propagate stereotypes to algorithms trained on them. We study how frequently and in which literals contentious terms about people and cultures occur in LOD and whether there are attempts to mark the usage of such terms. For our analysis, we reuse English and Dutch terms from a knowledge graph that provides opinions of experts from the cultural heritage domain about terms' contentiousness. We inspect occurrences of these terms in four widely used datasets: Wikidata, The Getty Art & Architecture Thesaurus, Princeton WordNet, and Open Dutch WordNet. Some terms are ambiguous and contentious only in particular senses. Applying word sense disambiguation, we generate a set of literals relevant to our analysis. We found that outdated, derogatory, stereotyping terms frequently appear in descriptive and labelling literals, such as preferred labels that are usually displayed in interfaces and used for indexing. In some cases, LOD contributors mark contentious terms with words and phrases in literals (implicit markers) or properties linked to resources (explicit markers). However, such marking is rare and non-consistent in all datasets. Our quantitative and qualitative insights could be helpful in developing more systematic approaches to address the propagation of stereotypes via LOD.
Nanopublication-Based Semantic Publishing and Reviewing: A Field Study with Formalization Papers
Mar 03, 2022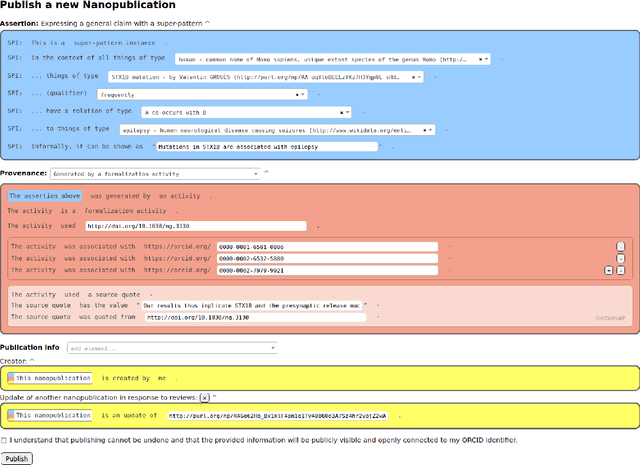
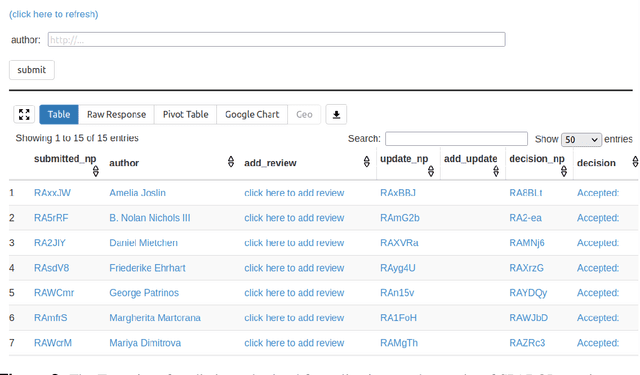
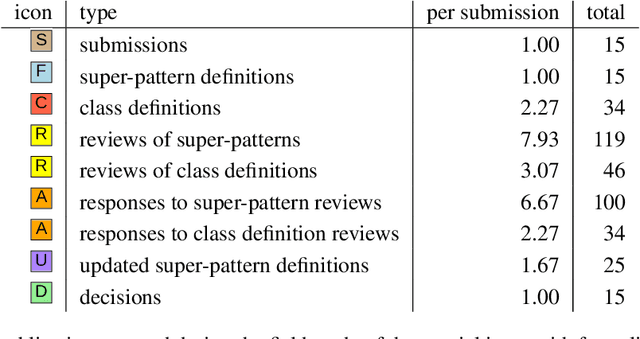
With the rapidly increasing amount of scientific literature,it is getting continuously more difficult for researchers in different disciplines to be updated with the recent findings in their field of study.Processing scientific articles in an automated fashion has been proposed as a solution to this problem,but the accuracy of such processing remains very poor for extraction tasks beyond the basic ones.Few approaches have tried to change how we publish scientific results in the first place,by making articles machine-interpretable by expressing them with formal semantics from the start.In the work presented here,we set out to demonstrate that we can formally publish high-level scientific claims in formal logic,and publish the results in a special issue of an existing journal.We use the concept and technology of nanopublications for this endeavor,and represent not just the submissions and final papers in this RDF-based format,but also the whole process in between,including reviews,responses,and decisions.We do this by performing a field study with what we call formalization papers,which contribute a novel formalization of a previously published claim.We received 15 submissions from 18 authors,who then went through the whole publication process leading to the publication of their contributions in the special issue.Our evaluation shows the technical and practical feasibility of our approach.The participating authors mostly showed high levels of interest and confidence,and mostly experienced the process as not very difficult,despite the technical nature of the current user interfaces.We believe that these results indicate that it is possible to publish scientific results from different fields with machine-interpretable semantics from the start,which in turn opens countless possibilities to radically improve in the future the effectiveness and efficiency of the scientific endeavor as a whole.
Expressing High-Level Scientific Claims with Formal Semantics
Sep 27, 2021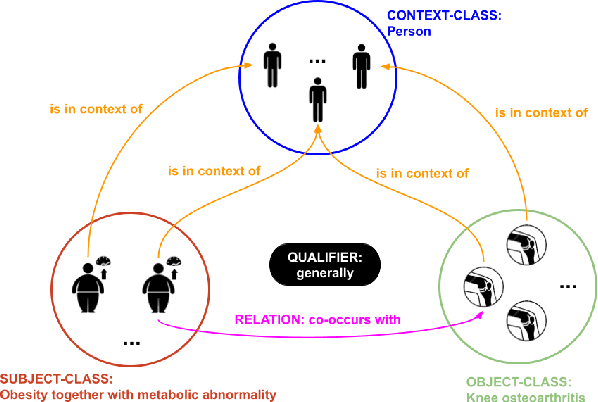
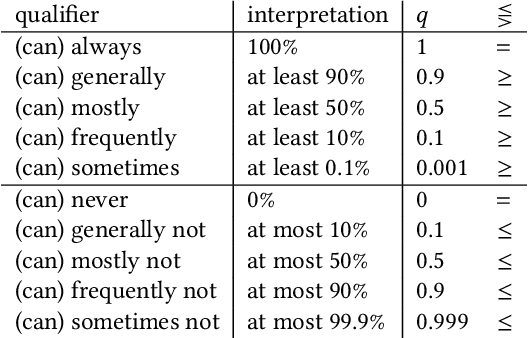
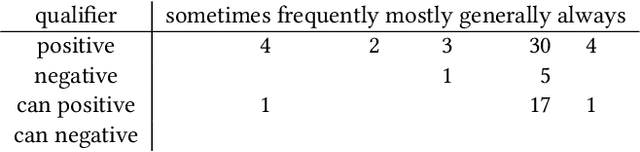
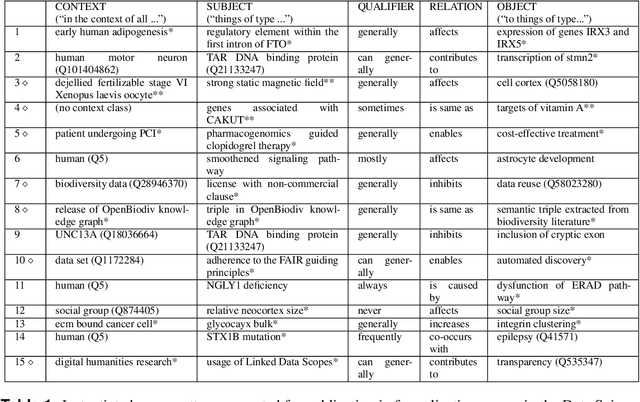
The use of semantic technologies is gaining significant traction in science communication with a wide array of applications in disciplines including the Life Sciences, Computer Science, and the Social Sciences. Languages like RDF, OWL, and other formalisms based on formal logic are applied to make scientific knowledge accessible not only to human readers but also to automated systems. These approaches have mostly focused on the structure of scientific publications themselves, on the used scientific methods and equipment, or on the structure of the used datasets. The core claims or hypotheses of scientific work have only been covered in a shallow manner, such as by linking mentioned entities to established identifiers. In this research, we therefore want to find out whether we can use existing semantic formalisms to fully express the content of high-level scientific claims using formal semantics in a systematic way. Analyzing the main claims from a sample of scientific articles from all disciplines, we find that their semantics are more complex than what a straight-forward application of formalisms like RDF or OWL account for, but we managed to elicit a clear semantic pattern which we call the 'super-pattern'. We show here how the instantiation of the five slots of this super-pattern leads to a strictly defined statement in higher-order logic. We successfully applied this super-pattern to an enlarged sample of scientific claims. We show that knowledge representation experts, when instructed to independently instantiate the super-pattern with given scientific claims, show a high degree of consistency and convergence given the complexity of the task and the subject. These results therefore open the door for expressing high-level scientific findings in a manner they can be automatically interpreted, which on the longer run can allow us to do automated consistency checking, and much more.
Is it a Fruit, an Apple or a Granny Smith? Predicting the Basic Level in a Concept Hierarchy
Oct 25, 2019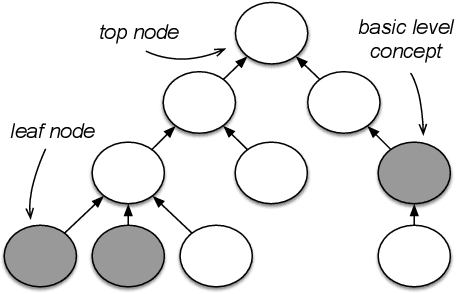
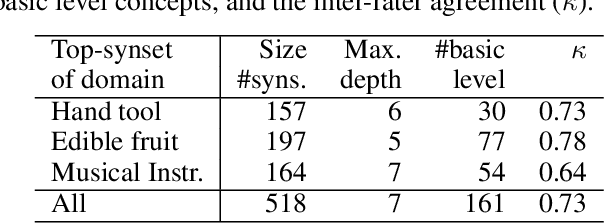
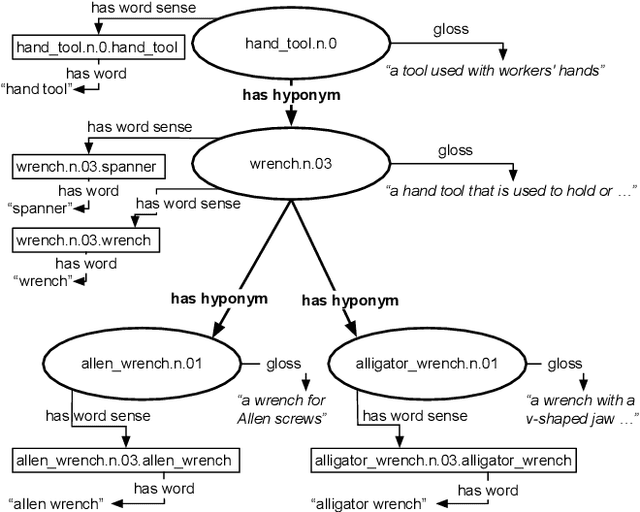
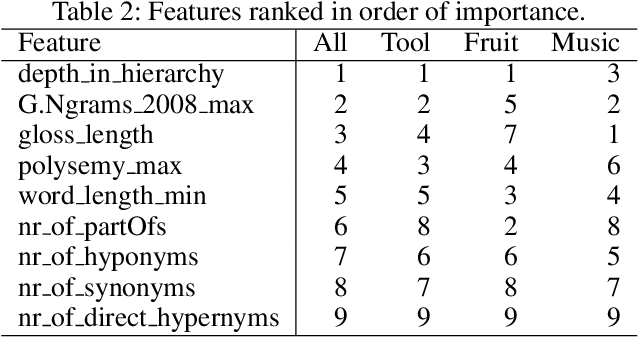
The "basic level", according to experiments in cognitive psychology, is the level of abstraction in a hierarchy of concepts at which humans perform tasks quicker and with greater accuracy than at other levels. We argue that applications that use concept hierarchies - such as knowledge graphs, ontologies or taxonomies - could significantly improve their user interfaces if they `knew' which concepts are the basic level concepts. This paper examines to what extent the basic level can be learned from data. We test the utility of three types of concept features, that were inspired by the basic level theory: lexical features, structural features and frequency features. We evaluate our approach on WordNet, and create a training set of manually labelled examples that includes concepts from different domains. Our findings include that the basic level concepts can be accurately identified within one domain. Concepts that are difficult to label for humans are also harder to classify automatically. Our experiments provide insight into how classification performance across domains could be improved, which is necessary for identification of basic level concepts on a larger scale.
Utilizing a Transparency-driven Environment toward Trusted Automatic Genre Classification: A Case Study in Journalism History
Oct 01, 2018
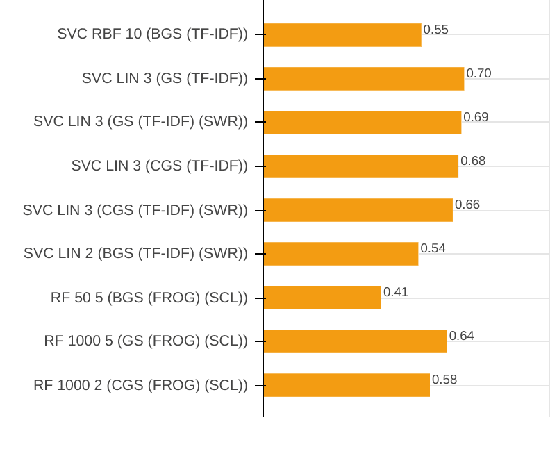
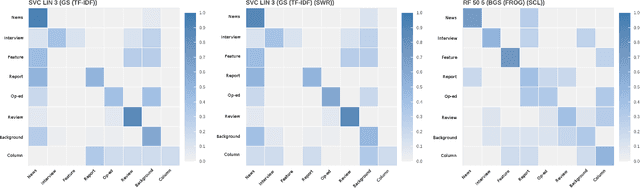
With the growing abundance of unlabeled data in real-world tasks, researchers have to rely on the predictions given by black-boxed computational models. However, it is an often neglected fact that these models may be scoring high on accuracy for the wrong reasons. In this paper, we present a practical impact analysis of enabling model transparency by various presentation forms. For this purpose, we developed an environment that empowers non-computer scientists to become practicing data scientists in their own research field. We demonstrate the gradually increasing understanding of journalism historians through a real-world use case study on automatic genre classification of newspaper articles. This study is a first step towards trusted usage of machine learning pipelines in a responsible way.