 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA RAG Approach for Generating Competency Questions in Ontology Engineering
Sep 13, 2024



Competency question (CQ) formulation is central to several ontology development and evaluation methodologies. Traditionally, the task of crafting these competency questions heavily relies on the effort of domain experts and knowledge engineers which is often time-consuming and labor-intensive. With the emergence of Large Language Models (LLMs), there arises the possibility to automate and enhance this process. Unlike other similar works which use existing ontologies or knowledge graphs as input to LLMs, we present a retrieval-augmented generation (RAG) approach that uses LLMs for the automatic generation of CQs given a set of scientific papers considered to be a domain knowledge base. We investigate its performance and specifically, we study the impact of different number of papers to the RAG and different temperature setting of the LLM. We conduct experiments using GPT-4 on two domain ontology engineering tasks and compare results against ground-truth CQs constructed by domain experts. Empirical assessments on the results, utilizing evaluation metrics (precision and consistency), reveal that compared to zero-shot prompting, adding relevant domain knowledge to the RAG improves the performance of LLMs on generating CQs for concrete ontology engineering tasks.
A Semantic Web Technology Index
Jan 14, 2022
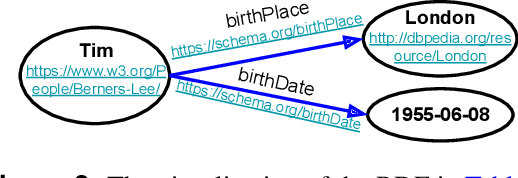
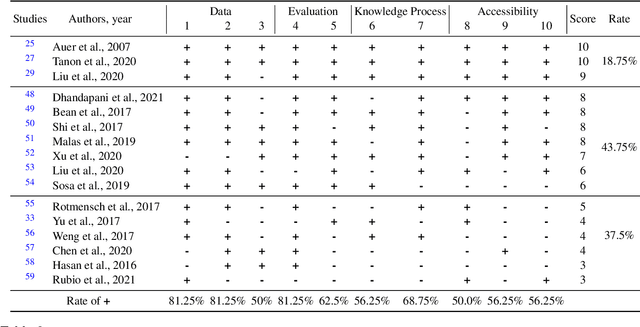
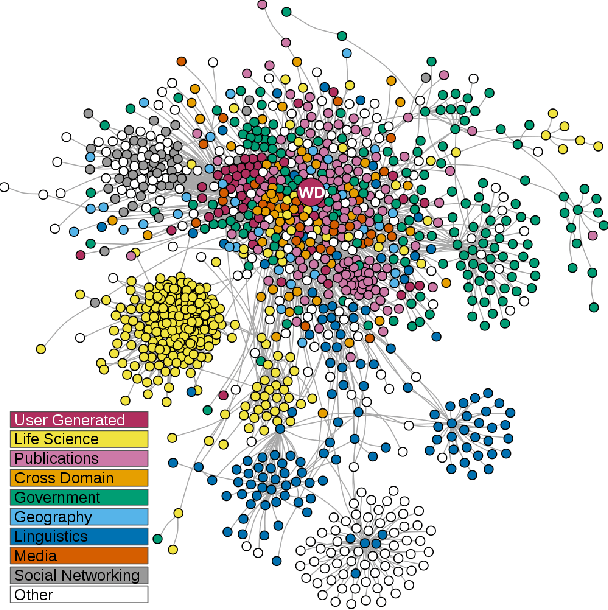
Semantic Web (SW) technology has been widely applied to many domains such as medicine, health care, finance, geology. At present, researchers mainly rely on their experience and preferences to develop and evaluate the work of SW technology. Although the general architecture (e.g., Tim Berners-Lee's Semantic Web Layer Cake) of SW technology was proposed many years ago and has been well-known, it still lacks a concrete guideline for standardizing the development of SW technology. In this paper, we propose an SW technology index to standardize the development for ensuring that the work of SW technology is designed well and to quantitatively evaluate the quality of the work in SW technology. This index consists of 10 criteria that quantify the quality as a score of 0 ~ 10. We address each criterion in detail for a clear explanation from three aspects: 1) what is the criterion? 2) why do we consider this criterion and 3) how do the current studies meet this criterion? Finally, we present the validation of this index by providing some examples of how to apply the index to the validation cases. We conclude that the index is a useful standard to guide and evaluate the work in SW technology.