 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA RAG Approach for Generating Competency Questions in Ontology Engineering
Sep 13, 2024



Competency question (CQ) formulation is central to several ontology development and evaluation methodologies. Traditionally, the task of crafting these competency questions heavily relies on the effort of domain experts and knowledge engineers which is often time-consuming and labor-intensive. With the emergence of Large Language Models (LLMs), there arises the possibility to automate and enhance this process. Unlike other similar works which use existing ontologies or knowledge graphs as input to LLMs, we present a retrieval-augmented generation (RAG) approach that uses LLMs for the automatic generation of CQs given a set of scientific papers considered to be a domain knowledge base. We investigate its performance and specifically, we study the impact of different number of papers to the RAG and different temperature setting of the LLM. We conduct experiments using GPT-4 on two domain ontology engineering tasks and compare results against ground-truth CQs constructed by domain experts. Empirical assessments on the results, utilizing evaluation metrics (precision and consistency), reveal that compared to zero-shot prompting, adding relevant domain knowledge to the RAG improves the performance of LLMs on generating CQs for concrete ontology engineering tasks.
The Wind in Our Sails: Developing a Reusable and Maintainable Dutch Maritime History Knowledge Graph
Nov 10, 2021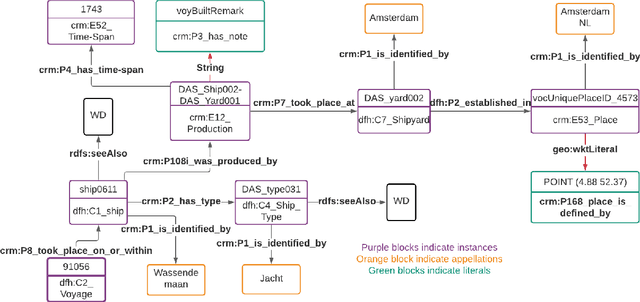
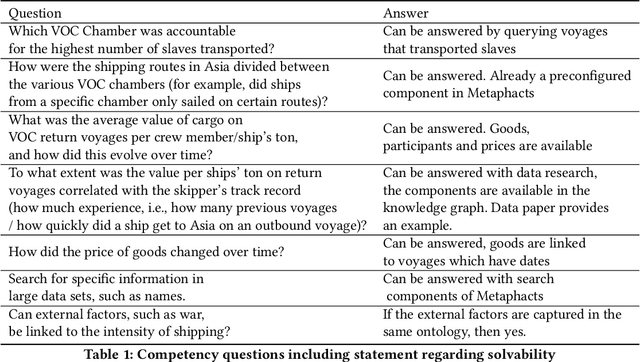
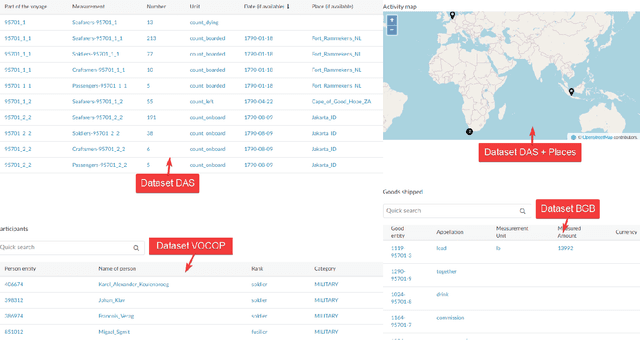
Digital sources are more prevalent than ever but effectively using them can be challenging. One core challenge is that digitized sources are often distributed, thus forcing researchers to spend time collecting, interpreting, and aligning different sources. A knowledge graph can accelerate research by providing a single connected source of truth that humans and machines can query. During two design-test cycles, we convert four data sets from the historical maritime domain into a knowledge graph. The focus during these cycles is on creating a sustainable and usable approach that can be adopted in other linked data conversion efforts. Furthermore, our knowledge graph is available for maritime historians and other interested users to investigate the daily business of the Dutch East India Company through a unified portal.
Ontologies in CLARIAH: Towards Interoperability in History, Language and Media
Apr 06, 2020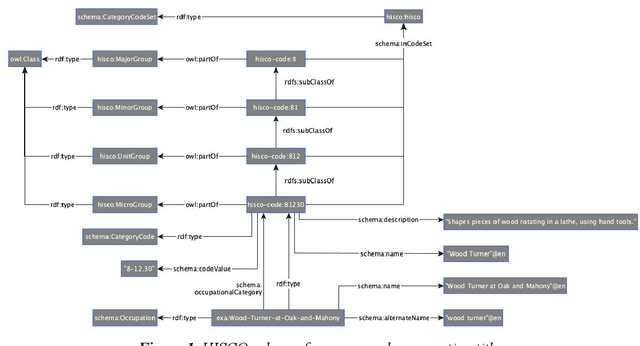
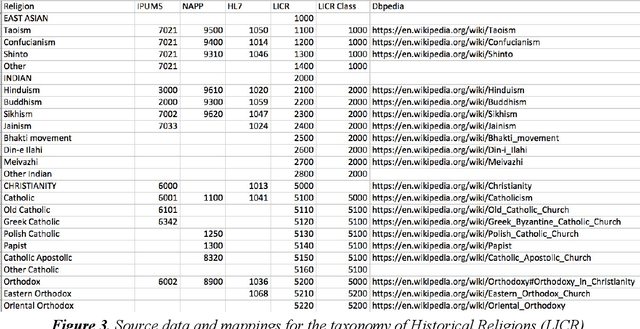
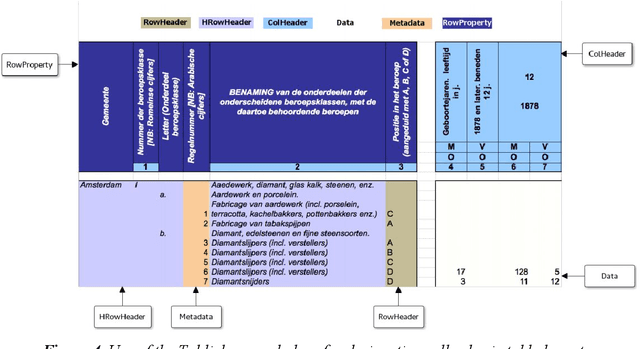
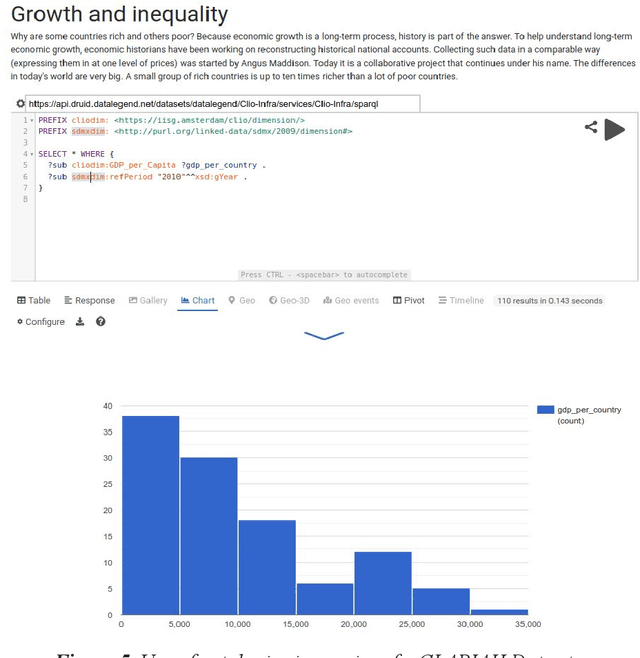
One of the most important goals of digital humanities is to provide researchers with data and tools for new research questions, either by increasing the scale of scholarly studies, linking existing databases, or improving the accessibility of data. Here, the FAIR principles provide a useful framework as these state that data needs to be: Findable, as they are often scattered among various sources; Accessible, since some might be offline or behind paywalls; Interoperable, thus using standard knowledge representation formats and shared vocabularies; and Reusable, through adequate licensing and permissions. Integrating data from diverse humanities domains is not trivial, research questions such as "was economic wealth equally distributed in the 18th century?", or "what are narratives constructed around disruptive media events?") and preparation phases (e.g. data collection, knowledge organisation, cleaning) of scholars need to be taken into account. In this chapter, we describe the ontologies and tools developed and integrated in the Dutch national project CLARIAH to address these issues across datasets from three fundamental domains or "pillars" of the humanities (linguistics, social and economic history, and media studies) that have paradigmatic data representations (textual corpora, structured data, and multimedia). We summarise the lessons learnt from using such ontologies and tools in these domains from a generalisation and reusability perspective.
BiographyNet: Extracting Relations Between People and Events
Jan 22, 2018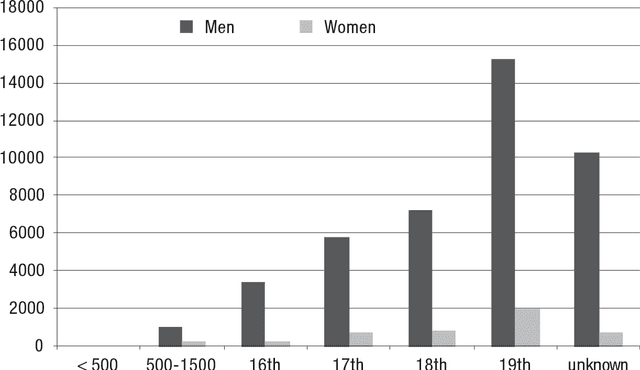
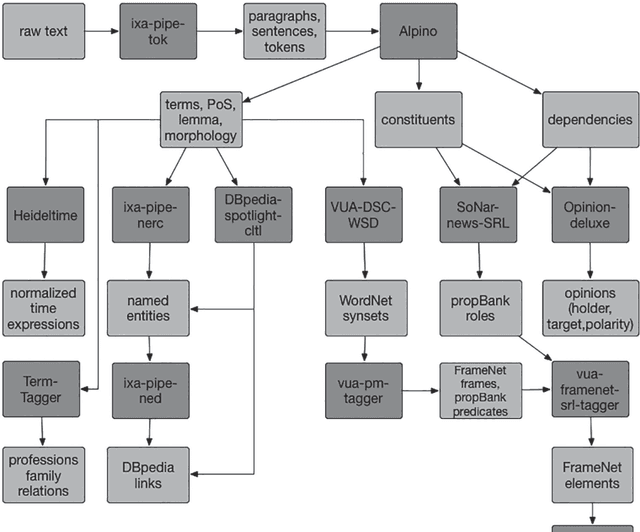
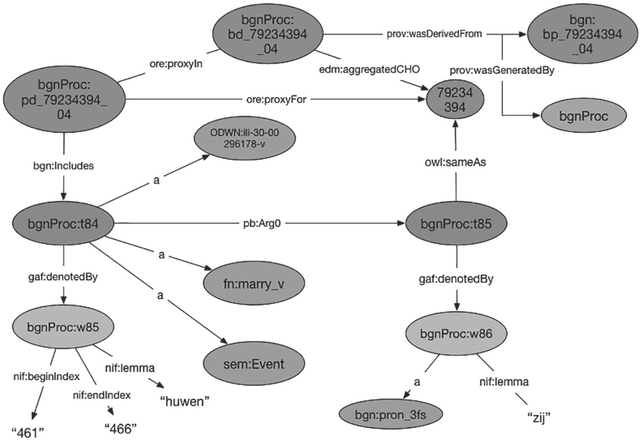
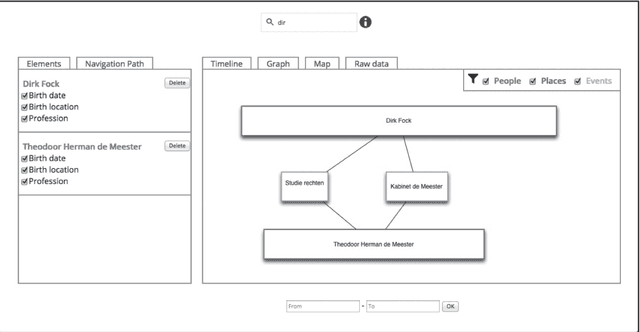
This paper describes BiographyNet, a digital humanities project (2012-2016) that brings together researchers from history, computational linguistics and computer science. The project uses data from the Biography Portal of the Netherlands (BPN), which contains approximately 125,000 biographies from a variety of Dutch biographical dictionaries from the eighteenth century until now, describing around 76,000 individuals. BiographyNet's aim is to strengthen the value of the portal and comparable biographical datasets for historical research, by improving the search options and the presentation of its outcome, with a historically justified NLP pipeline that works through a user evaluated demonstrator. The project's main target group are professional historians. The project therefore worked with two key concepts: ``provenance'' -understood as a term allowing for both historical source criticism and for references to data-management and programming interventions in digitized sources; and ``perspective'' interpreted as inherent uncertainty concerning the interpretation of historical results.