 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-up Anytime Discovery of Generalised Multimodal Graph Patterns for Knowledge Graphs
Oct 08, 2024Vast amounts of heterogeneous knowledge are becoming publicly available in the form of knowledge graphs, often linking multiple sources of data that have never been together before, and thereby enabling scholars to answer many new research questions. It is often not known beforehand, however, which questions the data might have the answers to, potentially leaving many interesting and novel insights to remain undiscovered. To support scholars during this scientific workflow, we introduce an anytime algorithm for the bottom-up discovery of generalized multimodal graph patterns in knowledge graphs. Each pattern is a conjunction of binary statements with (data-) type variables, constants, and/or value patterns. Upon discovery, the patterns are converted to SPARQL queries and presented in an interactive facet browser together with metadata and provenance information, enabling scholars to explore, analyse, and share queries. We evaluate our method from a user perspective, with the help of domain experts in the humanities.
Ontologies in CLARIAH: Towards Interoperability in History, Language and Media
Apr 06, 2020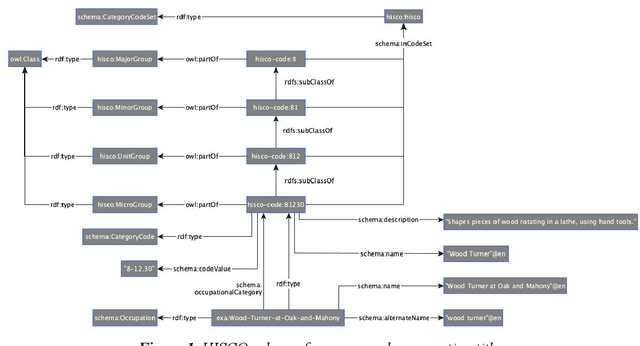
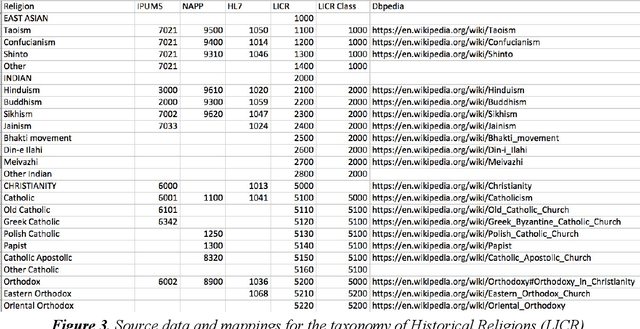
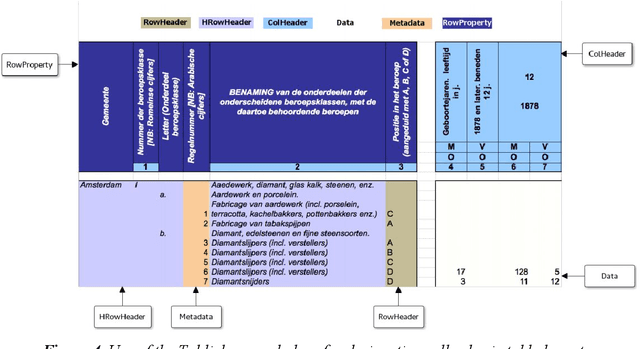
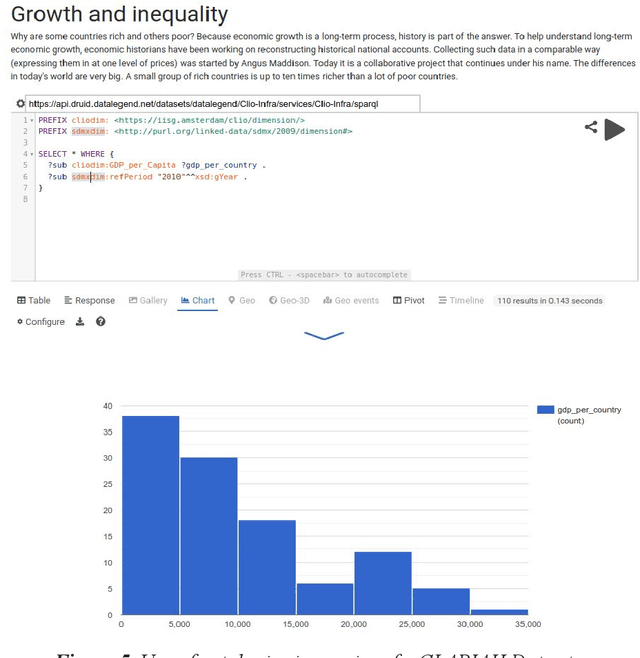
One of the most important goals of digital humanities is to provide researchers with data and tools for new research questions, either by increasing the scale of scholarly studies, linking existing databases, or improving the accessibility of data. Here, the FAIR principles provide a useful framework as these state that data needs to be: Findable, as they are often scattered among various sources; Accessible, since some might be offline or behind paywalls; Interoperable, thus using standard knowledge representation formats and shared vocabularies; and Reusable, through adequate licensing and permissions. Integrating data from diverse humanities domains is not trivial, research questions such as "was economic wealth equally distributed in the 18th century?", or "what are narratives constructed around disruptive media events?") and preparation phases (e.g. data collection, knowledge organisation, cleaning) of scholars need to be taken into account. In this chapter, we describe the ontologies and tools developed and integrated in the Dutch national project CLARIAH to address these issues across datasets from three fundamental domains or "pillars" of the humanities (linguistics, social and economic history, and media studies) that have paradigmatic data representations (textual corpora, structured data, and multimedia). We summarise the lessons learnt from using such ontologies and tools in these domains from a generalisation and reusability perspective.