 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the challenges of studying bias in Recommender Systems: A UserKNN case study
Sep 12, 2024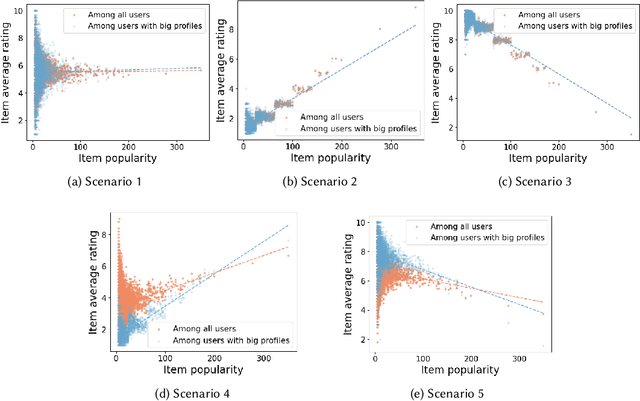

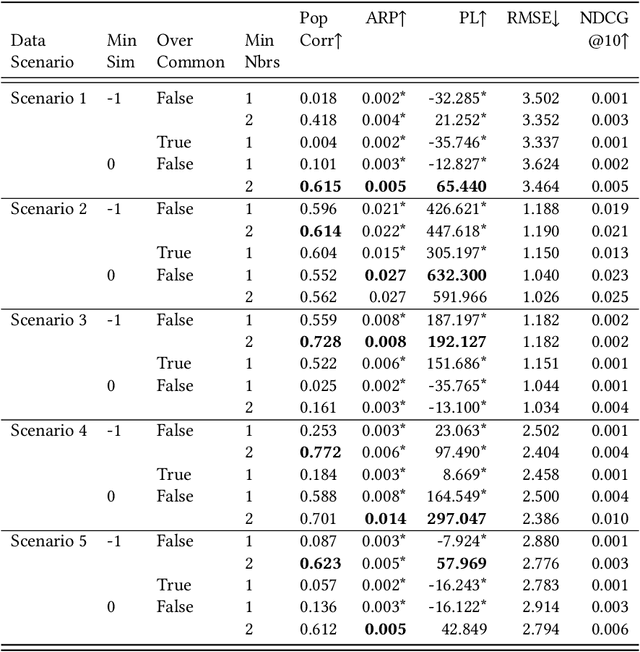
Statements on the propagation of bias by recommender systems are often hard to verify or falsify. Research on bias tends to draw from a small pool of publicly available datasets and is therefore bound by their specific properties. Additionally, implementation choices are often not explicitly described or motivated in research, while they may have an effect on bias propagation. In this paper, we explore the challenges of measuring and reporting popularity bias. We showcase the impact of data properties and algorithm configurations on popularity bias by combining synthetic data with well known recommender systems frameworks that implement UserKNN. First, we identify data characteristics that might impact popularity bias, based on the functionality of UserKNN. Accordingly, we generate various datasets that combine these characteristics. Second, we locate UserKNN configurations that vary across implementations in literature. We evaluate popularity bias for five synthetic datasets and five UserKNN configurations, and offer insights on their joint effect. We find that, depending on the data characteristics, various UserKNN configurations can lead to different conclusions regarding the propagation of popularity bias. These results motivate the need for explicitly addressing algorithmic configuration and data properties when reporting and interpreting bias in recommender systems.
How to Diversify any Personalized Recommender? A User-centric Pre-processing approach
May 03, 2024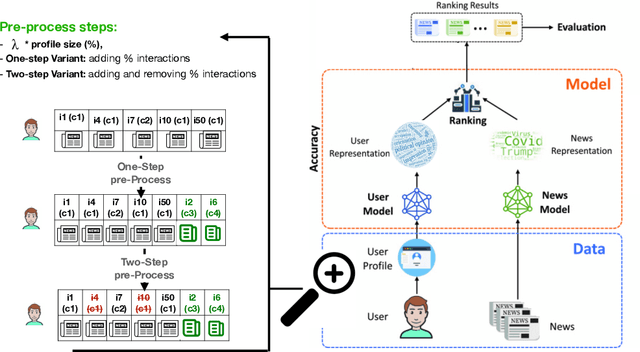
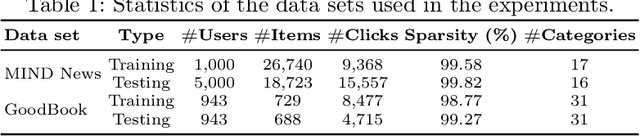
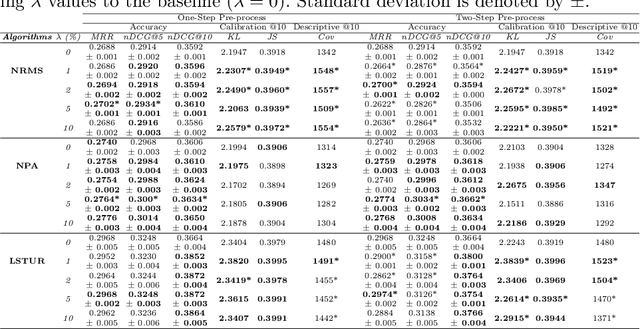
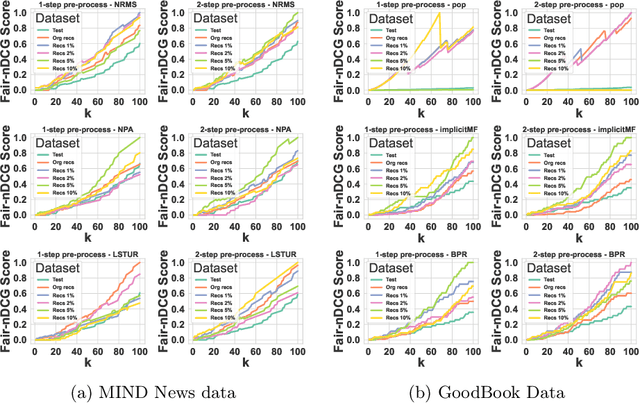
In this paper, we introduce a novel approach to improve the diversity of Top-N recommendations while maintaining recommendation performance. Our approach employs a user-centric pre-processing strategy aimed at exposing users to a wide array of content categories and topics. We personalize this strategy by selectively adding and removing a percentage of interactions from user profiles. This personalization ensures we remain closely aligned with user preferences while gradually introducing distribution shifts. Our pre-processing technique offers flexibility and can seamlessly integrate into any recommender architecture. To evaluate our approach, we run extensive experiments on two publicly available data sets for news and book recommendations. We test various standard and neural network-based recommender system algorithms. Our results show that our approach generates diverse recommendations, ensuring users are exposed to a wider range of items. Furthermore, leveraging pre-processed data for training leads to recommender systems achieving performance levels comparable to, and in some cases, better than those trained on original, unmodified data. Additionally, our approach promotes provider fairness by facilitating exposure to minority or niche categories.
When Machine Learning Models Leak: An Exploration of Synthetic Training Data
Oct 12, 2023We investigate an attack on a machine learning model that predicts whether a person or household will relocate in the next two years, i.e., a propensity-to-move classifier. The attack assumes that the attacker can query the model to obtain predictions and that the marginal distribution of the data on which the model was trained is publicly available. The attack also assumes that the attacker has obtained the values of non-sensitive attributes for a certain number of target individuals. The objective of the attack is to infer the values of sensitive attributes for these target individuals. We explore how replacing the original data with synthetic data when training the model impacts how successfully the attacker can infer sensitive attributes.\footnote{Original paper published at PSD 2022. The paper was subsequently updated.}
Minimizing Mindless Mentions: Recommendation with Minimal Necessary User Reviews
Aug 05, 2022

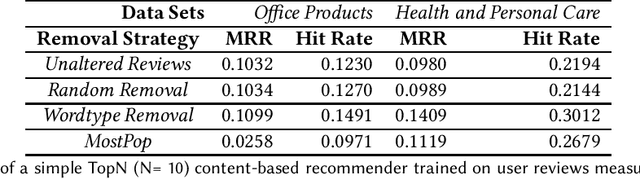
Recently, researchers have turned their attention to recommender systems that use only minimal necessary data. This trend is informed by the idea that recommender systems should use no more user interactions than are needed in order to provide users with useful recommendations. In this position paper, we make the case for applying the idea of minimal necessary data to recommender systems that use user reviews. We argue that the content of individual user reviews should be subject to minimization. Specifically, reviews used as training data to generate recommendations or reviews used to help users decide on purchases or consumption should be automatically edited to contain only the information that is needed.
Gender In Gender Out: A Closer Look at User Attributes in Context-Aware Recommendation
Jul 28, 2022
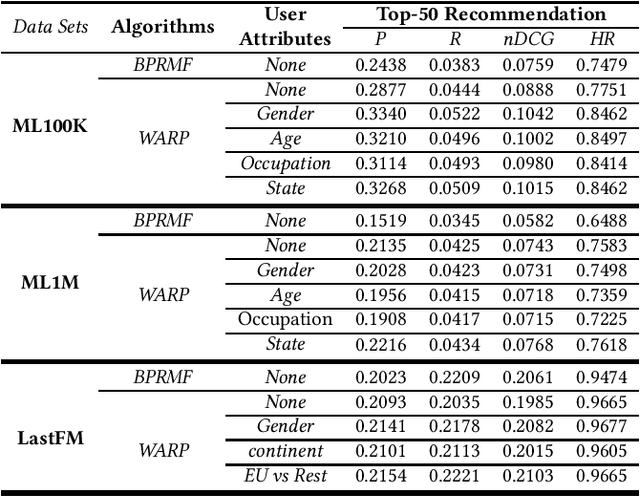
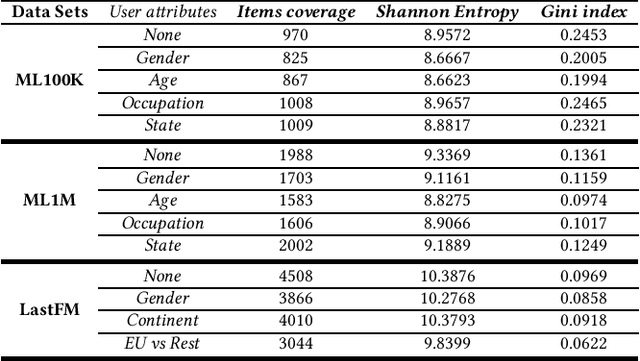
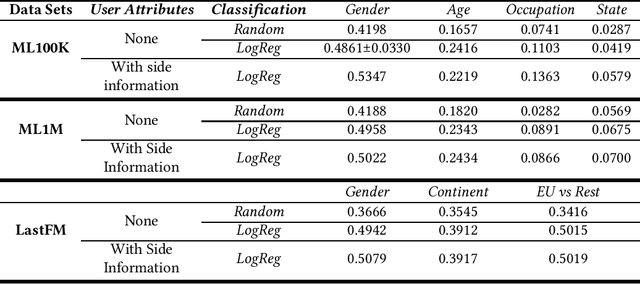
This paper studies user attributes in light of current concerns in the recommender system community: diversity, coverage, calibration, and data minimization. In experiments with a conventional context-aware recommender system that leverages side information, we show that user attributes do not always improve recommendation. Then, we demonstrate that user attributes can negatively impact diversity and coverage. Finally, we investigate the amount of information about users that ``survives'' from the training data into the recommendation lists produced by the recommender. This information is a weak signal that could in the future be exploited for calibration or studied further as a privacy leak.
Doing Data Right: How Lessons Learned Working with Conventional Data should Inform the Future of Synthetic Data for Recommender Systems
Oct 07, 2021We present a case that the newly emerging field of synthetic data in the area of recommender systems should prioritize `doing data right'. We consider this catchphrase to have two aspects: First, we should not repeat the mistakes of the past, and, second, we should explore the full scope of opportunities presented by synthetic data as we move into the future. We argue that explicit attention to dataset design and description will help to avoid past mistakes with dataset bias and evaluation. In order to fully exploit the opportunities of synthetic data, we point out that researchers can investigate new areas such as using data synthesize to support reproducibility by making data open, as well as FAIR, and to push forward our understanding of data minimization.