 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Training: Teaching Models Plausible and Actionable Explanations
Jan 22, 2026We propose a novel training regime termed counterfactual training that leverages counterfactual explanations to increase the explanatory capacity of models. Counterfactual explanations have emerged as a popular post-hoc explanation method for opaque machine learning models: they inform how factual inputs would need to change in order for a model to produce some desired output. To be useful in real-world decision-making systems, counterfactuals should be plausible with respect to the underlying data and actionable with respect to the feature mutability constraints. Much existing research has therefore focused on developing post-hoc methods to generate counterfactuals that meet these desiderata. In this work, we instead hold models directly accountable for the desired end goal: counterfactual training employs counterfactuals during the training phase to minimize the divergence between learned representations and plausible, actionable explanations. We demonstrate empirically and theoretically that our proposed method facilitates training models that deliver inherently desirable counterfactual explanations and additionally exhibit improved adversarial robustness.
On the challenges of studying bias in Recommender Systems: A UserKNN case study
Sep 12, 2024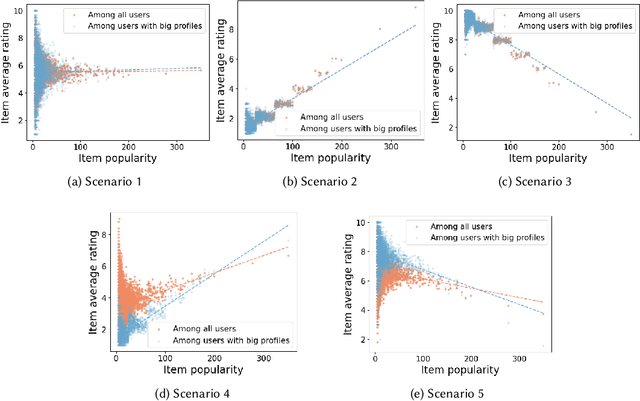

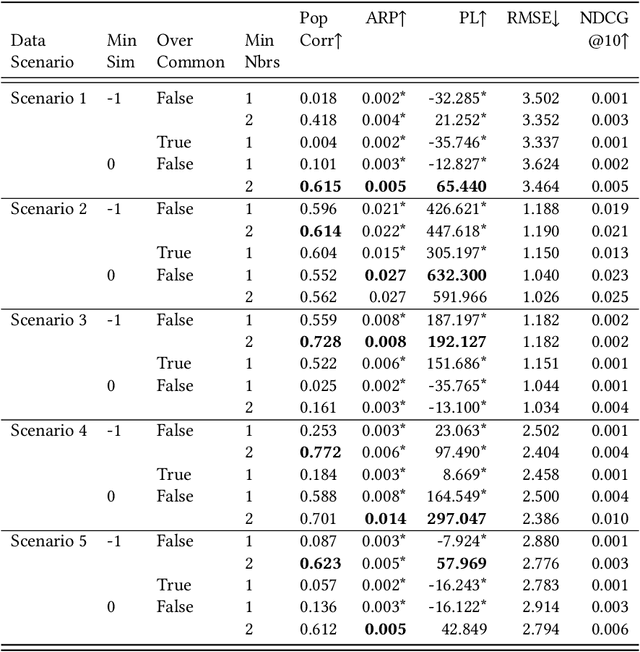
Statements on the propagation of bias by recommender systems are often hard to verify or falsify. Research on bias tends to draw from a small pool of publicly available datasets and is therefore bound by their specific properties. Additionally, implementation choices are often not explicitly described or motivated in research, while they may have an effect on bias propagation. In this paper, we explore the challenges of measuring and reporting popularity bias. We showcase the impact of data properties and algorithm configurations on popularity bias by combining synthetic data with well known recommender systems frameworks that implement UserKNN. First, we identify data characteristics that might impact popularity bias, based on the functionality of UserKNN. Accordingly, we generate various datasets that combine these characteristics. Second, we locate UserKNN configurations that vary across implementations in literature. We evaluate popularity bias for five synthetic datasets and five UserKNN configurations, and offer insights on their joint effect. We find that, depending on the data characteristics, various UserKNN configurations can lead to different conclusions regarding the propagation of popularity bias. These results motivate the need for explicitly addressing algorithmic configuration and data properties when reporting and interpreting bias in recommender systems.
Towards Estimating Personal Values in Song Lyrics
Aug 22, 2024



Most music widely consumed in Western Countries contains song lyrics, with U.S. samples reporting almost all of their song libraries contain lyrics. In parallel, social science theory suggests that personal values - the abstract goals that guide our decisions and behaviors - play an important role in communication: we share what is important to us to coordinate efforts, solve problems and meet challenges. Thus, the values communicated in song lyrics may be similar or different to those of the listener, and by extension affect the listener's reaction to the song. This suggests that working towards automated estimation of values in lyrics may assist in downstream MIR tasks, in particular, personalization. However, as highly subjective text, song lyrics present a challenge in terms of sampling songs to be annotated, annotation methods, and in choosing a method for aggregation. In this project, we take a perspectivist approach, guided by social science theory, to gathering annotations, estimating their quality, and aggregating them. We then compare aggregated ratings to estimates based on pre-trained sentence/word embedding models by employing a validated value dictionary. We discuss conceptually 'fuzzy' solutions to sampling and annotation challenges, promising initial results in annotation quality and in automated estimations, and future directions.
Position Paper: Against Spurious Sparks $-$ Dovelating Inflated AI Claims
Feb 07, 2024
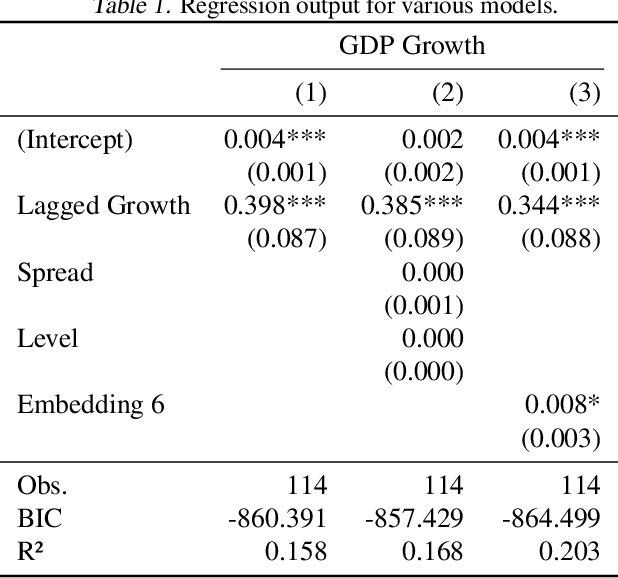

Humans have a tendency to see 'human'-like qualities in objects around them. We name our cars, and talk to pets and even household appliances, as if they could understand us as other humans do. This behavior, called anthropomorphism, is also seeing traction in Machine Learning (ML), where human-like intelligence is claimed to be perceived in Large Language Models (LLMs). In this position paper, considering professional incentives, human biases, and general methodological setups, we discuss how the current search for Artificial General Intelligence (AGI) is a perfect storm for over-attributing human-like qualities to LLMs. In several experiments, we demonstrate that the discovery of human-interpretable patterns in latent spaces should not be a surprising outcome. Also in consideration of common AI portrayal in the media, we call for the academic community to exercise extra caution, and to be extra aware of principles of academic integrity, in interpreting and communicating about AI research outcomes.
Faithful Model Explanations through Energy-Constrained Conformal Counterfactuals
Dec 17, 2023Counterfactual explanations offer an intuitive and straightforward way to explain black-box models and offer algorithmic recourse to individuals. To address the need for plausible explanations, existing work has primarily relied on surrogate models to learn how the input data is distributed. This effectively reallocates the task of learning realistic explanations for the data from the model itself to the surrogate. Consequently, the generated explanations may seem plausible to humans but need not necessarily describe the behaviour of the black-box model faithfully. We formalise this notion of faithfulness through the introduction of a tailored evaluation metric and propose a novel algorithmic framework for generating Energy-Constrained Conformal Counterfactuals that are only as plausible as the model permits. Through extensive empirical studies, we demonstrate that ECCCo reconciles the need for faithfulness and plausibility. In particular, we show that for models with gradient access, it is possible to achieve state-of-the-art performance without the need for surrogate models. To do so, our framework relies solely on properties defining the black-box model itself by leveraging recent advances in energy-based modelling and conformal prediction. To our knowledge, this is the first venture in this direction for generating faithful counterfactual explanations. Thus, we anticipate that ECCCo can serve as a baseline for future research. We believe that our work opens avenues for researchers and practitioners seeking tools to better distinguish trustworthy from unreliable models.
The Biased Journey of MSD_AUDIO.ZIP
Sep 02, 2023The equitable distribution of academic data is crucial for ensuring equal research opportunities, and ultimately further progress. Yet, due to the complexity of using the API for audio data that corresponds to the Million Song Dataset along with its misreporting (before 2016) and the discontinuation of this API (after 2016), access to this data has become restricted to those within certain affiliations that are connected peer-to-peer. In this paper, we delve into this issue, drawing insights from the experiences of 22 individuals who either attempted to access the data or played a role in its creation. With this, we hope to initiate more critical dialogue and more thoughtful consideration with regard to access privilege in the MIR community.
Endogenous Macrodynamics in Algorithmic Recourse
Aug 16, 2023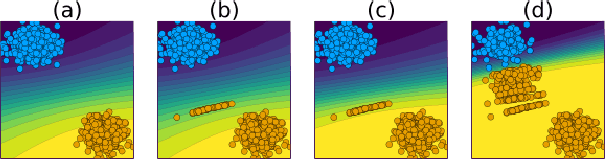
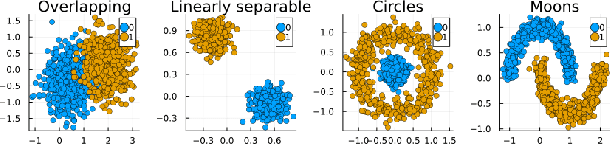
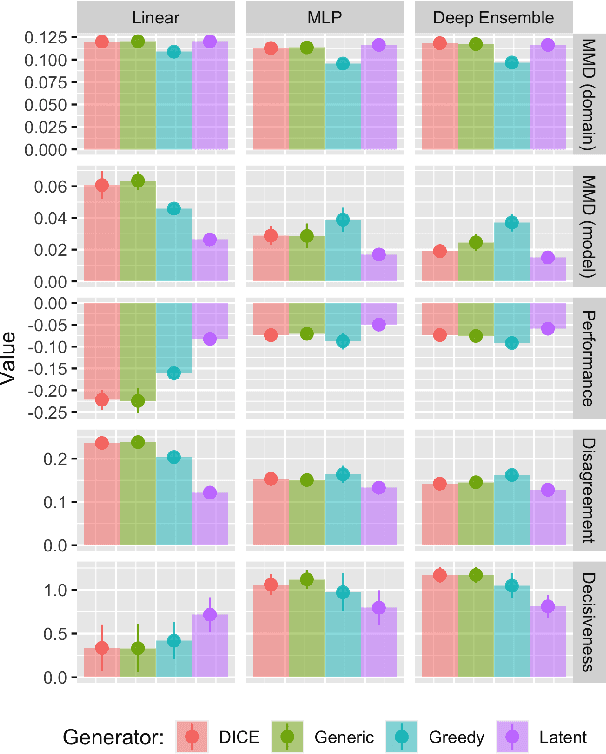
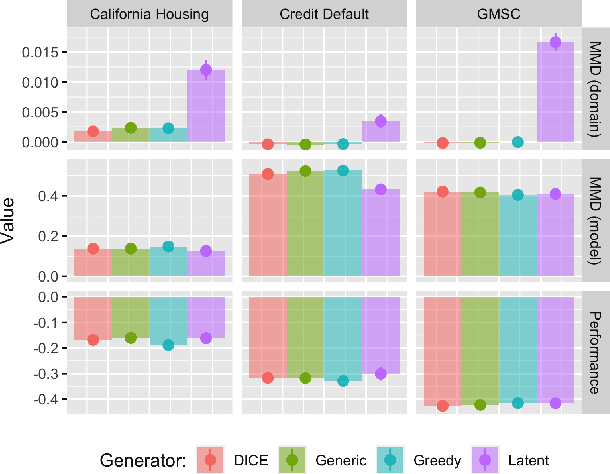
Existing work on Counterfactual Explanations (CE) and Algorithmic Recourse (AR) has largely focused on single individuals in a static environment: given some estimated model, the goal is to find valid counterfactuals for an individual instance that fulfill various desiderata. The ability of such counterfactuals to handle dynamics like data and model drift remains a largely unexplored research challenge. There has also been surprisingly little work on the related question of how the actual implementation of recourse by one individual may affect other individuals. Through this work, we aim to close that gap. We first show that many of the existing methodologies can be collectively described by a generalized framework. We then argue that the existing framework does not account for a hidden external cost of recourse, that only reveals itself when studying the endogenous dynamics of recourse at the group level. Through simulation experiments involving various state-of the-art counterfactual generators and several benchmark datasets, we generate large numbers of counterfactuals and study the resulting domain and model shifts. We find that the induced shifts are substantial enough to likely impede the applicability of Algorithmic Recourse in some situations. Fortunately, we find various strategies to mitigate these concerns. Our simulation framework for studying recourse dynamics is fast and opensourced.
* 12 pages, 11 figures. Originally published at the 2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE holds the copyright
Explaining Black-Box Models through Counterfactuals
Aug 14, 2023



We present CounterfactualExplanations.jl: a package for generating Counterfactual Explanations (CE) and Algorithmic Recourse (AR) for black-box models in Julia. CE explain how inputs into a model need to change to yield specific model predictions. Explanations that involve realistic and actionable changes can be used to provide AR: a set of proposed actions for individuals to change an undesirable outcome for the better. In this article, we discuss the usefulness of CE for Explainable Artificial Intelligence and demonstrate the functionality of our package. The package is straightforward to use and designed with a focus on customization and extensibility. We envision it to one day be the go-to place for explaining arbitrary predictive models in Julia through a diverse suite of counterfactual generators.
* 13 pages, 9 figures, originally published in The Proceedings of the JuliaCon Conferences (JCON)
Social Inclusion in Curated Contexts: Insights from Museum Practices
May 10, 2022

Artificial intelligence literature suggests that minority and fragile communities in society can be negatively impacted by machine learning algorithms due to inherent biases in the design process, which lead to socially exclusive decisions and policies. Faced with similar challenges in dealing with an increasingly diversified audience, the museum sector has seen changes in theory and practice, particularly in the areas of representation and meaning-making. While rarity and grandeur used to be at the centre stage of the early museum practices, folk life and museums' relationships with the diverse communities they serve become a widely integrated part of the contemporary practices. These changes address issues of diversity and accessibility in order to offer more socially inclusive services. Drawing on these changes and reflecting back on the AI world, we argue that the museum experience provides useful lessons for building AI with socially inclusive approaches, especially in situations in which both a collection and access to it will need to be curated or filtered, as frequently happens in search engines, recommender systems and digital libraries. We highlight three principles: (1) Instead of upholding the value of neutrality, practitioners are aware of the influences of their own backgrounds and those of others on their work. By not claiming to be neutral but practising cultural humility, the chances of addressing potential biases can be increased. (2) There should be room for situational interpretation beyond the stages of data collection and machine learning. Before applying models and predictions, the contexts in which relevant parties exist should be taken into account. (3) Community participation serves the needs of communities and has the added benefit of bringing practitioners and communities together.
ReproducedPapers.org: Openly teaching and structuring machine learning reproducibility
Dec 01, 2020

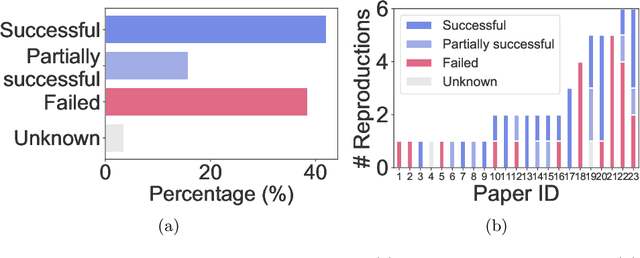
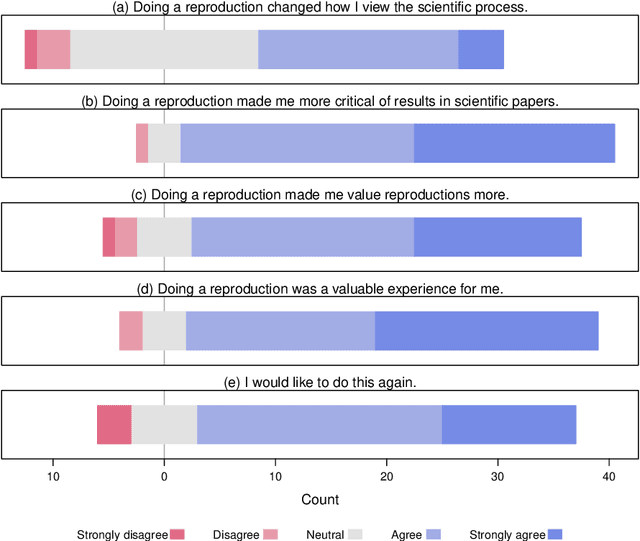
We present ReproducedPapers.org: an open online repository for teaching and structuring machine learning reproducibility. We evaluate doing a reproduction project among students and the added value of an online reproduction repository among AI researchers. We use anonymous self-assessment surveys and obtained 144 responses. Results suggest that students who do a reproduction project place more value on scientific reproductions and become more critical thinkers. Students and AI researchers agree that our online reproduction repository is valuable.