 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Using the Wilcoxon Test: Myth, Misconception and Misuse in IR Research
Apr 28, 2026In benchmarking of Information Retrieval systems, the Wilcoxon signed-rank test is often treated as a safer alternative to the t-test. This belief is fueled by textbooks and recommendations that portray Wilcoxon as the proper non-parametric alternative because metric scores are not normally distributed. We argue that this narrative is misleading and harmful. A careful review of Statistics textbooks reveals inconsistencies and omissions in how the assumptions underlying these tests are presented, fostering confusion that has propagated into IR research. As a result, Wilcoxon has been routinely misapplied for decades, creating a false sense of safety against a threat that was never there to begin with, while introducing another one so severe that it virtually guarantees the test will break down and mislead researchers. Through a combination of systematic literature review, analysis and empirical demonstrations with TREC data, we show how and why the Wilcoxon test easily loses control of its Type I error rate in IR settings. We conclude that the continued use of Wilcoxon in IR evaluation is unjustified and that abandoning it would improve the methodological soundness of our field.
The Treatment of Ties in Rank-Biased Overlap
Jun 11, 2024Rank-Biased Overlap (RBO) is a similarity measure for indefinite rankings: it is top-weighted, and can be computed when only a prefix of the rankings is known or when they have only some items in common. It is widely used for instance to analyze differences between search engines by comparing the rankings of documents they retrieve for the same queries. In these situations, though, it is very frequent to find tied documents that have the same score. Unfortunately, the treatment of ties in RBO remains superficial and incomplete, in the sense that it is not clear how to calculate it from the ranking prefixes only. In addition, the existing way of dealing with ties is very different from the one traditionally followed in the field of Statistics, most notably found in rank correlation coefficients such as Kendall's and Spearman's. In this paper we propose a generalized formulation for RBO to handle ties, thanks to which we complete the original definitions by showing how to perform prefix evaluation. We also use it to fully develop two variants that align with the ones found in the Statistics literature: one when there is a reference ranking to compare to, and one when there is not. Overall, these three variants provide researchers with flexibility when comparing rankings with RBO, by clearly determining what ties mean, and how they should be treated. Finally, using both synthetic and TREC data, we demonstrate the use of these new tie-aware RBO measures. We show that the scores may differ substantially from the original tie-unaware RBO measure, where ties had to be broken at random or by arbitrary criteria such as by document ID. Overall, these results evidence the need for a proper account of ties in rank similarity measures such as RBO.
Mitigating Mainstream Bias in Recommendation via Cost-sensitive Learning
Jul 25, 2023



Mainstream bias, where some users receive poor recommendations because their preferences are uncommon or simply because they are less active, is an important aspect to consider regarding fairness in recommender systems. Existing methods to mitigate mainstream bias do not explicitly model the importance of these non-mainstream users or, when they do, it is in a way that is not necessarily compatible with the data and recommendation model at hand. In contrast, we use the recommendation utility as a more generic and implicit proxy to quantify mainstreamness, and propose a simple user-weighting approach to incorporate it into the training process while taking the cost of potential recommendation errors into account. We provide extensive experimental results showing that quantifying mainstreamness via utility is better able at identifying non-mainstream users, and that they are indeed better served when training the model in a cost-sensitive way. This is achieved with negligible or no loss in overall recommendation accuracy, meaning that the models learn a better balance across users. In addition, we show that research of this kind, which evaluates recommendation quality at the individual user level, may not be reliable if not using enough interactions when assessing model performance.
New Insights into Metric Optimization for Ranking-based Recommendation
Jun 04, 2021
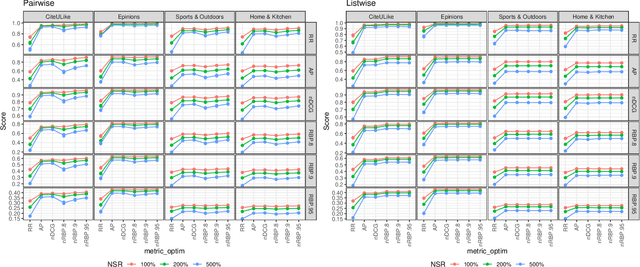

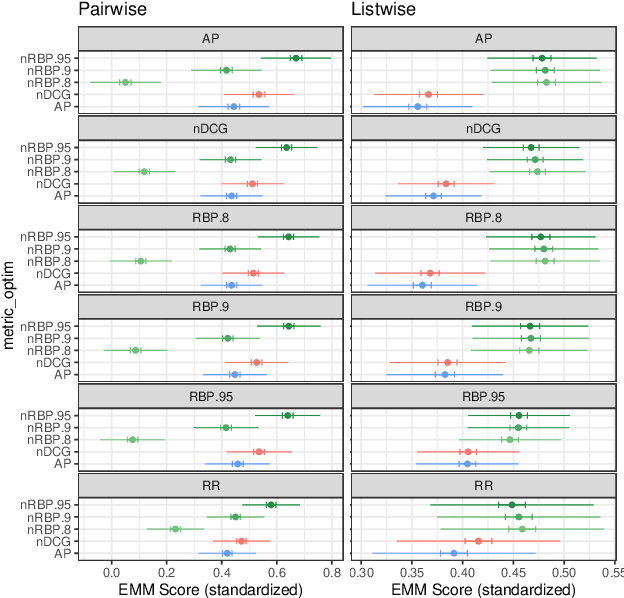
Direct optimization of IR metrics has often been adopted as an approach to devise and develop ranking-based recommender systems. Most methods following this approach aim at optimizing the same metric being used for evaluation, under the assumption that this will lead to the best performance. A number of studies of this practice bring this assumption, however, into question. In this paper, we dig deeper into this issue in order to learn more about the effects of the choice of the metric to optimize on the performance of a ranking-based recommender system. We present an extensive experimental study conducted on different datasets in both pairwise and listwise learning-to-rank scenarios, to compare the relative merit of four popular IR metrics, namely RR, AP, nDCG and RBP, when used for optimization and assessment of recommender systems in various combinations. For the first three, we follow the practice of loss function formulation available in literature. For the fourth one, we propose novel loss functions inspired by RBP for both the pairwise and listwise scenario. Our results confirm that the best performance is indeed not necessarily achieved when optimizing the same metric being used for evaluation. In fact, we find that RBP-inspired losses perform at least as well as other metrics in a consistent way, and offer clear benefits in several cases. Interesting to see is that RBP-inspired losses, while improving the recommendation performance for all uses, may lead to an individual performance gain that is correlated with the activity level of a user in interacting with items. The more active the users, the more they benefit. Overall, our results challenge the assumption behind the current research practice of optimizing and evaluating the same metric, and point to RBP-based optimization instead as a promising alternative when learning to rank in the recommendation context.
Leave No User Behind: Towards Improving the Utility of Recommender Systems for Non-mainstream Users
Feb 02, 2021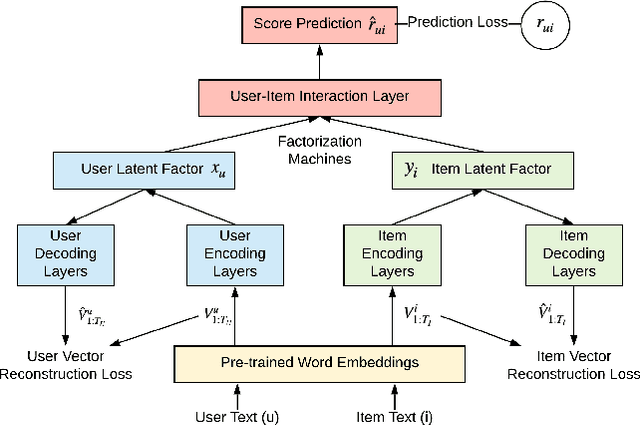

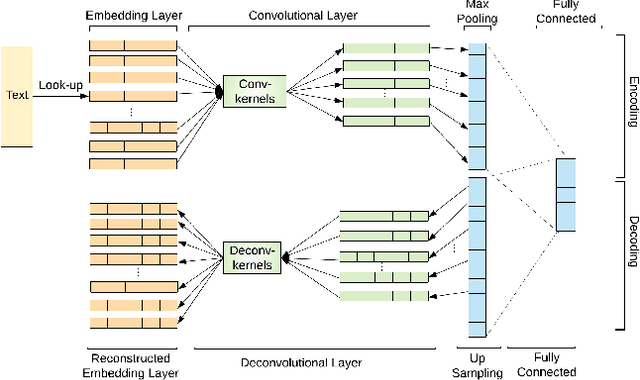

In a collaborative-filtering recommendation scenario, biases in the data will likely propagate in the learned recommendations. In this paper we focus on the so-called mainstream bias: the tendency of a recommender system to provide better recommendations to users who have a mainstream taste, as opposed to non-mainstream users. We propose NAECF, a conceptually simple but effective idea to address this bias. The idea consists of adding an autoencoder (AE) layer when learning user and item representations with text-based Convolutional Neural Networks. The AEs, one for the users and one for the items, serve as adversaries to the process of minimizing the rating prediction error when learning how to recommend. They enforce that the specific unique properties of all users and items are sufficiently well incorporated and preserved in the learned representations. These representations, extracted as the bottlenecks of the corresponding AEs, are expected to be less biased towards mainstream users, and to provide more balanced recommendation utility across all users. Our experimental results confirm these expectations, significantly improving the recommendations for non-mainstream users while maintaining the recommendation quality for mainstream users. Our results emphasize the importance of deploying extensive content-based features, such as online reviews, in order to better represent users and items to maximize the de-biasing effect.
Statistical Significance Testing in Information Retrieval: An Empirical Analysis of Type I, Type II and Type III Errors
Jun 05, 2019
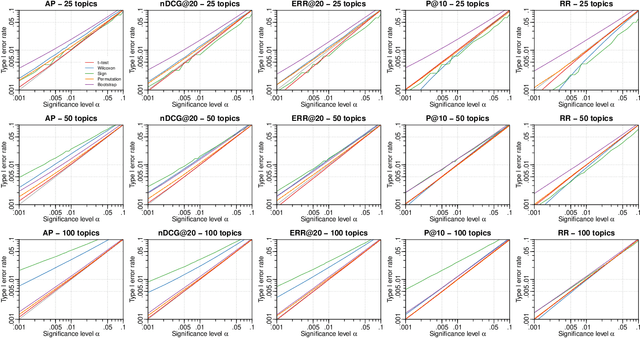

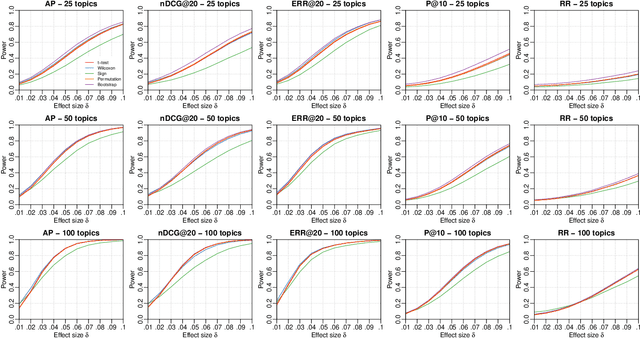
Statistical significance testing is widely accepted as a means to assess how well a difference in effectiveness reflects an actual difference between systems, as opposed to random noise because of the selection of topics. According to recent surveys on SIGIR, CIKM, ECIR and TOIS papers, the t-test is the most popular choice among IR researchers. However, previous work has suggested computer intensive tests like the bootstrap or the permutation test, based mainly on theoretical arguments. On empirical grounds, others have suggested non-parametric alternatives such as the Wilcoxon test. Indeed, the question of which tests we should use has accompanied IR and related fields for decades now. Previous theoretical studies on this matter were limited in that we know that test assumptions are not met in IR experiments, and empirical studies were limited in that we do not have the necessary control over the null hypotheses to compute actual Type I and Type II error rates under realistic conditions. Therefore, not only is it unclear which test to use, but also how much trust we should put in them. In contrast to past studies, in this paper we employ a recent simulation methodology from TREC data to go around these limitations. Our study comprises over 500 million p-values computed for a range of tests, systems, effectiveness measures, topic set sizes and effect sizes, and for both the 2-tail and 1-tail cases. Having such a large supply of IR evaluation data with full knowledge of the null hypotheses, we are finally in a position to evaluate how well statistical significance tests really behave with IR data, and make sound recommendations for practitioners.
Are Nearby Neighbors Relatives?: Diagnosing Deep Music Embedding Spaces
Apr 15, 2019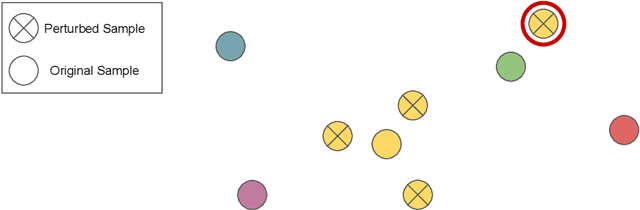


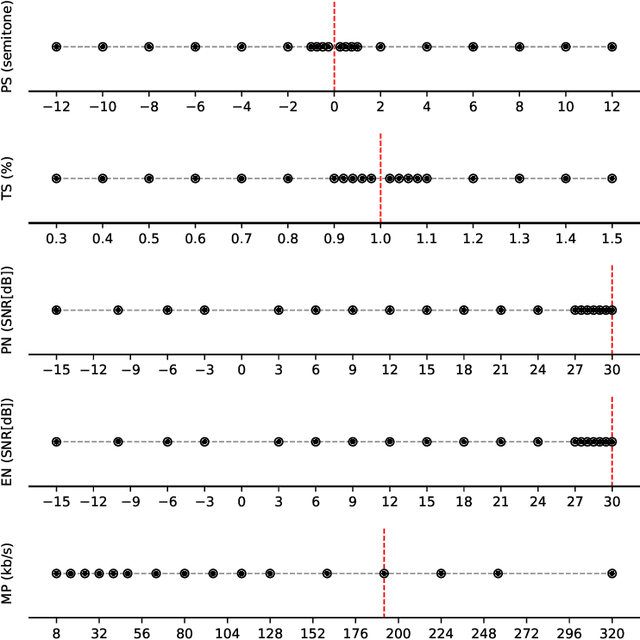
Deep neural networks have frequently been used to directly learn representations useful for a given task from raw input data. In terms of overall performance metrics, machine learning solutions employing deep representations frequently have been reported to greatly outperform those using hand-crafted feature representations. At the same time, they may pick up on aspects that are predominant in the data, yet not actually meaningful or interpretable. In this paper, we therefore propose a systematic way to diagnose the trustworthiness of deep music representations, considering musical semantics. The underlying assumption is that in case a deep representation is to be trusted, distance consistency between known related points should be maintained both in the input audio space and corresponding latent deep space. We generate known related points through semantically meaningful transformations, both considering imperceptible and graver transformations. Then, we examine within- and between-space distance consistencies, both considering audio space and latent embedded space, the latter either being a result of a conventional feature extractor or a deep encoder. We illustrate how our method, as a complement to task-specific performance, provides interpretable insight into what a network may have captured from training data signals.
One Deep Music Representation to Rule Them All? : A comparative analysis of different representation learning strategies
Oct 26, 2018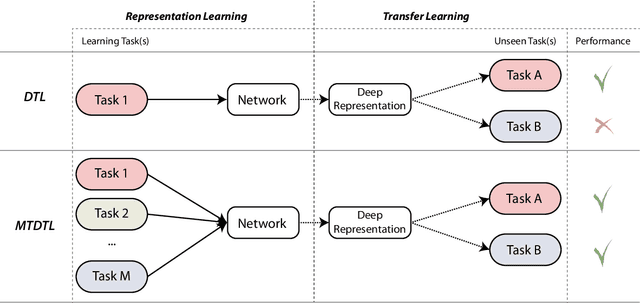

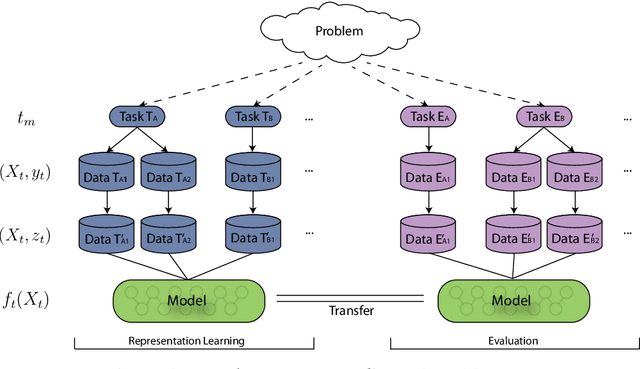

Inspired by the success of deploying deep learning in the fields of Computer Vision and Natural Language Processing, this learning paradigm has also found its way into the field of Music Information Retrieval. In order to benefit from deep learning in an effective, but also efficient manner, deep transfer learning has become a common approach. In this approach, it is possible to reuse the output of a pre-trained neural network as the basis for a new learning task. The underlying hypothesis is that if the initial and new learning tasks show commonalities and are applied to the same type of input data (e.g. music audio), the generated deep representation of the data is also informative for the new task. Since, however, most of the networks used to generate deep representations are trained using a single initial learning source, the validity of the above hypothesis is questionable for an arbitrary future task. In this paper, we present the results of our investigation of what the most important factor to generate deep representations for the data and learning tasks in the music domain. We conducted this investigation via an extensive empirical study that involves multiple learning sources, as well as multiple deep learning architectures with varying levels of information sharing between sources, in order to learn music representations. We then validate these representations considering multiple target datasets for evaluation. The results of our experiments yield several insights on how to approach the design of methods for learning widely deployable deep data representations in the music domain.
Information Retrieval Systems Adapted to the Biomedical Domain
Mar 30, 2012



The terminology used in Biomedicine shows lexical peculiarities that have required the elaboration of terminological resources and information retrieval systems with specific functionalities. The main characteristics are the high rates of synonymy and homonymy, due to phenomena such as the proliferation of polysemic acronyms and their interaction with common language. Information retrieval systems in the biomedical domain use techniques oriented to the treatment of these lexical peculiarities. In this paper we review some of the techniques used in this domain, such as the application of Natural Language Processing (BioNLP), the incorporation of lexical-semantic resources, and the application of Named Entity Recognition (BioNER). Finally, we present the evaluation methods adopted to assess the suitability of these techniques for retrieving biomedical resources.
* 6 pages, 4 tables