 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Insights into Metric Optimization for Ranking-based Recommendation
Paper and Code
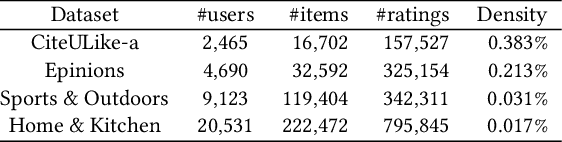
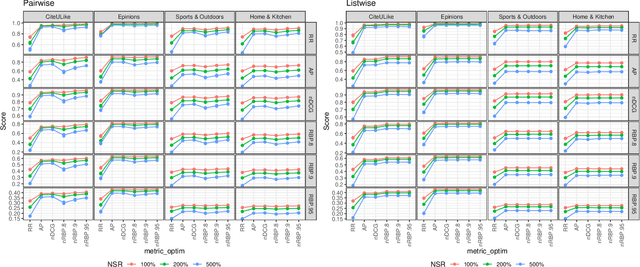

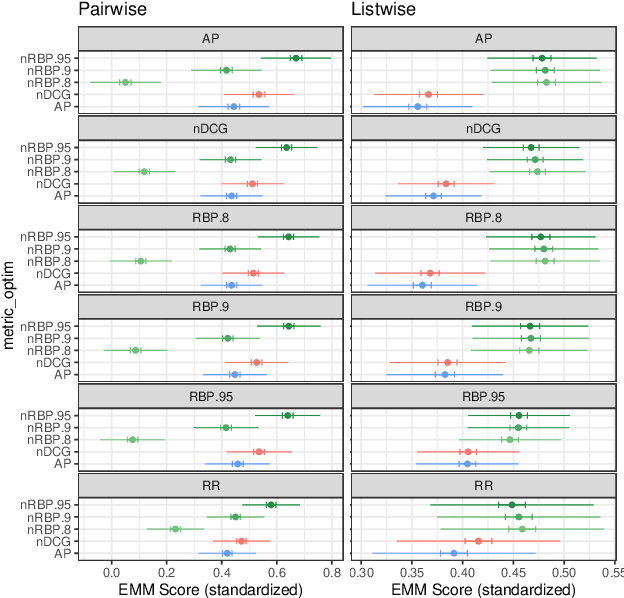
Direct optimization of IR metrics has often been adopted as an approach to devise and develop ranking-based recommender systems. Most methods following this approach aim at optimizing the same metric being used for evaluation, under the assumption that this will lead to the best performance. A number of studies of this practice bring this assumption, however, into question. In this paper, we dig deeper into this issue in order to learn more about the effects of the choice of the metric to optimize on the performance of a ranking-based recommender system. We present an extensive experimental study conducted on different datasets in both pairwise and listwise learning-to-rank scenarios, to compare the relative merit of four popular IR metrics, namely RR, AP, nDCG and RBP, when used for optimization and assessment of recommender systems in various combinations. For the first three, we follow the practice of loss function formulation available in literature. For the fourth one, we propose novel loss functions inspired by RBP for both the pairwise and listwise scenario. Our results confirm that the best performance is indeed not necessarily achieved when optimizing the same metric being used for evaluation. In fact, we find that RBP-inspired losses perform at least as well as other metrics in a consistent way, and offer clear benefits in several cases. Interesting to see is that RBP-inspired losses, while improving the recommendation performance for all uses, may lead to an individual performance gain that is correlated with the activity level of a user in interacting with items. The more active the users, the more they benefit. Overall, our results challenge the assumption behind the current research practice of optimizing and evaluating the same metric, and point to RBP-based optimization instead as a promising alternative when learning to rank in the recommendation context.