 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Optimization and Mainstream Bias Mitigation in Recommender Systems
Nov 11, 2023The first part of this thesis focuses on maximizing the overall recommendation accuracy. This accuracy is usually evaluated with some user-oriented metric tailored to the recommendation scenario, but because recommendation is usually treated as a machine learning problem, recommendation models are trained to maximize some other generic criteria that does not necessarily align with the criteria ultimately captured by the user-oriented evaluation metric. Recent research aims at bridging this gap between training and evaluation via direct ranking optimization, but still assumes that the metric used for evaluation should also be the metric used for training. We challenge this assumption, mainly because some metrics are more informative than others. Indeed, we show that models trained via the optimization of a loss inspired by Rank-Biased Precision (RBP) tend to yield higher accuracy, even when accuracy is measured with metrics other than RBP. However, the superiority of this RBP-inspired loss stems from further benefiting users who are already well-served, rather than helping those who are not. This observation inspires the second part of this thesis, where our focus turns to helping non-mainstream users. These are users who are difficult to recommend to either because there is not enough data to model them, or because they have niche taste and thus few similar users to look at when recommending in a collaborative way. These differences in mainstreamness introduce a bias reflected in an accuracy gap between users or user groups, which we try to narrow.
Mitigating Mainstream Bias in Recommendation via Cost-sensitive Learning
Jul 25, 2023



Mainstream bias, where some users receive poor recommendations because their preferences are uncommon or simply because they are less active, is an important aspect to consider regarding fairness in recommender systems. Existing methods to mitigate mainstream bias do not explicitly model the importance of these non-mainstream users or, when they do, it is in a way that is not necessarily compatible with the data and recommendation model at hand. In contrast, we use the recommendation utility as a more generic and implicit proxy to quantify mainstreamness, and propose a simple user-weighting approach to incorporate it into the training process while taking the cost of potential recommendation errors into account. We provide extensive experimental results showing that quantifying mainstreamness via utility is better able at identifying non-mainstream users, and that they are indeed better served when training the model in a cost-sensitive way. This is achieved with negligible or no loss in overall recommendation accuracy, meaning that the models learn a better balance across users. In addition, we show that research of this kind, which evaluates recommendation quality at the individual user level, may not be reliable if not using enough interactions when assessing model performance.
New Insights into Metric Optimization for Ranking-based Recommendation
Jun 04, 2021
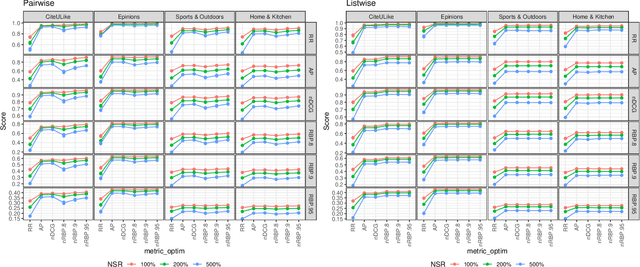

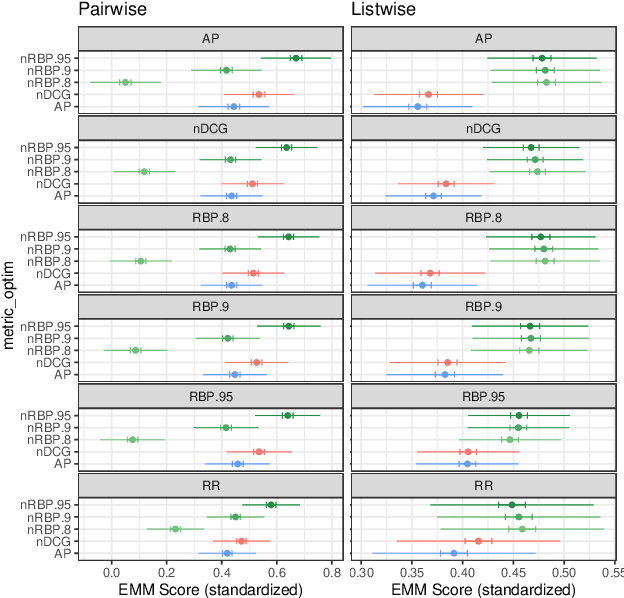
Direct optimization of IR metrics has often been adopted as an approach to devise and develop ranking-based recommender systems. Most methods following this approach aim at optimizing the same metric being used for evaluation, under the assumption that this will lead to the best performance. A number of studies of this practice bring this assumption, however, into question. In this paper, we dig deeper into this issue in order to learn more about the effects of the choice of the metric to optimize on the performance of a ranking-based recommender system. We present an extensive experimental study conducted on different datasets in both pairwise and listwise learning-to-rank scenarios, to compare the relative merit of four popular IR metrics, namely RR, AP, nDCG and RBP, when used for optimization and assessment of recommender systems in various combinations. For the first three, we follow the practice of loss function formulation available in literature. For the fourth one, we propose novel loss functions inspired by RBP for both the pairwise and listwise scenario. Our results confirm that the best performance is indeed not necessarily achieved when optimizing the same metric being used for evaluation. In fact, we find that RBP-inspired losses perform at least as well as other metrics in a consistent way, and offer clear benefits in several cases. Interesting to see is that RBP-inspired losses, while improving the recommendation performance for all uses, may lead to an individual performance gain that is correlated with the activity level of a user in interacting with items. The more active the users, the more they benefit. Overall, our results challenge the assumption behind the current research practice of optimizing and evaluating the same metric, and point to RBP-based optimization instead as a promising alternative when learning to rank in the recommendation context.
Leave No User Behind: Towards Improving the Utility of Recommender Systems for Non-mainstream Users
Feb 02, 2021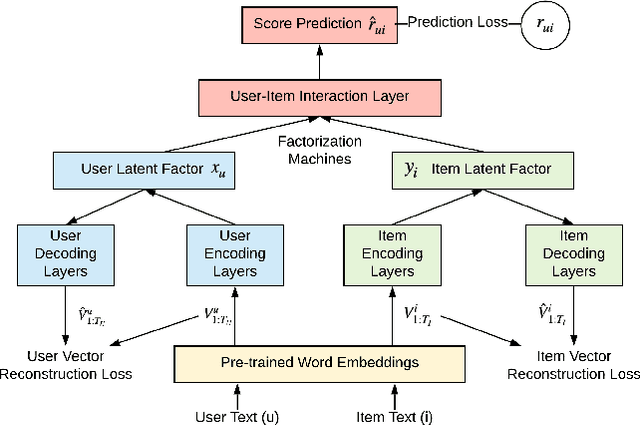

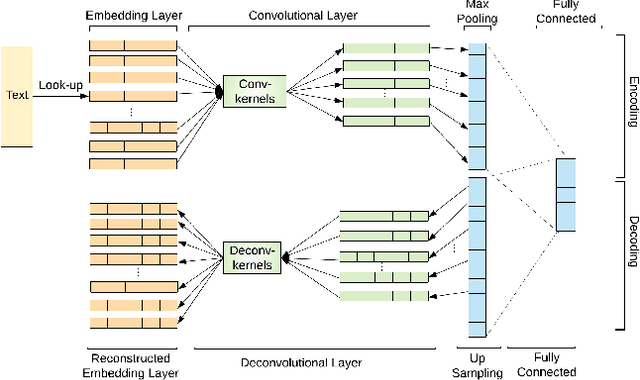

In a collaborative-filtering recommendation scenario, biases in the data will likely propagate in the learned recommendations. In this paper we focus on the so-called mainstream bias: the tendency of a recommender system to provide better recommendations to users who have a mainstream taste, as opposed to non-mainstream users. We propose NAECF, a conceptually simple but effective idea to address this bias. The idea consists of adding an autoencoder (AE) layer when learning user and item representations with text-based Convolutional Neural Networks. The AEs, one for the users and one for the items, serve as adversaries to the process of minimizing the rating prediction error when learning how to recommend. They enforce that the specific unique properties of all users and items are sufficiently well incorporated and preserved in the learned representations. These representations, extracted as the bottlenecks of the corresponding AEs, are expected to be less biased towards mainstream users, and to provide more balanced recommendation utility across all users. Our experimental results confirm these expectations, significantly improving the recommendations for non-mainstream users while maintaining the recommendation quality for mainstream users. Our results emphasize the importance of deploying extensive content-based features, such as online reviews, in order to better represent users and items to maximize the de-biasing effect.