 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDub-S2ST: Textless Speech-to-Speech Translation for Seamless Dubbing
May 27, 2025



This paper introduces a cross-lingual dubbing system that translates speech from one language to another while preserving key characteristics such as duration, speaker identity, and speaking speed. Despite the strong translation quality of existing speech translation approaches, they often overlook the transfer of speech patterns, leading to mismatches with source speech and limiting their suitability for dubbing applications. To address this, we propose a discrete diffusion-based speech-to-unit translation model with explicit duration control, enabling time-aligned translation. We then synthesize speech based on the predicted units and source identity with a conditional flow matching model. Additionally, we introduce a unit-based speed adaptation mechanism that guides the translation model to produce speech at a rate consistent with the source, without relying on any text. Extensive experiments demonstrate that our framework generates natural and fluent translations that align with the original speech's duration and speaking pace, while achieving competitive translation performance.
AdaptVC: High Quality Voice Conversion with Adaptive Learning
Jan 07, 2025



The goal of voice conversion is to transform the speech of a source speaker to sound like that of a reference speaker while preserving the original content. A key challenge is to extract disentangled linguistic content from the source and voice style from the reference. While existing approaches leverage various methods to isolate the two, a generalization still requires further attention, especially for robustness in zero-shot scenarios. In this paper, we achieve successful disentanglement of content and speaker features by tuning self-supervised speech features with adapters. The adapters are trained to dynamically encode nuanced features from rich self-supervised features, and the decoder fuses them to produce speech that accurately resembles the reference with minimal loss of content. Moreover, we leverage a conditional flow matching decoder with cross-attention speaker conditioning to further boost the synthesis quality and efficiency. Subjective and objective evaluations in a zero-shot scenario demonstrate that the proposed method outperforms existing models in speech quality and similarity to the reference speech.
Towards Estimating Personal Values in Song Lyrics
Aug 22, 2024



Most music widely consumed in Western Countries contains song lyrics, with U.S. samples reporting almost all of their song libraries contain lyrics. In parallel, social science theory suggests that personal values - the abstract goals that guide our decisions and behaviors - play an important role in communication: we share what is important to us to coordinate efforts, solve problems and meet challenges. Thus, the values communicated in song lyrics may be similar or different to those of the listener, and by extension affect the listener's reaction to the song. This suggests that working towards automated estimation of values in lyrics may assist in downstream MIR tasks, in particular, personalization. However, as highly subjective text, song lyrics present a challenge in terms of sampling songs to be annotated, annotation methods, and in choosing a method for aggregation. In this project, we take a perspectivist approach, guided by social science theory, to gathering annotations, estimating their quality, and aggregating them. We then compare aggregated ratings to estimates based on pre-trained sentence/word embedding models by employing a validated value dictionary. We discuss conceptually 'fuzzy' solutions to sampling and annotation challenges, promising initial results in annotation quality and in automated estimations, and future directions.
FreGrad: Lightweight and Fast Frequency-aware Diffusion Vocoder
Jan 18, 2024The goal of this paper is to generate realistic audio with a lightweight and fast diffusion-based vocoder, named FreGrad. Our framework consists of the following three key components: (1) We employ discrete wavelet transform that decomposes a complicated waveform into sub-band wavelets, which helps FreGrad to operate on a simple and concise feature space, (2) We design a frequency-aware dilated convolution that elevates frequency awareness, resulting in generating speech with accurate frequency information, and (3) We introduce a bag of tricks that boosts the generation quality of the proposed model. In our experiments, FreGrad achieves 3.7 times faster training time and 2.2 times faster inference speed compared to our baseline while reducing the model size by 0.6 times (only 1.78M parameters) without sacrificing the output quality. Audio samples are available at: https://mm.kaist.ac.kr/projects/FreGrad.
Similar but Faster: Manipulation of Tempo in Music Audio Embeddings for Tempo Prediction and Search
Jan 17, 2024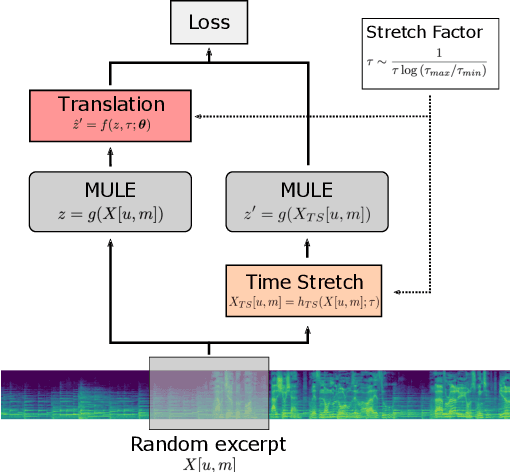
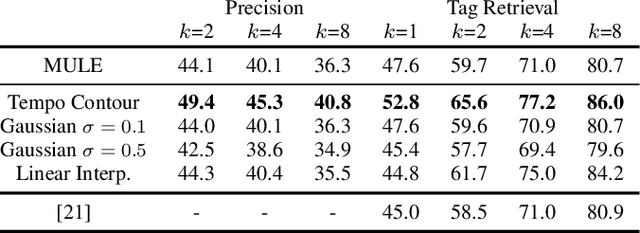
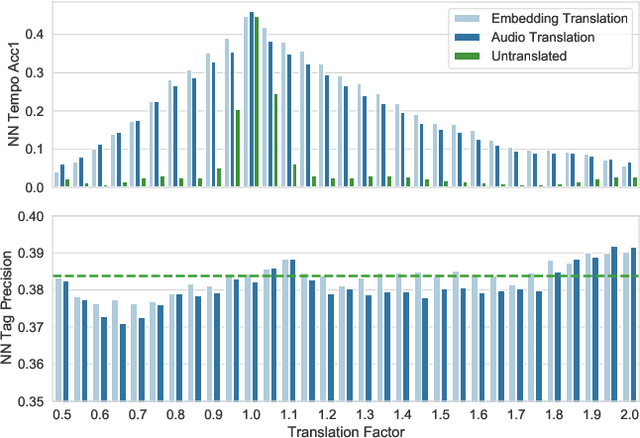
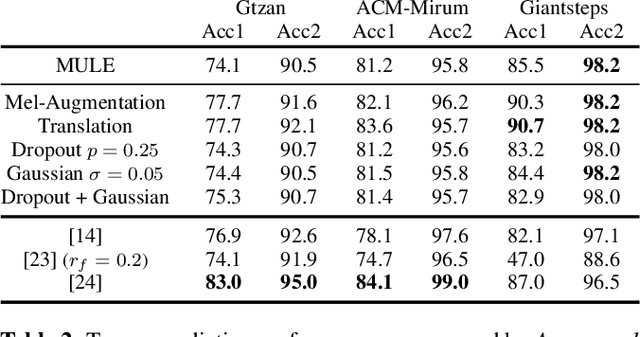
Audio embeddings enable large scale comparisons of the similarity of audio files for applications such as search and recommendation. Due to the subjectivity of audio similarity, it can be desirable to design systems that answer not only whether audio is similar, but similar in what way (e.g., wrt. tempo, mood or genre). Previous works have proposed disentangled embedding spaces where subspaces representing specific, yet possibly correlated, attributes can be weighted to emphasize those attributes in downstream tasks. However, no research has been conducted into the independence of these subspaces, nor their manipulation, in order to retrieve tracks that are similar but different in a specific way. Here, we explore the manipulation of tempo in embedding spaces as a case-study towards this goal. We propose tempo translation functions that allow for efficient manipulation of tempo within a pre-existing embedding space whilst maintaining other properties such as genre. As this translation is specific to tempo it enables retrieval of tracks that are similar but have specifically different tempi. We show that such a function can be used as an efficient data augmentation strategy for both training of downstream tempo predictors, and improved nearest neighbor retrieval of properties largely independent of tempo.
On the Effect of Data-Augmentation on Local Embedding Properties in the Contrastive Learning of Music Audio Representations
Jan 17, 2024



Audio embeddings are crucial tools in understanding large catalogs of music. Typically embeddings are evaluated on the basis of the performance they provide in a wide range of downstream tasks, however few studies have investigated the local properties of the embedding spaces themselves which are important in nearest neighbor algorithms, commonly used in music search and recommendation. In this work we show that when learning audio representations on music datasets via contrastive learning, musical properties that are typically homogeneous within a track (e.g., key and tempo) are reflected in the locality of neighborhoods in the resulting embedding space. By applying appropriate data augmentation strategies, localisation of such properties can not only be reduced but the localisation of other attributes is increased. For example, locality of features such as pitch and tempo that are less relevant to non-expert listeners, may be mitigated while improving the locality of more salient features such as genre and mood, achieving state-of-the-art performance in nearest neighbor retrieval accuracy. Similarly, we show that the optimal selection of data augmentation strategies for contrastive learning of music audio embeddings is dependent on the downstream task, highlighting this as an important embedding design decision.
Tempo estimation as fully self-supervised binary classification
Jan 17, 2024This paper addresses the problem of global tempo estimation in musical audio. Given that annotating tempo is time-consuming and requires certain musical expertise, few publicly available data sources exist to train machine learning models for this task. Towards alleviating this issue, we propose a fully self-supervised approach that does not rely on any human labeled data. Our method builds on the fact that generic (music) audio embeddings already encode a variety of properties, including information about tempo, making them easily adaptable for downstream tasks. While recent work in self-supervised tempo estimation aimed to learn a tempo specific representation that was subsequently used to train a supervised classifier, we reformulate the task into the binary classification problem of predicting whether a target track has the same or a different tempo compared to a reference. While the former still requires labeled training data for the final classification model, our approach uses arbitrary unlabeled music data in combination with time-stretching for model training as well as a small set of synthetically created reference samples for predicting the final tempo. Evaluation of our approach in comparison with the state-of-the-art reveals highly competitive performance when the constraint of finding the precise tempo octave is relaxed.
Seeing Through the Conversation: Audio-Visual Speech Separation based on Diffusion Model
Oct 30, 2023The objective of this work is to extract target speaker's voice from a mixture of voices using visual cues. Existing works on audio-visual speech separation have demonstrated their performance with promising intelligibility, but maintaining naturalness remains a challenge. To address this issue, we propose AVDiffuSS, an audio-visual speech separation model based on a diffusion mechanism known for its capability in generating natural samples. For an effective fusion of the two modalities for diffusion, we also propose a cross-attention-based feature fusion mechanism. This mechanism is specifically tailored for the speech domain to integrate the phonetic information from audio-visual correspondence in speech generation. In this way, the fusion process maintains the high temporal resolution of the features, without excessive computational requirements. We demonstrate that the proposed framework achieves state-of-the-art results on two benchmarks, including VoxCeleb2 and LRS3, producing speech with notably better naturalness.
Let There Be Sound: Reconstructing High Quality Speech from Silent Videos
Aug 29, 2023The goal of this work is to reconstruct high quality speech from lip motions alone, a task also known as lip-to-speech. A key challenge of lip-to-speech systems is the one-to-many mapping caused by (1) the existence of homophenes and (2) multiple speech variations, resulting in a mispronounced and over-smoothed speech. In this paper, we propose a novel lip-to-speech system that significantly improves the generation quality by alleviating the one-to-many mapping problem from multiple perspectives. Specifically, we incorporate (1) self-supervised speech representations to disambiguate homophenes, and (2) acoustic variance information to model diverse speech styles. Additionally, to better solve the aforementioned problem, we employ a flow based post-net which captures and refines the details of the generated speech. We perform extensive experiments and demonstrate that our method achieves the generation quality close to that of real human utterance, outperforming existing methods in terms of speech naturalness and intelligibility by a large margin. Synthesised samples are available at the anonymous demo page: https://mm.kaist.ac.kr/projects/LTBS.
Contrastive Learning for Cross-modal Artist Retrieval
Aug 12, 2023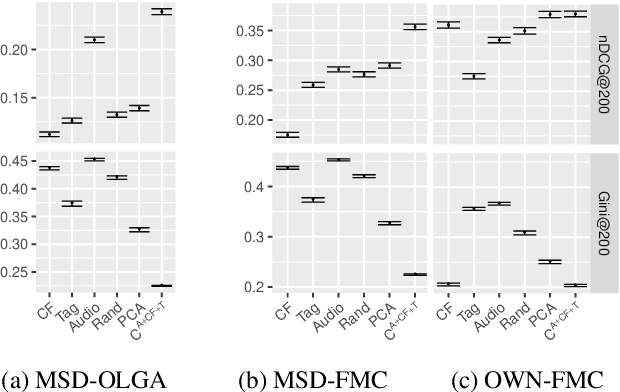



Music retrieval and recommendation applications often rely on content features encoded as embeddings, which provide vector representations of items in a music dataset. Numerous complementary embeddings can be derived from processing items originally represented in several modalities, e.g., audio signals, user interaction data, or editorial data. However, data of any given modality might not be available for all items in any music dataset. In this work, we propose a method based on contrastive learning to combine embeddings from multiple modalities and explore the impact of the presence or absence of embeddings from diverse modalities in an artist similarity task. Experiments on two datasets suggest that our contrastive method outperforms single-modality embeddings and baseline algorithms for combining modalities, both in terms of artist retrieval accuracy and coverage. Improvements with respect to other methods are particularly significant for less popular query artists. We demonstrate our method successfully combines complementary information from diverse modalities, and is more robust to missing modality data (i.e., it better handles the retrieval of artists with different modality embeddings than the query artist's).