 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilar but Faster: Manipulation of Tempo in Music Audio Embeddings for Tempo Prediction and Search
Paper and Code
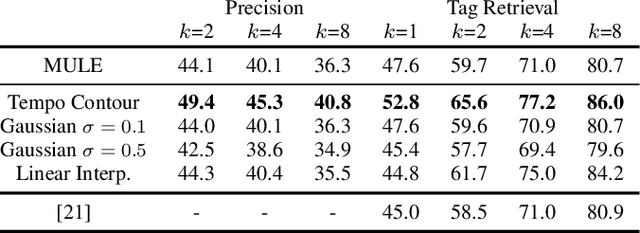
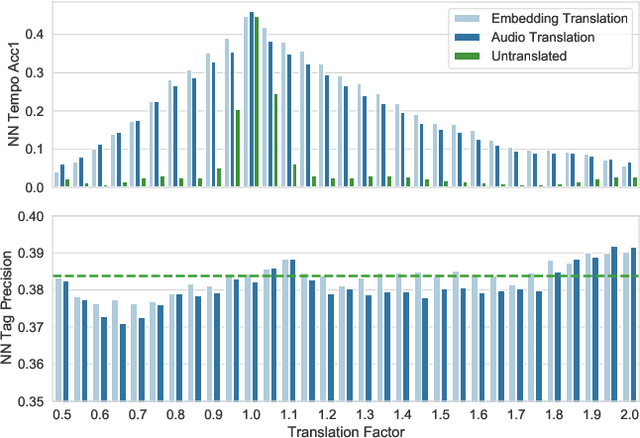
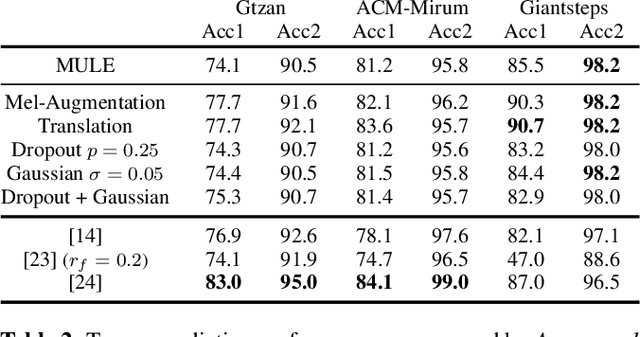
Audio embeddings enable large scale comparisons of the similarity of audio files for applications such as search and recommendation. Due to the subjectivity of audio similarity, it can be desirable to design systems that answer not only whether audio is similar, but similar in what way (e.g., wrt. tempo, mood or genre). Previous works have proposed disentangled embedding spaces where subspaces representing specific, yet possibly correlated, attributes can be weighted to emphasize those attributes in downstream tasks. However, no research has been conducted into the independence of these subspaces, nor their manipulation, in order to retrieve tracks that are similar but different in a specific way. Here, we explore the manipulation of tempo in embedding spaces as a case-study towards this goal. We propose tempo translation functions that allow for efficient manipulation of tempo within a pre-existing embedding space whilst maintaining other properties such as genre. As this translation is specific to tempo it enables retrieval of tracks that are similar but have specifically different tempi. We show that such a function can be used as an efficient data augmentation strategy for both training of downstream tempo predictors, and improved nearest neighbor retrieval of properties largely independent of tempo.