 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilar but Faster: Manipulation of Tempo in Music Audio Embeddings for Tempo Prediction and Search
Jan 17, 2024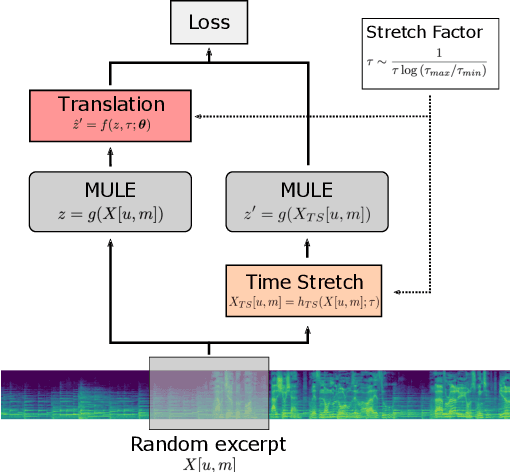
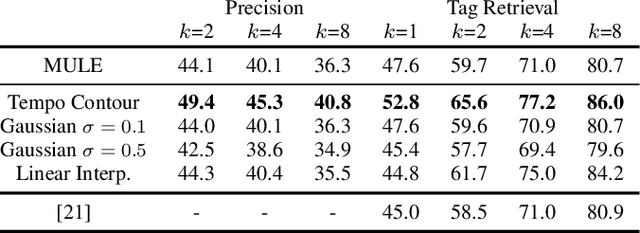
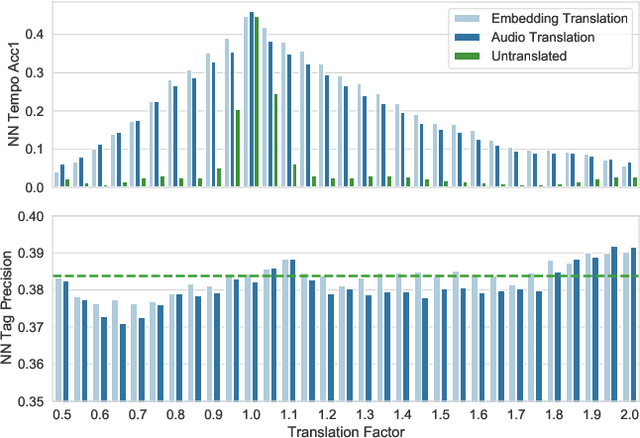
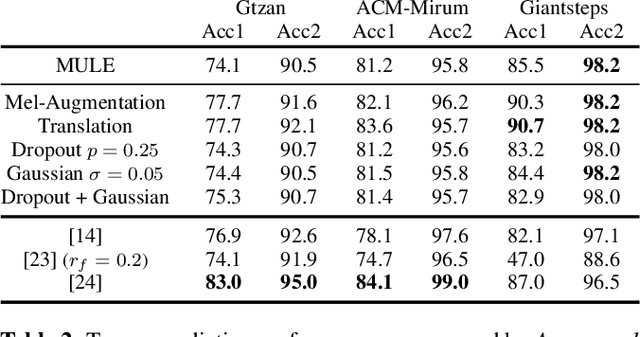
Audio embeddings enable large scale comparisons of the similarity of audio files for applications such as search and recommendation. Due to the subjectivity of audio similarity, it can be desirable to design systems that answer not only whether audio is similar, but similar in what way (e.g., wrt. tempo, mood or genre). Previous works have proposed disentangled embedding spaces where subspaces representing specific, yet possibly correlated, attributes can be weighted to emphasize those attributes in downstream tasks. However, no research has been conducted into the independence of these subspaces, nor their manipulation, in order to retrieve tracks that are similar but different in a specific way. Here, we explore the manipulation of tempo in embedding spaces as a case-study towards this goal. We propose tempo translation functions that allow for efficient manipulation of tempo within a pre-existing embedding space whilst maintaining other properties such as genre. As this translation is specific to tempo it enables retrieval of tracks that are similar but have specifically different tempi. We show that such a function can be used as an efficient data augmentation strategy for both training of downstream tempo predictors, and improved nearest neighbor retrieval of properties largely independent of tempo.
On the Effect of Data-Augmentation on Local Embedding Properties in the Contrastive Learning of Music Audio Representations
Jan 17, 2024



Audio embeddings are crucial tools in understanding large catalogs of music. Typically embeddings are evaluated on the basis of the performance they provide in a wide range of downstream tasks, however few studies have investigated the local properties of the embedding spaces themselves which are important in nearest neighbor algorithms, commonly used in music search and recommendation. In this work we show that when learning audio representations on music datasets via contrastive learning, musical properties that are typically homogeneous within a track (e.g., key and tempo) are reflected in the locality of neighborhoods in the resulting embedding space. By applying appropriate data augmentation strategies, localisation of such properties can not only be reduced but the localisation of other attributes is increased. For example, locality of features such as pitch and tempo that are less relevant to non-expert listeners, may be mitigated while improving the locality of more salient features such as genre and mood, achieving state-of-the-art performance in nearest neighbor retrieval accuracy. Similarly, we show that the optimal selection of data augmentation strategies for contrastive learning of music audio embeddings is dependent on the downstream task, highlighting this as an important embedding design decision.
Tempo estimation as fully self-supervised binary classification
Jan 17, 2024This paper addresses the problem of global tempo estimation in musical audio. Given that annotating tempo is time-consuming and requires certain musical expertise, few publicly available data sources exist to train machine learning models for this task. Towards alleviating this issue, we propose a fully self-supervised approach that does not rely on any human labeled data. Our method builds on the fact that generic (music) audio embeddings already encode a variety of properties, including information about tempo, making them easily adaptable for downstream tasks. While recent work in self-supervised tempo estimation aimed to learn a tempo specific representation that was subsequently used to train a supervised classifier, we reformulate the task into the binary classification problem of predicting whether a target track has the same or a different tempo compared to a reference. While the former still requires labeled training data for the final classification model, our approach uses arbitrary unlabeled music data in combination with time-stretching for model training as well as a small set of synthetically created reference samples for predicting the final tempo. Evaluation of our approach in comparison with the state-of-the-art reveals highly competitive performance when the constraint of finding the precise tempo octave is relaxed.