 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilar but Faster: Manipulation of Tempo in Music Audio Embeddings for Tempo Prediction and Search
Jan 17, 2024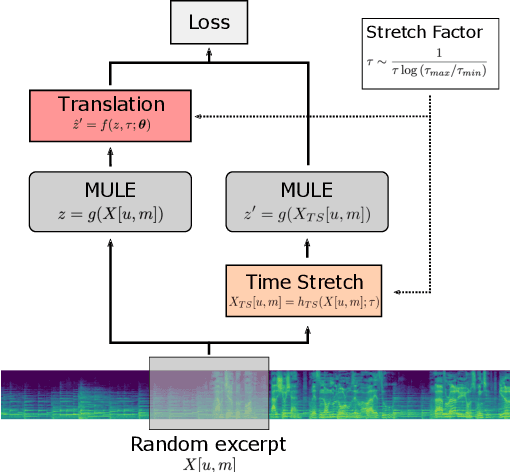
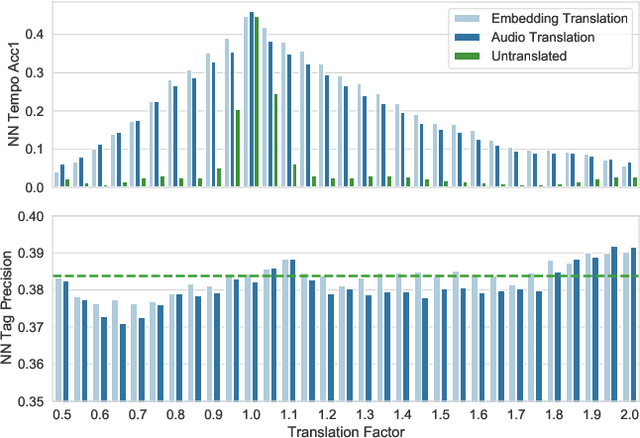
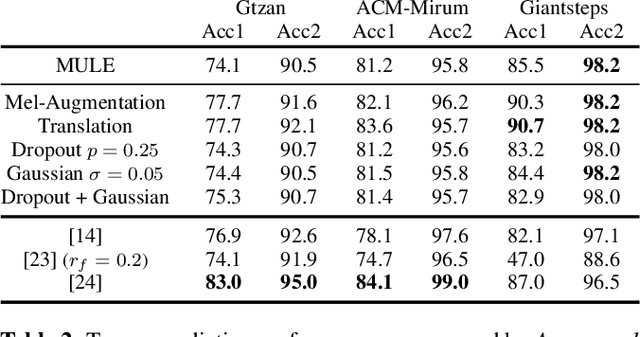
Audio embeddings enable large scale comparisons of the similarity of audio files for applications such as search and recommendation. Due to the subjectivity of audio similarity, it can be desirable to design systems that answer not only whether audio is similar, but similar in what way (e.g., wrt. tempo, mood or genre). Previous works have proposed disentangled embedding spaces where subspaces representing specific, yet possibly correlated, attributes can be weighted to emphasize those attributes in downstream tasks. However, no research has been conducted into the independence of these subspaces, nor their manipulation, in order to retrieve tracks that are similar but different in a specific way. Here, we explore the manipulation of tempo in embedding spaces as a case-study towards this goal. We propose tempo translation functions that allow for efficient manipulation of tempo within a pre-existing embedding space whilst maintaining other properties such as genre. As this translation is specific to tempo it enables retrieval of tracks that are similar but have specifically different tempi. We show that such a function can be used as an efficient data augmentation strategy for both training of downstream tempo predictors, and improved nearest neighbor retrieval of properties largely independent of tempo.
On the Effect of Data-Augmentation on Local Embedding Properties in the Contrastive Learning of Music Audio Representations
Jan 17, 2024



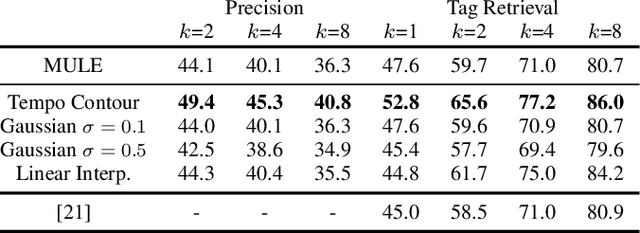
Audio embeddings are crucial tools in understanding large catalogs of music. Typically embeddings are evaluated on the basis of the performance they provide in a wide range of downstream tasks, however few studies have investigated the local properties of the embedding spaces themselves which are important in nearest neighbor algorithms, commonly used in music search and recommendation. In this work we show that when learning audio representations on music datasets via contrastive learning, musical properties that are typically homogeneous within a track (e.g., key and tempo) are reflected in the locality of neighborhoods in the resulting embedding space. By applying appropriate data augmentation strategies, localisation of such properties can not only be reduced but the localisation of other attributes is increased. For example, locality of features such as pitch and tempo that are less relevant to non-expert listeners, may be mitigated while improving the locality of more salient features such as genre and mood, achieving state-of-the-art performance in nearest neighbor retrieval accuracy. Similarly, we show that the optimal selection of data augmentation strategies for contrastive learning of music audio embeddings is dependent on the downstream task, highlighting this as an important embedding design decision.
Tempo estimation as fully self-supervised binary classification
Jan 17, 2024This paper addresses the problem of global tempo estimation in musical audio. Given that annotating tempo is time-consuming and requires certain musical expertise, few publicly available data sources exist to train machine learning models for this task. Towards alleviating this issue, we propose a fully self-supervised approach that does not rely on any human labeled data. Our method builds on the fact that generic (music) audio embeddings already encode a variety of properties, including information about tempo, making them easily adaptable for downstream tasks. While recent work in self-supervised tempo estimation aimed to learn a tempo specific representation that was subsequently used to train a supervised classifier, we reformulate the task into the binary classification problem of predicting whether a target track has the same or a different tempo compared to a reference. While the former still requires labeled training data for the final classification model, our approach uses arbitrary unlabeled music data in combination with time-stretching for model training as well as a small set of synthetically created reference samples for predicting the final tempo. Evaluation of our approach in comparison with the state-of-the-art reveals highly competitive performance when the constraint of finding the precise tempo octave is relaxed.
The ACCompanion: Combining Reactivity, Robustness, and Musical Expressivity in an Automatic Piano Accompanist
Apr 24, 2023This paper introduces the ACCompanion, an expressive accompaniment system. Similarly to a musician who accompanies a soloist playing a given musical piece, our system can produce a human-like rendition of the accompaniment part that follows the soloist's choices in terms of tempo, dynamics, and articulation. The ACCompanion works in the symbolic domain, i.e., it needs a musical instrument capable of producing and playing MIDI data, with explicitly encoded onset, offset, and pitch for each played note. We describe the components that go into such a system, from real-time score following and prediction to expressive performance generation and online adaptation to the expressive choices of the human player. Based on our experience with repeated live demonstrations in front of various audiences, we offer an analysis of the challenges of combining these components into a system that is highly reactive and precise, while still a reliable musical partner, robust to possible performance errors and responsive to expressive variations.
Fully Automatic Page Turning on Real Scores
Nov 12, 2021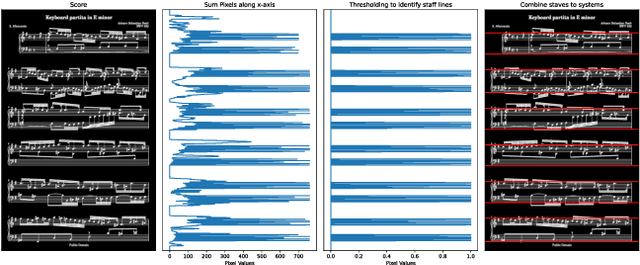

We present a prototype of an automatic page turning system that works directly on real scores, i.e., sheet images, without any symbolic representation. Our system is based on a multi-modal neural network architecture that observes a complete sheet image page as input, listens to an incoming musical performance, and predicts the corresponding position in the image. Using the position estimation of our system, we use a simple heuristic to trigger a page turning event once a certain location within the sheet image is reached. As a proof of concept we further combine our system with an actual machine that will physically turn the page on command.
Over-Parameterization and Generalization in Audio Classification
Jul 19, 2021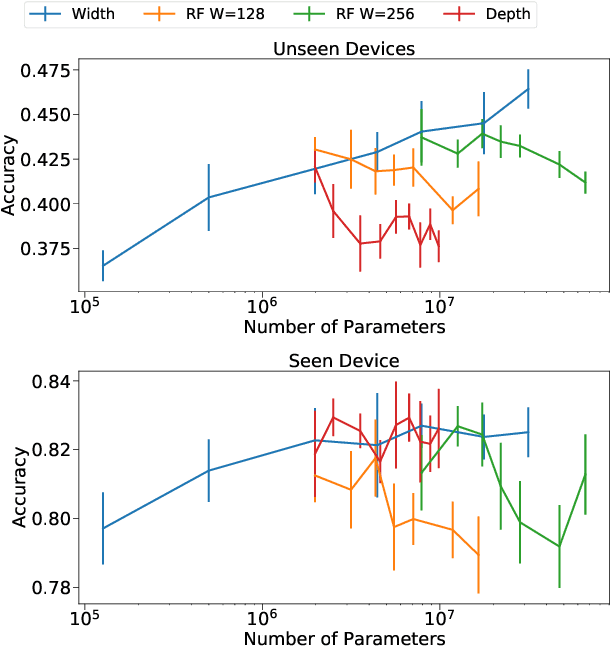
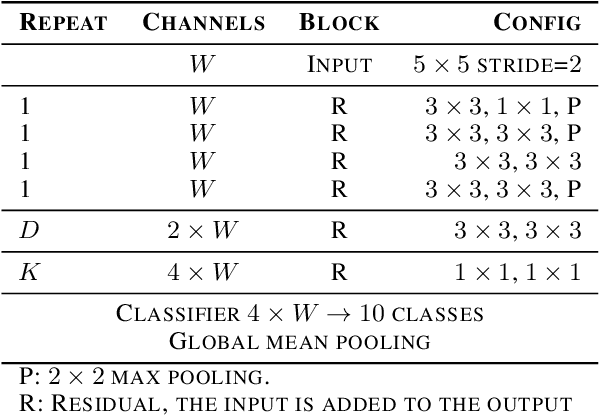
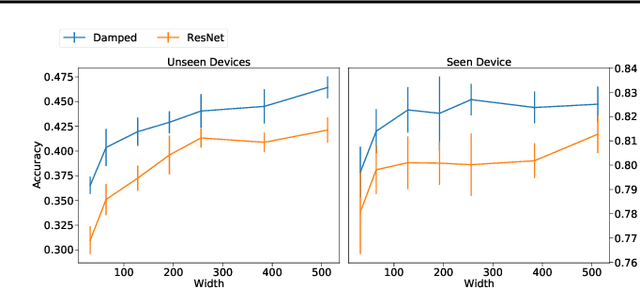
Convolutional Neural Networks (CNNs) have been dominating classification tasks in various domains, such as machine vision, machine listening, and natural language processing. In machine listening, while generally exhibiting very good generalization capabilities, CNNs are sensitive to the specific audio recording device used, which has been recognized as a substantial problem in the acoustic scene classification (DCASE) community. In this study, we investigate the relationship between over-parameterization of acoustic scene classification models, and their resulting generalization abilities. Specifically, we test scaling CNNs in width and depth, under different conditions. Our results indicate that increasing width improves generalization to unseen devices, even without an increase in the number of parameters.
Multi-modal Conditional Bounding Box Regression for Music Score Following
May 10, 2021
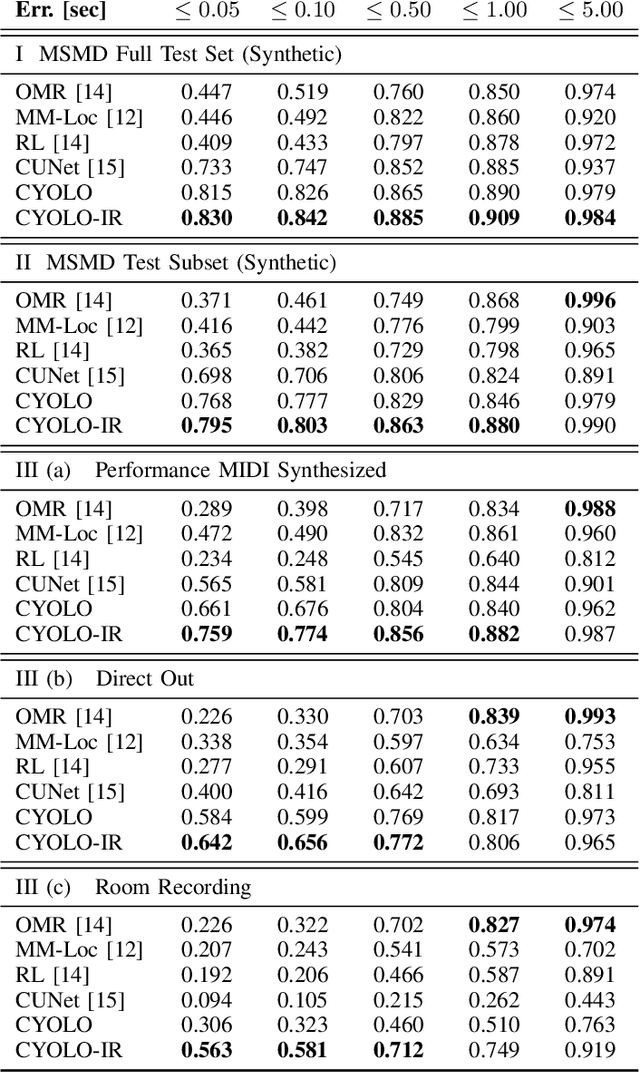
This paper addresses the problem of sheet-image-based on-line audio-to-score alignment also known as score following. Drawing inspiration from object detection, a conditional neural network architecture is proposed that directly predicts x,y coordinates of the matching positions in a complete score sheet image at each point in time for a given musical performance. Experiments are conducted on a synthetic polyphonic piano benchmark dataset and the new method is compared to several existing approaches from the literature for sheet-image-based score following as well as an Optical Music Recognition baseline. The proposed approach achieves new state-of-the-art results and furthermore significantly improves the alignment performance on a set of real-world piano recordings by applying Impulse Responses as a data augmentation technique.
Low-Complexity Models for Acoustic Scene Classification Based on Receptive Field Regularization and Frequency Damping
Nov 05, 2020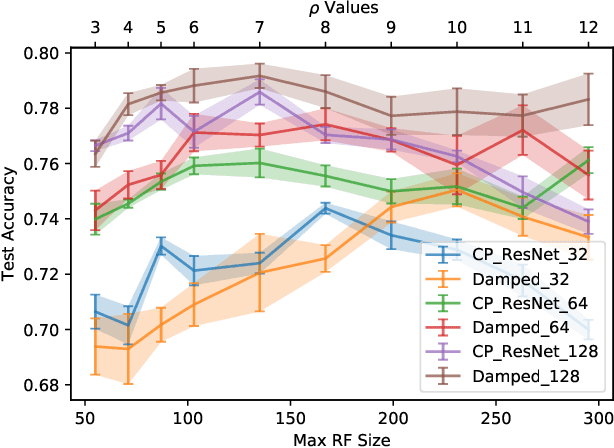
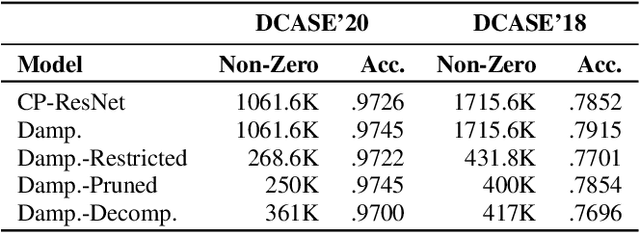
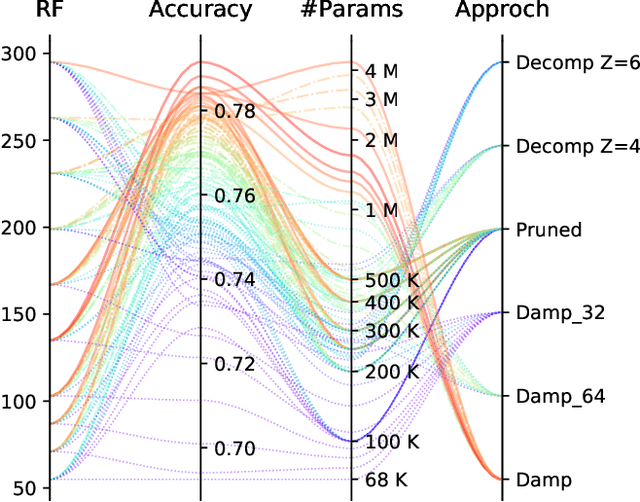
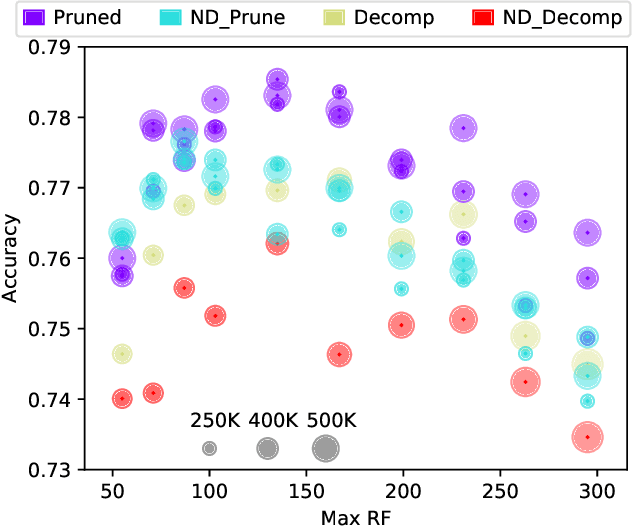
Deep Neural Networks are known to be very demanding in terms of computing and memory requirements. Due to the ever increasing use of embedded systems and mobile devices with a limited resource budget, designing low-complexity models without sacrificing too much of their predictive performance gained great importance. In this work, we investigate and compare several well-known methods to reduce the number of parameters in neural networks. We further put these into the context of a recent study on the effect of the Receptive Field (RF) on a model's performance, and empirically show that we can achieve high-performing low-complexity models by applying specific restrictions on the RFs, in combination with parameter reduction methods. Additionally, we propose a filter-damping technique for regularizing the RF of models, without altering their architecture and changing their parameter counts. We will show that incorporating this technique improves the performance in various low-complexity settings such as pruning and decomposed convolution. Using our proposed filter damping, we achieved the 1st rank at the DCASE-2020 Challenge in the task of Low-Complexity Acoustic Scene Classification.
Learning to Read and Follow Music in Complete Score Sheet Images
Jul 21, 2020

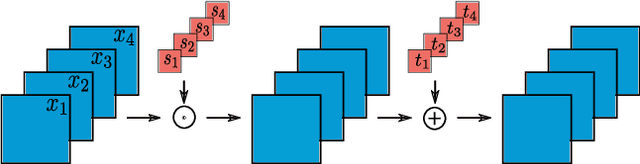
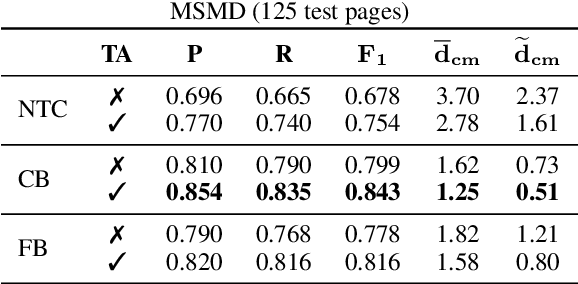
This paper addresses the task of score following in sheet music given as unprocessed images. While existing work either relies on OMR software to obtain a computer-readable score representation, or crucially relies on prepared sheet image excerpts, we propose the first system that directly performs score following in full-page, completely unprocessed sheet images. Based on incoming audio and a given image of the score, our system directly predicts the most likely position within the page that matches the audio, outperforming current state-of-the-art image-based score followers in terms of alignment precision. We also compare our method to an OMR-based approach and empirically show that it can be a viable alternative to such a system.
Audio-Conditioned U-Net for Position Estimation in Full Sheet Images
Oct 16, 2019


The goal of score following is to track a musical performance, usually in the form of audio, in a corresponding score representation. Established methods mainly rely on computer-readable scores in the form of MIDI or MusicXML and achieve robust and reliable tracking results. Recently, multimodal deep learning methods have been used to follow along musical performances in raw sheet images. Among the current limits of these systems is that they require a non trivial amount of preprocessing steps that unravel the raw sheet image into a single long system of staves. The current work is an attempt at removing this particular limitation. We propose an architecture capable of estimating matching score positions directly within entire unprocessed sheet images. We argue that this is a necessary first step towards a fully integrated score following system that does not rely on any preprocessing steps such as optical music recognition.